

Feature Imputation#
Michael J. Pyrcz, Professor, The University of Texas at Austin
Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Chapter of e-book “Applied Machine Learning in Python: a Hands-on Guide with Code”.
Cite this e-Book as:
Pyrcz, M.J., 2024, Applied Machine Learning in Python: A Hands-on Guide with Code [e-book]. Zenodo. doi:10.5281/zenodo.15169139 ![]()
The workflows in this book and more are available here:
Cite the MachineLearningDemos GitHub Repository as:
Pyrcz, M.J., 2024, MachineLearningDemos: Python Machine Learning Demonstration Workflows Repository (0.0.3) [Software]. Zenodo. DOI: 10.5281/zenodo.13835312. GitHub repository: GeostatsGuy/MachineLearningDemos ![]()
By Michael J. Pyrcz
© Copyright 2024.
This chapter is a tutorial for / demonstration of Feature Imputation.
YouTube Lecture: check out my lectures on:
Curse of Dimensionality, Dimensionality Reduction, Principal Component Analysis
Feature Imputation - To Be Recorded Soon
These lectures are all part of my Machine Learning Course on YouTube with linked well-documented Python workflows and interactive dashboards. My goal is to share accessible, actionable, and repeatable educational content. If you want to know about my motivation, check out Michael’s Story.
Motivation for Feature Imputation#
Most spatial, subsurface datasets are not complete, missing values from the database.
many data analytics and machine learning workflows require complete data, \(𝑥_(1,𝑖),\dots,𝑥_(𝑚,𝑖)\) for each of the data samples \(𝑖 = 1,\ldots,𝑛\).
Inferential Machine Learning - methods the require complete data, for example,
principal components analysis - require covariance matrix and covariance needs all feature values
multidimensional scaling - we cannot calculate the dissimilarity matrix without all features available
cluster analysis - we cannot calculate distances in feature space without all features values
Predictive Machine Learning - always require all features to train and test the model,
Dealing with missing data is an essential part of feature / data engineering, prerequisite for data analytics and machine learning.
it is important firstly to understand the cause and impact of the missing data.
Cause of Missing Feature Values#
Missing at random (MAR) is not common and is difficult to evaluated, in this case,
global random omission may not result in data bias and bias in the resulting models
MAR is not typically the case as missing data often is related to a confounding feature, for example,
sampling cost - for example, low permeability test takes too long
rock rheology or other sample survivorship biases - for example, not possible to recover the mudstone samples
sample design - sampling to reduce uncertainty and maximize profitability instead of statistical representativity, dual purpose samples for information and production
sampling accessibility - there are locations in the subsurface that are difficult or impossible to samples, for example, near lakes or communities, or subsalt for seismic imaging
Consequences of Missing Feature Values#
This will result in clustering of missing values over locations and feature space.
omission of these feature values may bias global statistics, and degrade accuracy of local predictions
the use of global distributions for imputing missing values may not be reasonable
More than reducing the amount of training and testing data, missing data, if not completely at random will result in:
Biased sample statistics resulting in biased model training and testing
Biased models with biased predictions with potentially no indication of the bias!
If you reread the above looking for solutions, I offer my Canadian, “I’m sorry”. Those who know us know that we say sorry a lot and have a cool pronunciation of the word.
I say all of the above as a cautionary note but,
in some cases there are gaps in practice due to our data challenges, i.e., data paucity and nonstationarity.
I could spend an entire course teaching methods to address these challenges
the solutions integrate the entire subsurface, spatial project team, i.e., domain expertise is critical
I’m going to leave this at the level of awareness
We must move beyond the commonly applied likewise deletion, removal of all samples with any missing features.
Load the Required Libraries#
The following code loads the required libraries.
These should have been installed with Anaconda 3.
ignore_warnings = True # ignore warnings?
import numpy as np # ndarrays for gridded data
import pandas as pd # DataFrames for tabular data
from sklearn.impute import SimpleImputer # basic imputation method
from sklearn.impute import KNNImputer # k-nearest neighbour imputation method
from sklearn.experimental import enable_iterative_imputer # required for MICE imputation
from sklearn.impute import IterativeImputer # MICE imputation
import os # set working directory, run executables
import math # basic math operations
import random # for random numbers
import matplotlib.pyplot as plt # for plotting
from matplotlib.ticker import (MultipleLocator, AutoMinorLocator) # control of axes ticks
from matplotlib.colors import ListedColormap # custom color maps
import matplotlib.ticker as mtick # control tick label formatting
import seaborn as sns # for matrix scatter plots
from scipy import stats # summary statistics
import numpy.linalg as linalg # for linear algebra
import scipy.spatial as sp # for fast nearest neighbor search
import scipy.signal as signal # kernel for moving window calculation
from numba import jit # for numerical speed up
from statsmodels.stats.weightstats import DescrStatsW
plt.rc('axes', axisbelow=True) # plot all grids below the plot elements
if ignore_warnings == True:
import warnings
warnings.filterwarnings('ignore')
cmap = plt.cm.inferno # color map
seed = 73071 # random seed
np.random.seed(seed=seed)
Declare Functions#
Here’s a function to assist with the plots:
add_grid - convenience function to add major and minor gridlines to improve plot interpretability
Here is the function:
def add_grid(): # add major and minor gridlines
plt.gca().grid(True, which='major',linewidth = 1.0); plt.gca().grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
Set the working directory#
I always like to do this so I don’t lose files and to simplify subsequent read and writes (avoid including the full address each time).
#os.chdir("c:/PGE383") # set the working directory
You will have to update the part in quotes with your own working directory and the format is different on a Mac (e.g. “~/PGE”).
Loading Tabular Data#
Here’s the command to load our comma delimited data file in to a Pandas’ DataFrame object.
Dataset 0, Unconventional Multivariate v4#
Let’s load the provided multivariate, dataset unconv_MV.csv. This dataset has variables from 1,000 unconventional wells including:
well average porosity
log transform of permeability (to linearize the relationships with other variables)
acoustic impedance (kg/m^3 x m/s x 10^6)
brittleness ratio (%)
total organic carbon (%)
vitrinite reflectance (%)
initial production 90 day average (MCFPD).
Dataset 1, Twelve, 12#
Let’s load the provided multivariate, 2D spatial dataset 12_sample_data.csv. This dataset has variables from 480 unconventional wells including:
X (m), Y (m) location coordinates
porosity (%) after units conversion
permeability (mD)
acoustic impedance (kg/m^3 x m/s x 10^6)
Dataset 2, Reservoir 21#
Let’s load the provided multivariate, 3D spatial dataset res21_wells.csv. This dataset has variables from 73 vertical wells over a 10,000m x 10,000m x 50 m reservoir unit:
well (ID)
X (m), Y (m), Depth (m) location coordinates
Porosity (%) after units conversion
Permeability (mD)
Acoustic Impedance (kg/m2s*10^6) after units conversion
Facies (categorical) - ordinal with ordering from Shale, Sandy Shale, Shaley Sand, to Sandstone.
Density (g/cm^3)
Compressible velocity (m/s)
Youngs modulus (GPa)
Shear velocity (m/s)
Shear modulus (GPa)
We load the tabular data with the pandas ‘read_csv’ function into a DataFrame we called ‘my_data’ and then preview it to make sure it loaded correctly.
we also populate lists with data ranges and labels for ease of plotting
idata = 0
if idata == 0:
df = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/unconv_MV_v4.csv') # load data from Dr. Pyrcz's GitHub repository
df.drop('Prod',axis=1,inplace=True)
features = df.columns.values.tolist() # store the names of the features
xmin = [6.0,0.0,1.0,10.0,0.0,0.9]; xmax = [24.0,10.0,5.0,85.0,2.2,2.9] # set the minimum and maximum values for plotting
flabel = ['Porosity (%)','Permeability (mD)','Acoustic Impedance (kg/m2s*10^6)','Brittleness Ratio (%)', # set the names for plotting
'Total Organic Carbon (%)','Vitrinite Reflectance (%)']
ftitle = ['Porosity','Permeability','Acoustic Impedance','Brittleness Ratio', # set the units for plotting
'Total Organic Carbon','Vitrinite Reflectance']
elif idata == 1:
names = {'Porosity':'Por'}
df = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/12_sample_data.csv') # load data from Dr. Pyrcz's GitHub repository
df = df.rename(columns=names)
df['Por'] = df['Por'] * 100.0; df['AI'] = df['AI'] / 1000.0;
df.drop('Unnamed: 0',axis=1,inplace=True)
features = df.columns.values.tolist() # store the names of the features
xmin = [0.0,0.0,0.0,4.0,0.0,6.5,1.4,1600.0,10.0,1300.0,1.6]; xmax = [10000.0,10000.0,1.0,19.0,500.0,8.3,3.6,6200.0,50.0,2000.0,12.0] # set the minimum and maximum values for plotting
flabel = ['Well (ID)','X (m)','Y (m)','Depth (m)','Porosity (fraction)','Permeability (mD)','Acoustic Impedance (kg/m2s*10^6)','Facies (categorical)',
'Density (g/cm^3)','Compressible velocity (m/s)','Youngs modulus (GPa)', 'Shear velocity (m/s)', 'Shear modulus (GPa)'] # set the names for plotting
ftitle = ['Well','X','Y','Depth','Porosity','Permeability','Acoustic Impedance','Facies',
'Density','Compressible velocity','Youngs modulus', 'Shear velocity', 'Shear modulus']
elif idata == 2:
df = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/res21_2D_wells.csv') # load data from Dr. Pyrcz's GitHub repository
features = df.columns.values.tolist() # store the names of the features
xmin = [1,0.0,0.0,4.0,0.0,6.5,1.4,1600.0,10.0,1300.0,1.6]; xmax = [73,10000.0,10000.0,19.0,500.0,8.3,3.6,6200.0,50.0,2000.0,12.0] # set the minimum and maximum values for plotting
flabel = ['Well (ID)','X (m)','Y (m)','Depth (m)','Porosity (fraction)','Permeability (mD)','Acoustic Impedance (kg/m2s*10^6)','Facies (categorical)',
'Density (g/cm^3)','Compressible velocity (m/s)','Youngs modulus (GPa)', 'Shear velocity (m/s)', 'Shear modulus (GPa)'] # set the names for plotting
ftitle = ['Well','X','Y','Depth','Porosity','Permeability','Acoustic Impedance','Facies',
'Density','Compressible velocity','Youngs modulus', 'Shear velocity', 'Shear modulus']
We can also establish the feature ranges for plotting. We could calculate the feature range directly from the data with code like this:
Pormin = np.min(df['Por'].values) # extract ndarray of data table column
Pormax = np.max(df['Por'].values) # and calculate min and max
but, this would not result in easy to understand color bars and axis scales, let’s pick convenient round numbers. We will also declare feature labels for ease of plotting.
Visualize the DataFrame#
Visualizing the DataFrame is useful first check of the data.
many things can go wrong, e.g., we loaded the wrong data, all the features did not load, etc.
We can preview by utilizing the ‘head’ DataFrame member function (with a nice and clean format, see below).
add parameter ‘n=13’ to see the first 13 rows of the dataset.
df.head(n=13) # DataFrame preview
| Well | Por | Perm | AI | Brittle | TOC | VR | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 12.08 | 2.92 | 2.80 | 81.40 | 1.16 | 2.31 |
| 1 | 2 | 12.38 | 3.53 | 3.22 | 46.17 | 0.89 | 1.88 |
| 2 | 3 | 14.02 | 2.59 | 4.01 | 72.80 | 0.89 | 2.72 |
| 3 | 4 | 17.67 | 6.75 | 2.63 | 39.81 | 1.08 | 1.88 |
| 4 | 5 | 17.52 | 4.57 | 3.18 | 10.94 | 1.51 | 1.90 |
| 5 | 6 | 14.53 | 4.81 | 2.69 | 53.60 | 0.94 | 1.67 |
| 6 | 7 | 13.49 | 3.60 | 2.93 | 63.71 | 0.80 | 1.85 |
| 7 | 8 | 11.58 | 3.03 | 3.25 | 53.00 | 0.69 | 1.93 |
| 8 | 9 | 12.52 | 2.72 | 2.43 | 65.77 | 0.95 | 1.98 |
| 9 | 10 | 13.25 | 3.94 | 3.71 | 66.20 | 1.14 | 2.65 |
| 10 | 11 | 15.04 | 4.39 | 2.22 | 61.11 | 1.08 | 1.77 |
| 11 | 12 | 16.19 | 6.30 | 2.29 | 49.10 | 1.53 | 1.86 |
| 12 | 13 | 16.82 | 5.42 | 2.80 | 66.65 | 1.17 | 1.98 |
Note, the first dataset idata = 0, is exhaustic without missing data, if you selected that one, let’s remove some data for the demonstrations below.
Remove Some Data#
Let’s select a proportion of NaN values, values to set as missing,
proportion_NaN = 0.1
Then we can make a boolean array
make an ndarray of same shape (number rows and columns) as the DataFrame of uniform[0,1] distributed values
np.random.random(df.shape)
check condition of less than the identified proportion to make a boolean ndarray of same size, true if less than the proportion. The result will be the correct proportion (within error) of random true values.
remove = np.random.random(df.shape) < proportion_NaN
apply the mask to remove the identified values from the DataFrame
df_mask = df.mask(remove)
Full disclosure, for this demonstration our data is missing at random, MAR, and this simplifies our task.
this allows us to focus on the mechanics of feature imputation without the additional domain expertise topics. This is a good first step!
if idata == 0 or idata == 1:
proportion_NaN = 0.1 # proportion of values in DataFrame to remove
np.random.seed(seed=seed) # ensure repeatability
remove = np.random.random(df.shape) < proportion_NaN # make the boolean array for removal
if idata == 1:
remove[:,df.columns.get_loc('Facies')] = False # avoid categoical imputation at this time
print('Fraction of removed values in mask ndarray = ' + str(round(remove.sum()/remove.size,3)) + '.')
df_mask = df.mask(remove)
else:
df_mask = df.copy(deep = True)
print('Fraction of nan values in the DataFrame = ' + str(round(df_mask.isnull().sum().sum()/(df_mask.shape[0]*df_mask.shape[1]),3)) + '.')
Fraction of removed values in mask ndarray = 0.093.
Fraction of nan values in the DataFrame = 0.093.
We now have a new DataFrame with some missing data.
Let’s do a .head() preview to observe the NaN values scattered throughout the dataset
df_mask.head(n=13) # DataFrame preview
| Well | Por | Perm | AI | Brittle | TOC | VR | |
|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 12.08 | 2.92 | 2.80 | 81.40 | 1.16 | 2.31 |
| 1 | 2.0 | 12.38 | 3.53 | NaN | 46.17 | 0.89 | 1.88 |
| 2 | NaN | 14.02 | 2.59 | 4.01 | 72.80 | 0.89 | 2.72 |
| 3 | 4.0 | 17.67 | 6.75 | 2.63 | 39.81 | 1.08 | 1.88 |
| 4 | 5.0 | 17.52 | 4.57 | 3.18 | 10.94 | 1.51 | 1.90 |
| 5 | 6.0 | 14.53 | 4.81 | 2.69 | 53.60 | 0.94 | 1.67 |
| 6 | 7.0 | 13.49 | 3.60 | NaN | 63.71 | 0.80 | 1.85 |
| 7 | 8.0 | 11.58 | 3.03 | NaN | 53.00 | 0.69 | 1.93 |
| 8 | 9.0 | NaN | 2.72 | NaN | 65.77 | 0.95 | 1.98 |
| 9 | 10.0 | NaN | 3.94 | 3.71 | 66.20 | 1.14 | 2.65 |
| 10 | 11.0 | 15.04 | 4.39 | 2.22 | NaN | 1.08 | 1.77 |
| 11 | NaN | 16.19 | 6.30 | 2.29 | 49.10 | 1.53 | 1.86 |
| 12 | 13.0 | NaN | 5.42 | 2.80 | 66.65 | 1.17 | 1.98 |
Evaluation of the Data Coverage#
Let’s calculate the amount of missing data.
df_mask.describe().transpose() # DataFrame summary statistics
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Well | 182.0 | 102.653846 | 58.078019 | 1.00 | 53.2500 | 104.000 | 153.7500 | 200.00 |
| Por | 184.0 | 14.935978 | 3.002142 | 6.55 | 12.8900 | 15.055 | 17.4225 | 23.55 |
| Perm | 172.0 | 4.319419 | 1.684672 | 1.13 | 3.1300 | 4.010 | 5.1850 | 9.78 |
| AI | 184.0 | 2.991630 | 0.571569 | 1.28 | 2.5675 | 2.975 | 3.3950 | 4.63 |
| Brittle | 186.0 | 47.793817 | 13.781815 | 10.94 | 37.7450 | 48.830 | 58.0150 | 81.40 |
| TOC | 186.0 | 0.991882 | 0.481896 | -0.19 | 0.6225 | 1.020 | 1.3500 | 2.18 |
| VR | 176.0 | 1.969602 | 0.293877 | 0.93 | 1.7775 | 1.970 | 2.1100 | 2.87 |
We can see the counts of available values for each feature, less than the total number of samples due to missing values.
Let’s make a plot to indicate data completeness for each feature
this is a useful summarization
plt.subplot(111) # data completeness plot
(df_mask.isnull().sum()/len(df)).plot(kind = 'bar',color='darkorange',edgecolor='black')
plt.xlabel('Feature'); plt.ylabel('Percentage of Missing Values'); plt.title('Data Completeness'); plt.ylim([0.0,1.0])
plt.plot([-0.5,df.shape[1]+0.5],[0.1,0.1],color='red',ls='--')
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=0.8, wspace=0.2, hspace=0.2); add_grid(); plt.show()
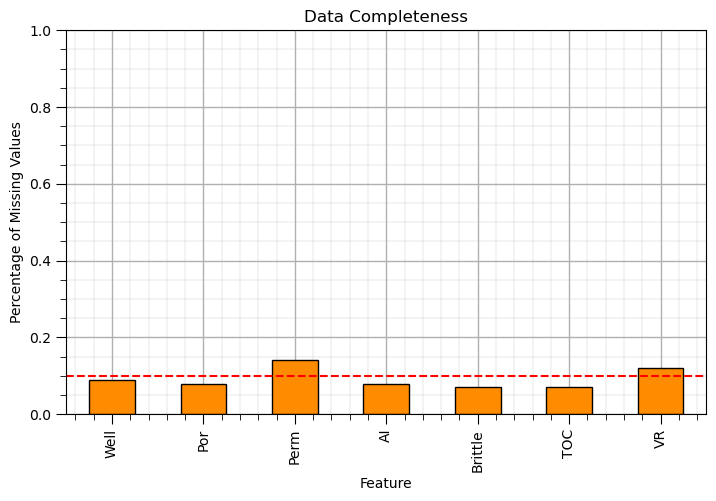
This leads to the first data imputation method, feature selection.
Imputation Method #1 - Feature Selection#
Data completeness should be considered in feature selection.
if there is low data completeness, high percentage of missing samples, for a feature then the feature may be removed.
One method is to use the .drop() DataFrame function.
df_test = df_mask.drop('VR',axis = 1)
We use axis = 1 to drop a feature (as above) to remove features with more than 10% of feature values missing.
if idata == 0:
drop_features = ['Perm','VR']
elif idata == 1:
drop_features = []
elif idata == 2:
drop_features = ['Youngs','Shear']
df_test = df_mask.drop(drop_features,axis = 1)
plt.subplot(111)
(df_test.isnull().sum()/len(df)).plot(kind = 'bar',color='darkorange',edgecolor='black') # calculate DataFrame with percentage missing by feature
plt.xlabel('Feature'); plt.ylabel('Percentage of Missing Values'); plt.title('Data Completeness'); plt.ylim([0.0,1.0])
plt.plot([-0.5,df.shape[1]+0.5],[0.1,0.1],color='red',ls='--')
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=0.8, wspace=0.2, hspace=0.2); add_grid(); plt.show()
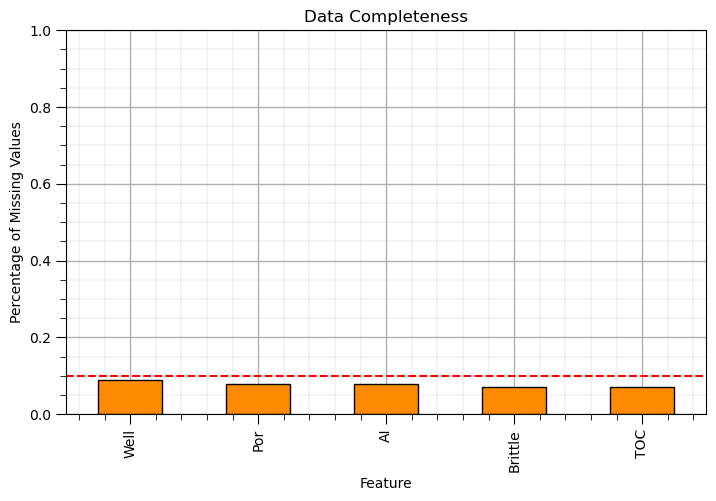
Imputation Method #2 - Sample Selection#
There may be samples with more missing feature values.
a specific vintage of data, for example, older data, or sample locations that experienced data collection problems
Let’s check the coverage by sample in the DataFrame.
we use the axis=1 parameter in the sum command to sum NaN values over the rows, samples, of the DataFrame.
(df_mask.isnull().sum(axis=1)/len(df.columns)).plot(kind = 'bar',color='darkorange',edgecolor='black')
plt.subplots_adjust(left=0.0, bottom=0.0, right=3.2, top=1.2, wspace=0.2, hspace=0.2) # plot formatting
plt.xlabel('Sample Index'); plt.ylabel('Percentage of Missing Records'); plt.title('Data Completeness')
plt.xticks(np.arange(0,len(df_mask),10),np.arange(0,len(df_mask),10))
plt.ylim([0,1.0])
plt.plot([-0.5,len(df)+0.5],[0.2,0.2],color='red',ls='--')
plt.subplots_adjust(left=0.0, bottom=0.0, right=3.0, top=0.8, wspace=0.2, hspace=0.2); add_grid(); plt.show()
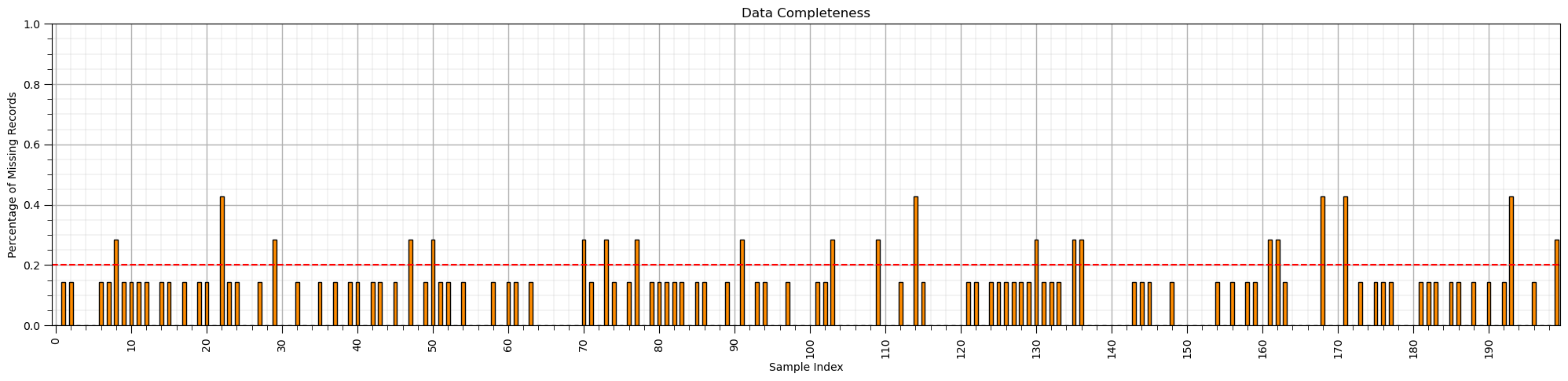
If we identified samples with low data completeness, high percentage of missing samples, for a sample then the sample may be removed.
Once again we use the .drop() DataFrame function.
df_test = df_mask.drop('Water',axis = 1)
This time we use axis = 0 to drop a list of samples and demonstrated below.
We need to make a list of the sample indices with too many missing samples
(df_mask.isnull().sum(axis=1)/len(df.columns)) > max_proportion_missing_by_sample
This is a tuple type, let’s convert it to a ndarray then we ensure strip it to just the 1D values
index_low_coverage_samples = np.asarray(np.where(low_coverage_samples == True))[0]
Now we are ready to apply our boolean array of length number of samples with True for too many missing values to remove these samples by index.
df_test2 = df_mask.drop(index = index_low_coverage_samples,axis = 0)
max_proportion_missing_by_sample = 0.2
low_coverage_samples = (df_mask.isnull().sum(axis=1)/len(df.columns)) > max_proportion_missing_by_sample
index_low_coverage_samples = np.asarray(np.where(low_coverage_samples == True))[0]
df_test2 = df_mask.drop(index = index_low_coverage_samples,axis = 0)
(df_test2.isnull().sum(axis=1)/len(df_test2.columns)).plot(kind = 'bar',color='darkorange',edgecolor='black')
plt.subplots_adjust(left=0.0, bottom=0.0, right=3.2, top=1.2, wspace=0.2, hspace=0.2) # plot formatting
plt.xlabel('Updated Sample Index'); plt.ylabel('Percentage of Missing Records'); plt.title('Data Completeness')
plt.xticks(np.arange(0,len(df_mask),10),np.arange(0,len(df_mask),10))
plt.ylim([0,1.0])
plt.plot([-0.5,len(df)+0.5],[0.2,0.2],color='red',ls='--')
plt.subplots_adjust(left=0.0, bottom=0.0, right=3.0, top=0.8, wspace=0.2, hspace=0.2); add_grid(); plt.show()
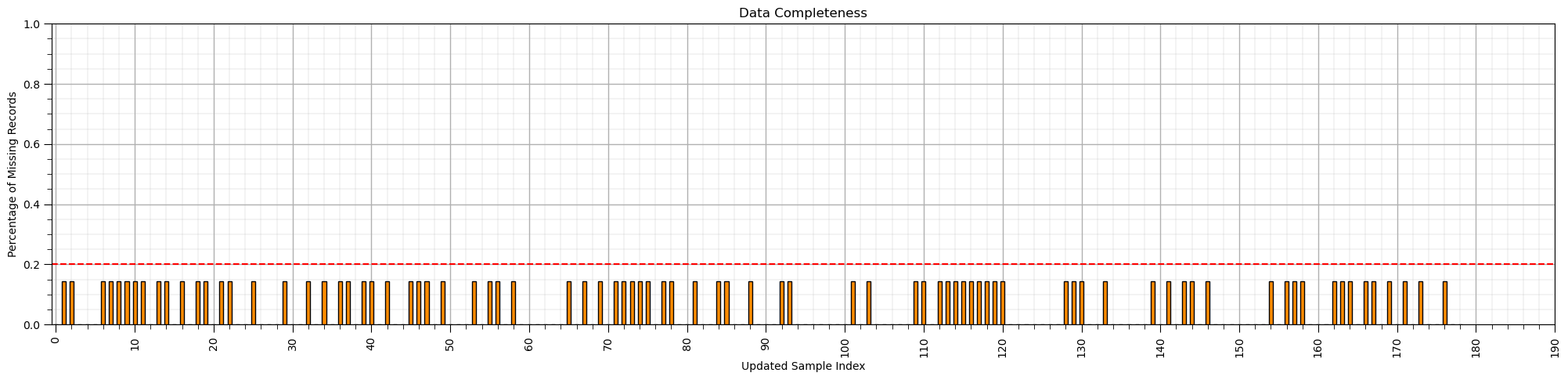
Imputation Method #3 - Listwise Deletion#
This is the method of removing all samples that have any missing feature values.
this approach ensures complete data while technically avoiding the need for imputation
no need for a imputation model decision
often removes important information
maximizes data bias if information is not missing at random (MAR)
We must consider data completeness, coverage for each feature, as visualized above. Consider that,
missing records in one feature may be different than the missing features in another feature
the union of missing over all features, may result in loss of much more than the largest proportion of missing over the features
Also, if missing not at random (MNAR), the sample bias is maximized
while likewise deletion is often applied, it is not recommended.
We can use the dropna() function.
with subset we can only consider a list of features
how can be set to ‘any’ for drop if any missing values and ‘all’ drop if all are missing
inplace true will overwrite the DataFrame and has no output while false will pass the new dataframe as a copy
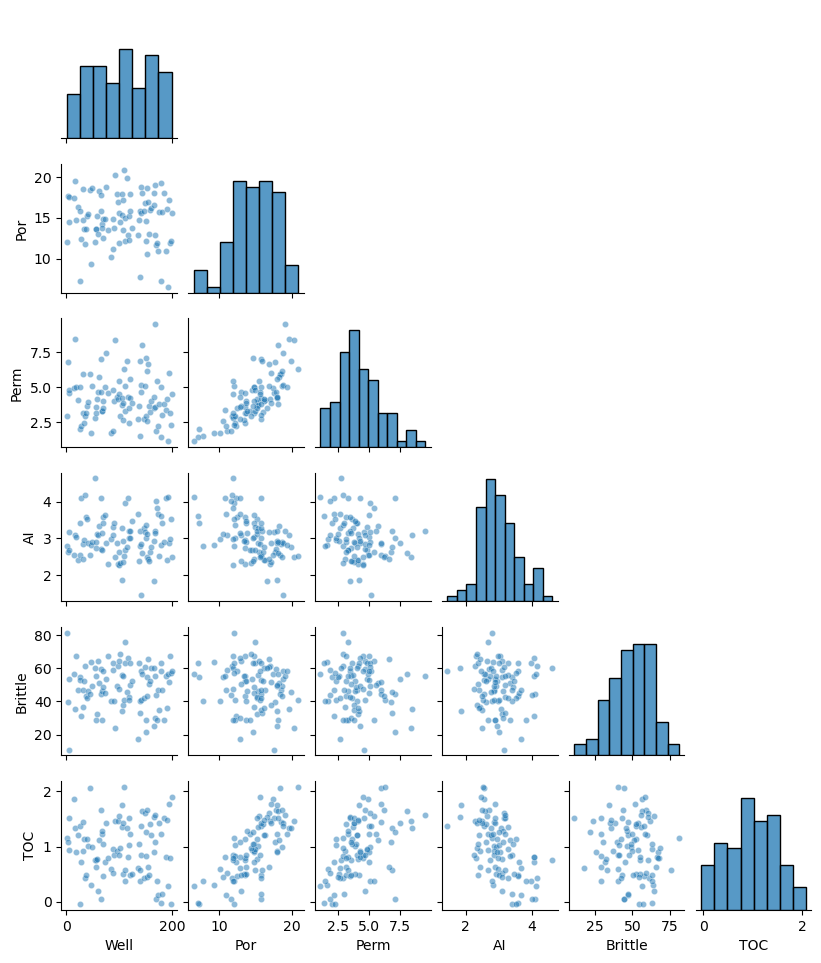
df_listwise = df_mask.dropna(how='any',inplace=False)
sns.pairplot(df_listwise.iloc[:,:-1], plot_kws={'alpha':0.5,'s':20},corner=True)
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.5, top=0.6, wspace=0.1, hspace=0.2)
# df_likewise.head(n = 13)
Modeling Methods for Imputation#
These are methods for feature imputation that treat feature imputation as a prediction problem, i.e., predict missing feature value with other available data, for example,
the collocated other available feature values
the same feature values available at other sample locations
There are many prediction methods applied for feature imputation,
we start with the most simple prediction model possible, predicting with the global mean and proceed from there to more complicated models
To help us visualize the results, let’s add a feature indicating if there are any missing feature values for a specific sample
this way we can label the samples that have had features imputed for evaluation and visualization of the feature imputation results
df_mask['Imputed'] = (df_mask.isnull().sum(axis=1)) > 0
df_mask.head()
| Well | Por | Perm | AI | Brittle | TOC | VR | Imputed | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 12.08 | 2.92 | 2.80 | 81.40 | 1.16 | 2.31 | False |
| 1 | 2.0 | 12.38 | 3.53 | NaN | 46.17 | 0.89 | 1.88 | True |
| 2 | NaN | 14.02 | 2.59 | 4.01 | 72.80 | 0.89 | 2.72 | True |
| 3 | 4.0 | 17.67 | 6.75 | 2.63 | 39.81 | 1.08 | 1.88 | False |
| 4 | 5.0 | 17.52 | 4.57 | 3.18 | 10.94 | 1.51 | 1.90 | False |
Imputation Method #4 - Replace with a Constant#
This is the method of replacing the missing values with a constant value.
here’s an example of replacing the missing feature values with a very low value
This results in bias and should not be done.
df_constant = df_mask.copy(deep=True) # make a deep copy of the DataFrame
constant_imputer = SimpleImputer(strategy='constant',fill_value = 0.01)
df_constant.iloc[:,:] = constant_imputer.fit_transform(df_constant)
sns.pairplot(df_constant.iloc[:,:], hue="Imputed", plot_kws={'alpha':0.15,'s':20}, palette = 'gnuplot', corner=True)
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.5, top=0.6, wspace=0.1, hspace=0.2)
df_constant.head(n=5)
| Well | Por | Perm | AI | Brittle | TOC | VR | Imputed | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.00 | 12.08 | 2.92 | 2.80 | 81.40 | 1.16 | 2.31 | 0.0 |
| 1 | 2.00 | 12.38 | 3.53 | 0.01 | 46.17 | 0.89 | 1.88 | 1.0 |
| 2 | 0.01 | 14.02 | 2.59 | 4.01 | 72.80 | 0.89 | 2.72 | 1.0 |
| 3 | 4.00 | 17.67 | 6.75 | 2.63 | 39.81 | 1.08 | 1.88 | 0.0 |
| 4 | 5.00 | 17.52 | 4.57 | 3.18 | 10.94 | 1.51 | 1.90 | 0.0 |
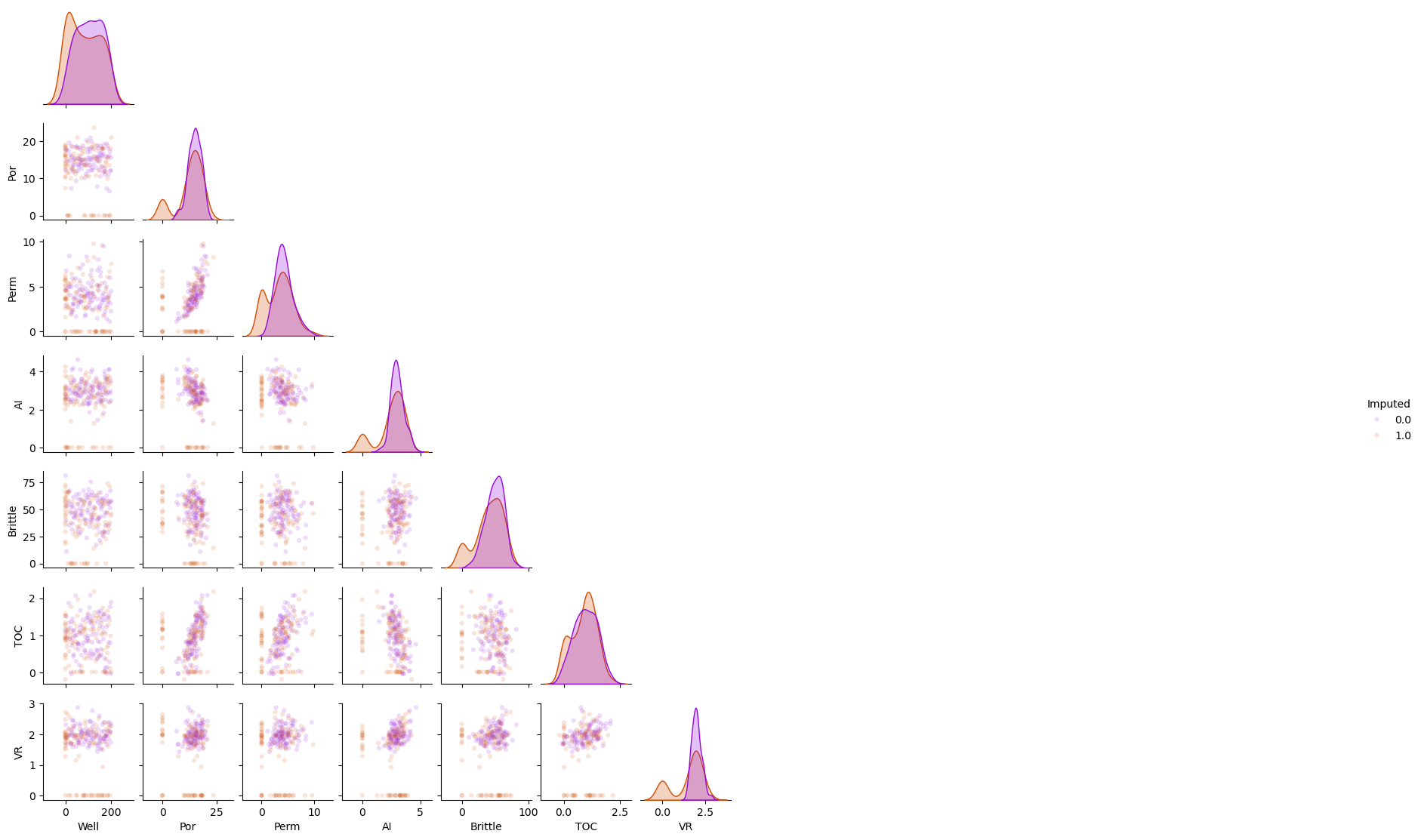
Imputation Method #6 - Replace with the Mean#
This is the method of replacing the missing values with the mean, arithmetic average, over the feature.
the global mean is globally unbiased, but may result in local bias, i.e., low values are overestimated and high values are underestimated
df_mean = df_mask.copy(deep=True) # make a deep copy of the DataFrame
mean_imputer = SimpleImputer(strategy='mean')
df_mean.iloc[:,:] = mean_imputer.fit_transform(df_mean)
sns.pairplot(df_mean.iloc[:,:], hue="Imputed", plot_kws={'alpha':0.15,'s':20}, palette = 'gnuplot', corner=True)
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.5, top=0.6, wspace=0.1, hspace=0.2)
df_constant.head(n=5)
df_mean.head(n=5)
| Well | Por | Perm | AI | Brittle | TOC | VR | Imputed | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.000000 | 12.08 | 2.92 | 2.80000 | 81.40 | 1.16 | 2.31 | 0.0 |
| 1 | 2.000000 | 12.38 | 3.53 | 2.99163 | 46.17 | 0.89 | 1.88 | 1.0 |
| 2 | 102.653846 | 14.02 | 2.59 | 4.01000 | 72.80 | 0.89 | 2.72 | 1.0 |
| 3 | 4.000000 | 17.67 | 6.75 | 2.63000 | 39.81 | 1.08 | 1.88 | 0.0 |
| 4 | 5.000000 | 17.52 | 4.57 | 3.18000 | 10.94 | 1.51 | 1.90 | 0.0 |
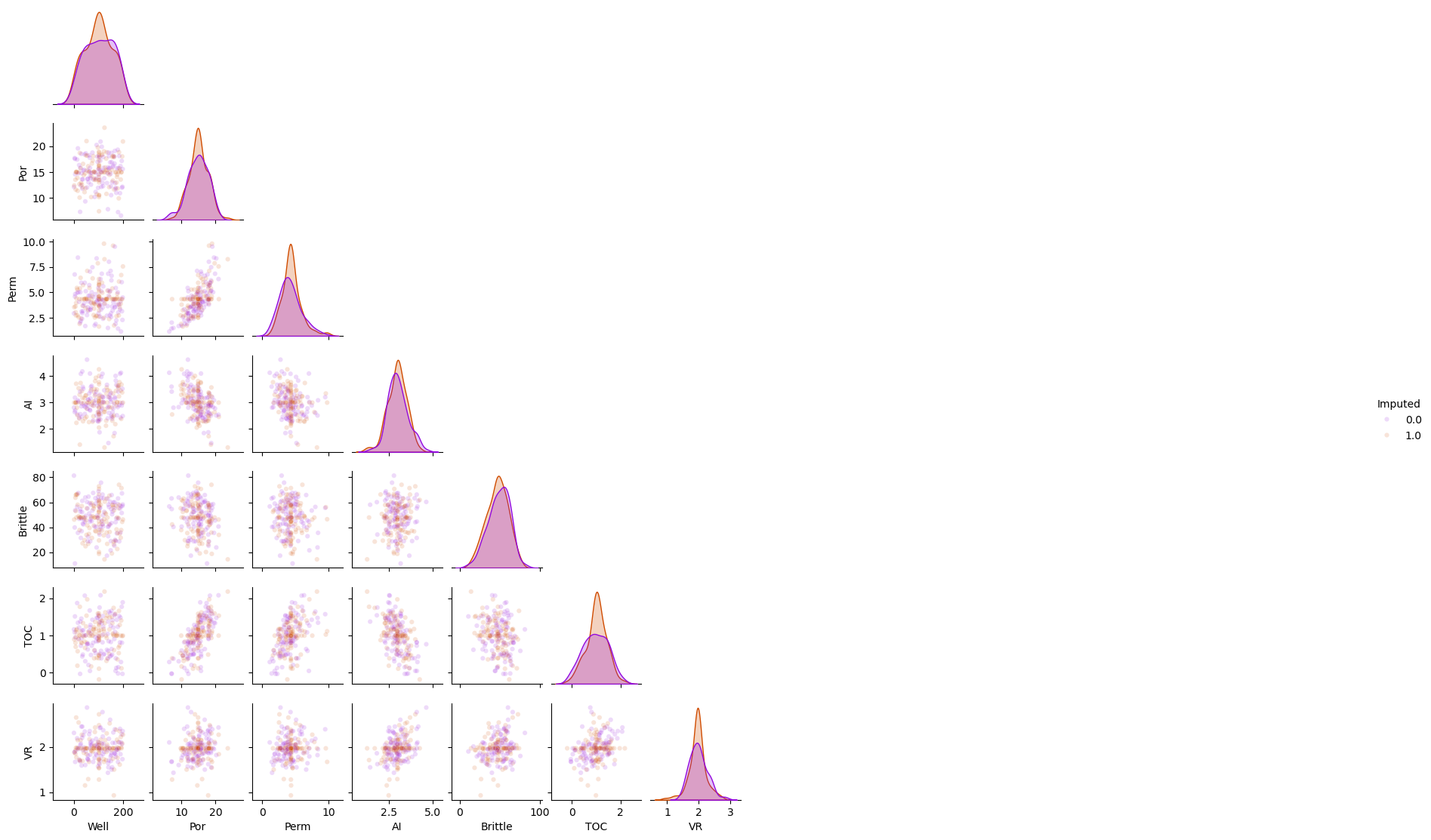
Imputation Method #6 - Replace with the Mode#
This is the method of replacing the missing values with the most frequent value, mode, over the feature.
in the presence of outliers the mean may not be reliable. My recommendation is to first deal with outliers prior to feature imputation
df_mode = df_mask.copy(deep=True) # make a deep copy of the DataFrame
mode_imputer = SimpleImputer(strategy='most_frequent')
df_mode.iloc[:,:] = mode_imputer.fit_transform(df_mode)
sns.pairplot(df_mode.iloc[:,:], hue="Imputed", plot_kws={'alpha':0.15,'s':20}, palette = 'gnuplot', corner=True)
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.5, top=0.6, wspace=0.1, hspace=0.2)
df_constant.head(n=5)
df_mode.head(n=5)
| Well | Por | Perm | AI | Brittle | TOC | VR | Imputed | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 12.08 | 2.92 | 2.80 | 81.40 | 1.16 | 2.31 | 0.0 |
| 1 | 2.0 | 12.38 | 3.53 | 2.45 | 46.17 | 0.89 | 1.88 | 1.0 |
| 2 | 1.0 | 14.02 | 2.59 | 4.01 | 72.80 | 0.89 | 2.72 | 1.0 |
| 3 | 4.0 | 17.67 | 6.75 | 2.63 | 39.81 | 1.08 | 1.88 | 0.0 |
| 4 | 5.0 | 17.52 | 4.57 | 3.18 | 10.94 | 1.51 | 1.90 | 0.0 |
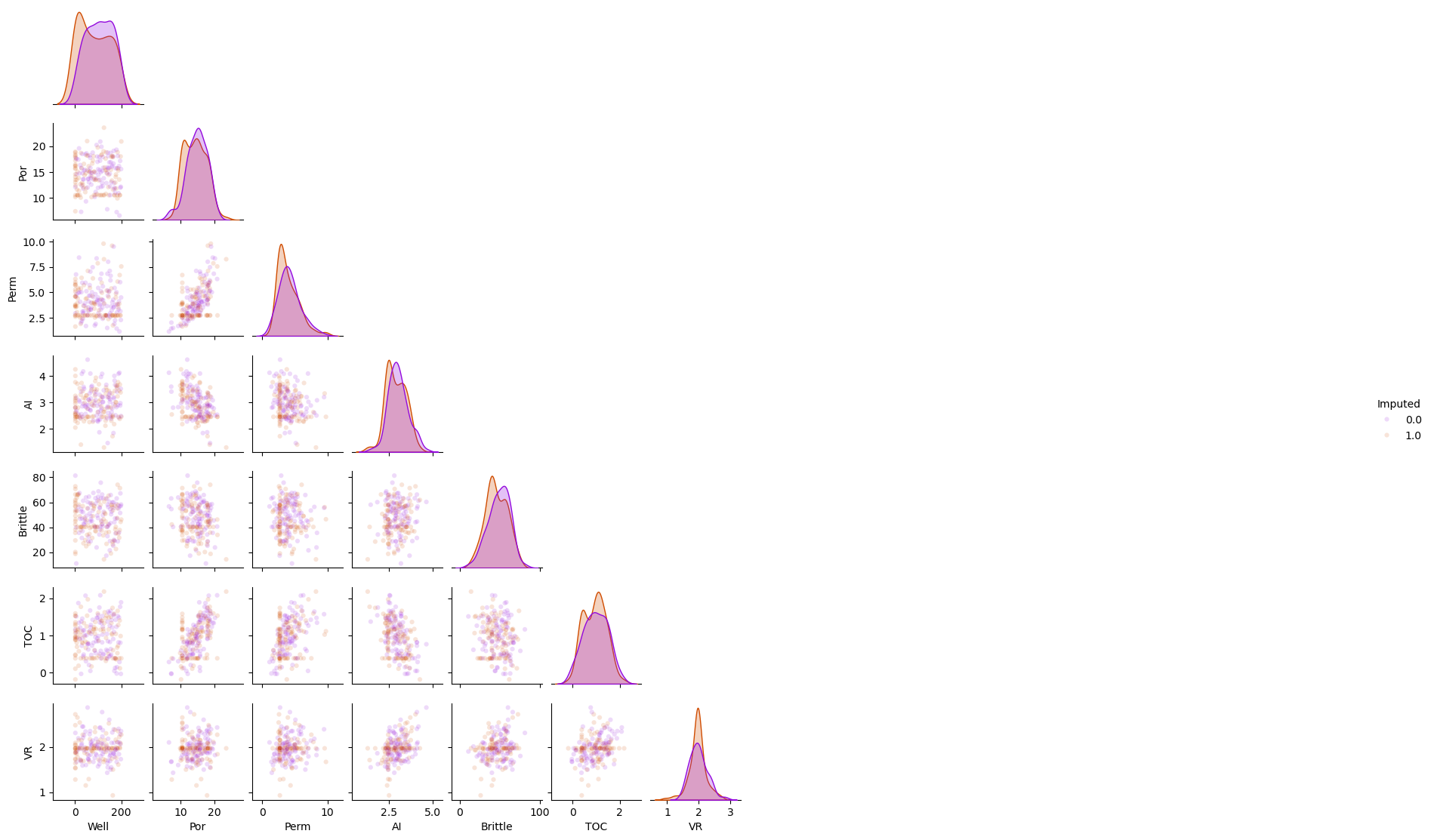
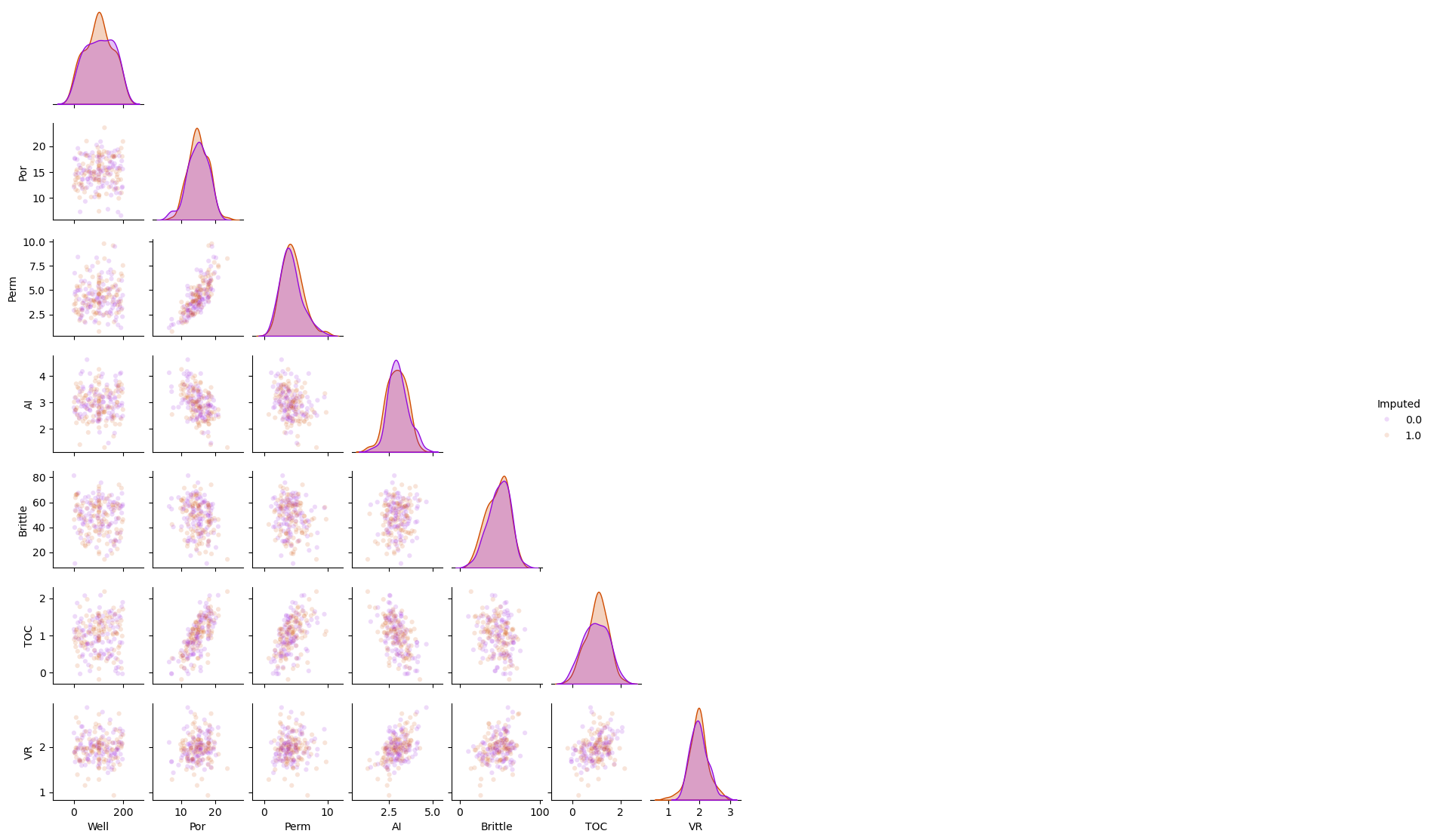
Imputation Method #7 - Replace with the n-nearest Neighbor estimation#
This is the method of replacing the missing values with the k-nearest neighbour prediction model based on the other available collocated feature values
see the k-nearest neighbour chapter in this e-book for explanation of the method, assumptions and hyperparameters
the available data is applied to predict at the missing values in features space
Since the k-nearest neighbor method is a lazy learner, imputed values are calculated in a single pass over the missing values
there is not a separate train and predict step
This method should be globally unbiased and will reduce local bias relative to global mean feature imputation
df_knn = df_mask.copy(deep=True) # make a deep copy of the DataFrame
knn_imputer = KNNImputer(n_neighbors=2, weights="uniform")
df_knn.iloc[:,:] = knn_imputer.fit_transform(df_knn)
sns.pairplot(df_knn.iloc[:,:], hue="Imputed", plot_kws={'alpha':0.15,'s':20}, palette = 'gnuplot', corner=True)
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.5, top=0.6, wspace=0.1, hspace=0.2)
df_constant.head(n=5)
df_mode.head(n=5)
| Well | Por | Perm | AI | Brittle | TOC | VR | Imputed | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 12.08 | 2.92 | 2.80 | 81.40 | 1.16 | 2.31 | 0.0 |
| 1 | 2.0 | 12.38 | 3.53 | 2.45 | 46.17 | 0.89 | 1.88 | 1.0 |
| 2 | 1.0 | 14.02 | 2.59 | 4.01 | 72.80 | 0.89 | 2.72 | 1.0 |
| 3 | 4.0 | 17.67 | 6.75 | 2.63 | 39.81 | 1.08 | 1.88 | 0.0 |
| 4 | 5.0 | 17.52 | 4.57 | 3.18 | 10.94 | 1.51 | 1.90 | 0.0 |
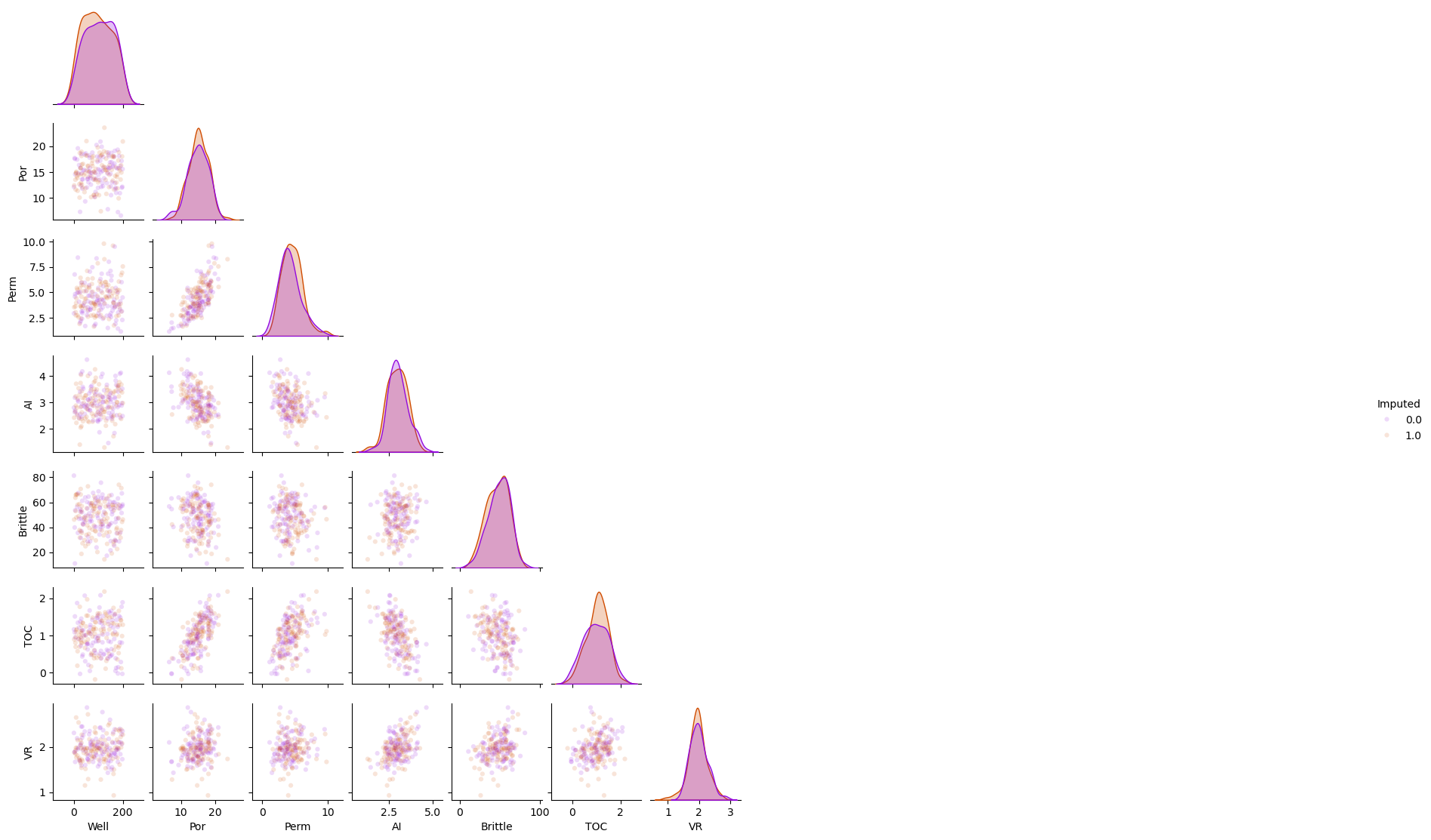
Imputation Method #8 - Multiple imputation by chained equations#
This is the method of replacing the missing values with the k-nearest neighbour prediction model
Substitute random values from \(𝐹_{𝑋_{𝑖=1,\ldots,𝑚}}(𝑋_{𝑖=1,\ldots,𝑚})\) for missing values
Sequentially predict missing values for a feature with others
Iterative until convergence criteria, usually multivariate statistics
Repeat for multiple realizations of the dataset
The default predictor is BayesianRidge().
we can specify the maximum number of iterations. The last computed imputations are returned.
df_mice = df_mask.copy(deep=True) # make a deep copy of the DataFrame
mice_imputer = IterativeImputer()
df_mice.iloc[:,:] = mice_imputer.fit_transform(df_mice)
sns.pairplot(df_mice.iloc[:,:], hue="Imputed", plot_kws={'alpha':0.15,'s':20}, palette = 'gnuplot', corner=True)
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.5, top=0.6, wspace=0.1, hspace=0.2)
df_constant.head(n=5)
df_mode.head(n=5)
| Well | Por | Perm | AI | Brittle | TOC | VR | Imputed | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 12.08 | 2.92 | 2.80 | 81.40 | 1.16 | 2.31 | 0.0 |
| 1 | 2.0 | 12.38 | 3.53 | 2.45 | 46.17 | 0.89 | 1.88 | 1.0 |
| 2 | 1.0 | 14.02 | 2.59 | 4.01 | 72.80 | 0.89 | 2.72 | 1.0 |
| 3 | 4.0 | 17.67 | 6.75 | 2.63 | 39.81 | 1.08 | 1.88 | 0.0 |
| 4 | 5.0 | 17.52 | 4.57 | 3.18 | 10.94 | 1.51 | 1.90 | 0.0 |
Save the Imputed DataFrame#
Write out the imputed data file.
save_imputed = False # save the imputed DataFrame?
if save_imputed == True:
df_imputed = df_knn.copy(deep = True) # select the imputation method
df_imputed.drop('Imputed',axis=1,inplace=True)
file_name = r'dataframe_imputed.csv'
df_imputed.to_csv(file_name, index=False)
About the Author#

Michael Pyrcz is a professor in the Cockrell School of Engineering, and the Jackson School of Geosciences, at The University of Texas at Austin, where he researches and teaches subsurface, spatial data analytics, geostatistics, and machine learning. Michael is also,
the principal investigator of the Energy Analytics freshmen research initiative and a core faculty in the Machine Learn Laboratory in the College of Natural Sciences, The University of Texas at Austin
an associate editor for Computers and Geosciences, and a board member for Mathematical Geosciences, the International Association for Mathematical Geosciences.
Michael has written over 70 peer-reviewed publications, a Python package for spatial data analytics, co-authored a textbook on spatial data analytics, Geostatistical Reservoir Modeling and author of two recently released e-books, Applied Geostatistics in Python: a Hands-on Guide with GeostatsPy and Applied Machine Learning in Python: a Hands-on Guide with Code.
All of Michael’s university lectures are available on his YouTube Channel with links to 100s of Python interactive dashboards and well-documented workflows in over 40 repositories on his GitHub account, to support any interested students and working professionals with evergreen content. To find out more about Michael’s work and shared educational resources visit his Website.
Want to Work Together?#
I hope this content is helpful to those that want to learn more about subsurface modeling, data analytics and machine learning. Students and working professionals are welcome to participate.
Want to invite me to visit your company for training, mentoring, project review, workflow design and / or consulting? I’d be happy to drop by and work with you!
Interested in partnering, supporting my graduate student research or my Subsurface Data Analytics and Machine Learning consortium (co-PI is Professor John Foster)? My research combines data analytics, stochastic modeling and machine learning theory with practice to develop novel methods and workflows to add value. We are solving challenging subsurface problems!
I can be reached at mpyrcz@austin.utexas.edu.
I’m always happy to discuss,
Michael
Michael Pyrcz, Ph.D., P.Eng. Professor, Cockrell School of Engineering and The Jackson School of Geosciences, The University of Texas at Austin
More Resources Available at: Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Comments#
This was a basic treatment of feature imputation. Much more could be done and discussed, I have many more resources. Check out my shared resource inventory and the YouTube lecture links at the start of this chapter with resource links in the videos’ descriptions.
I hope this is helpful,
Michael