

K-means Clustering#
Michael J. Pyrcz, Professor, The University of Texas at Austin
Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Chapter of e-book “Applied Machine Learning in Python: a Hands-on Guide with Code”.
Cite this e-Book as:
Pyrcz, M.J., 2024, Applied Machine Learning in Python: A Hands-on Guide with Code [e-book]. Zenodo. doi:10.5281/zenodo.15169138 ![]()
The workflows in this book and more are available here:
Cite the MachineLearningDemos GitHub Repository as:
Pyrcz, M.J., 2024, MachineLearningDemos: Python Machine Learning Demonstration Workflows Repository (0.0.3) [Software]. Zenodo. DOI: 10.5281/zenodo.13835312. GitHub repository: GeostatsGuy/MachineLearningDemos ![]()
By Michael J. Pyrcz
© Copyright 2024.
This chapter is a tutorial for / demonstration of K-means Clustering.
YouTube Lecture: check out my lectures on:
These lectures are all part of my Machine Learning Course on YouTube with linked well-documented Python workflows and interactive dashboards. My goal is to share accessible, actionable, and repeatable educational content. If you want to know about my motivation, check out Michael’s Story.
Motivation for Cluster Analysis#
Mixing distinct populations to train prediction models often reduces model accuracy.
clustering is an inferential machine learning method to automate the segmentation of the dataset into separate groups, known as clusters and specified by an integer index.
the computer does not provide meaning nor description of the groups, that is our job!
We need to learn and segment distinct populations to improve our prediction models,
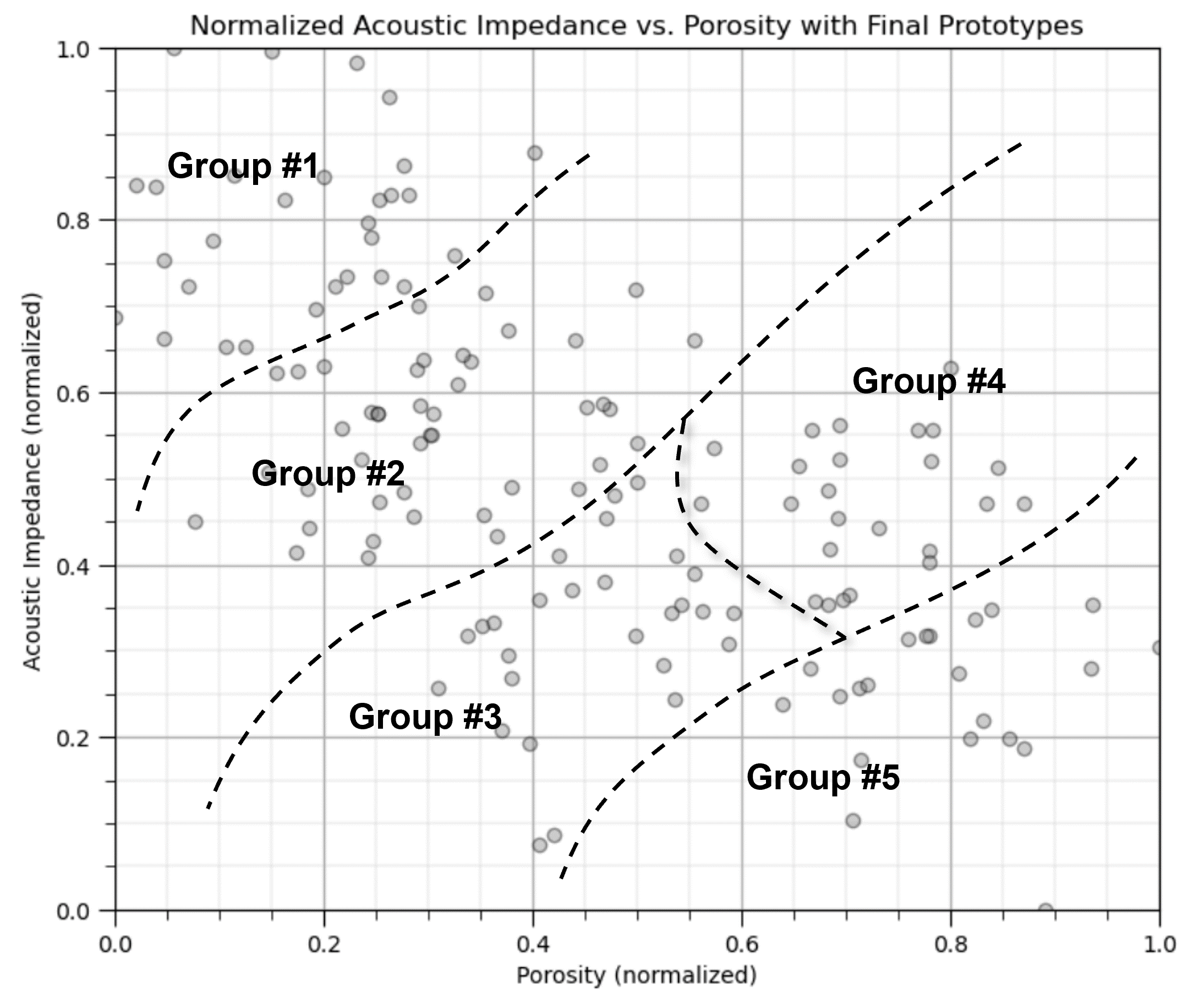
Yet, the above figure is misleading. If we calculate the boundaries as shown above, we would actually have a predictive classification model for the any new cases,
given normalized porosity of 0.7 and noramlized acoustic impedance of 0.18 classify as group #5
Clustering does not do this, it is an inferential, unsupervised machine learning method,
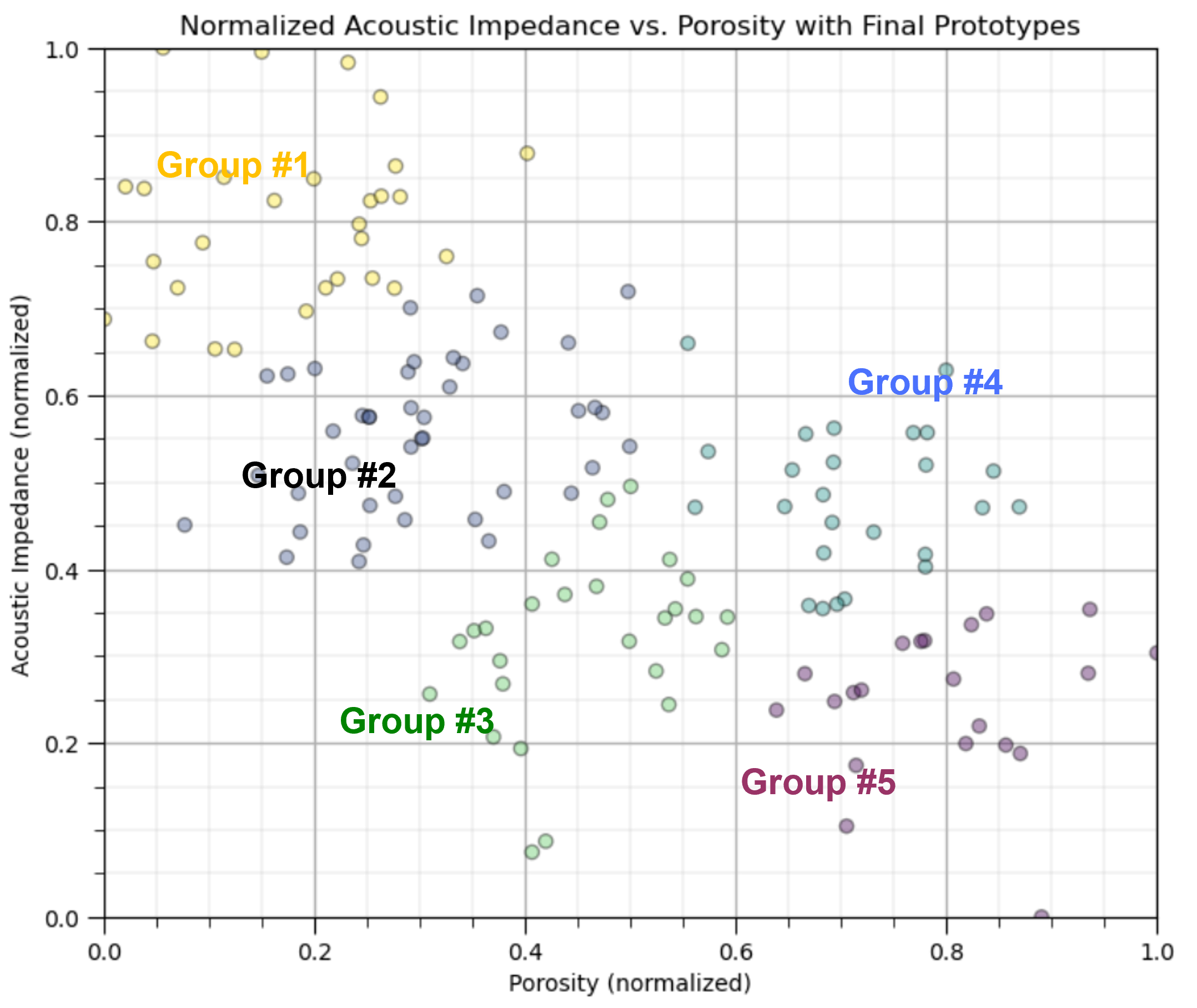
it is learning structures in the data
clustering assigns labels to the data
Inferential Machine Learning#
There are no response features, \(y\), just predictor features,
Machine learns by mimicry a compact representation of the data
Captures patterns as feature projections, group assignments, neural network latent features, etc.
We focus on inference of the population, the natural system, instead of prediction of response features.
K-Means Clustering#
The K-means clustering approach is primarily applied as an unsupervised machine learning method for clustering, group assignment to unlabeled data, where dissimilarity within clustered groups is minimized. The loss function that is minimized for K-means clustering, known as intertia, is,
where \(i\) is the cluster index, \(\alpha\) is the data sample index, \(X\) is the data sample and \(\mu_i\) is the \(i\) cluster prototype, \(k\) is the total number of clusters, and \(|| X_m - \mu_m ||\) is the Euclidean distance from a sample to the cluster prototype in \(M\) dimensional space calculated as:
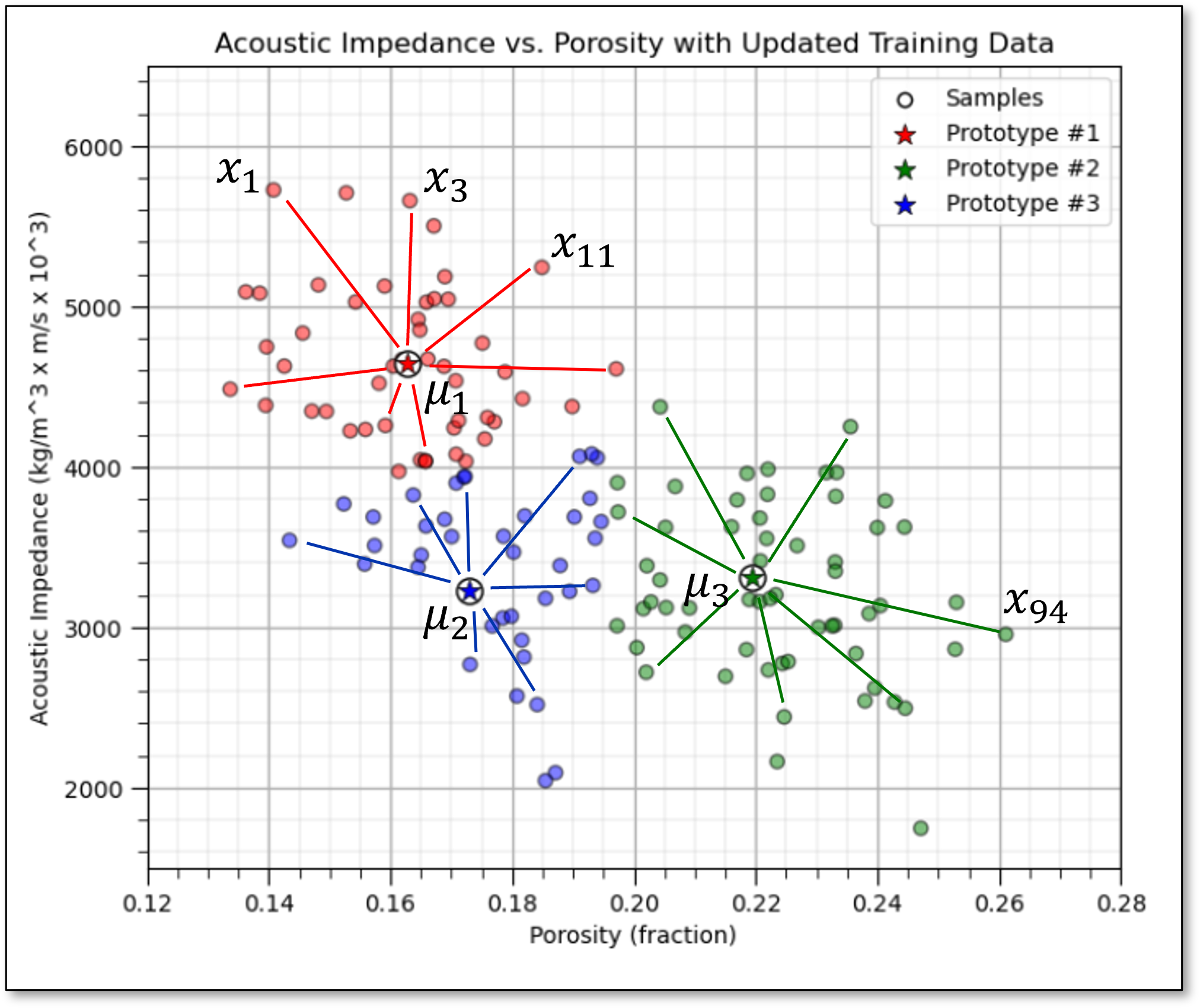
Here’s a schematic illustration of this loss function, summing the distances between group prototypes and the samples in the groups,
Here is a summary of import aspects for K-means clustering:
Prototype Method - represents the training data with number of synthetic cases in the features space. For K-means clustering we assign and iteratively update \(K\) prototypes.
Iterative Solution - the initial prototypes are assigned randomly in the feature space, the labels for each training sample are updated to the nearest prototype, then the prototypes are adjusted to the centroid of their assigned training data, repeat until there is no further update to the training data assignments.
Unsupervised Learning - the training data are not labeled and are assigned \(K\) labels based on their proximity to the prototypes in the feature space. The idea is that similar things, proximity in feature space, should belong to the same cluster group.
Feature Weighting - the procedure depends on the Euclidian distance between training samples and prototypes in feature space. Distance is treated as the ‘inverse’ of similarity. If the features have significantly different magnitudes, the feature(s) with the largest magnitudes and ranges will dominate the loss function and cluster groups will become anisotropic aligned orthogonal to the high range feature(s). While the common approach is to standardize / normalize the variables, by-feature weighting may be applied through unequal variances. Note, in this demonstration we normalize the features to range from 0.0 to 1.0.
Solution Heuristic#
Let’s first define a solution heuristic,
Heuristic - a shortcut the sacrifices accuracy for practicality, i.e., the solution is usually good enough and has a reasonable run time.
For the K-means clustering problem of assigning one of \(k\) categorical labels to \(n\) sample data, the solution space includes,
possible solutions.
The k-means clustering solution heuristic includes these steps:
Assign initial random prototype with labels.
Assign samples to the nearest prototype.
Update prototype based on centroids of samples belonging to this prototype.
Iterate (return to step 2) until no sample assignments change (prototypes stop moving).

Demonstration#
I start with a ‘by-hand’ approach to calculate the K-means clustering group assignments.
this allows us to be able to watch the method in action, as opposed to just getting a result. I think this is more instructive.
afterwards, I show the function from scikit-learn to complete the calculation in one line of code.
I have also developed a set of interactive k-means clustering dashboards to explore the k-mean clustering heuristic, including this one that shows each solution for multiple random prototypes and the cumulative distribution function of intertia to explore the consistency in the solution.
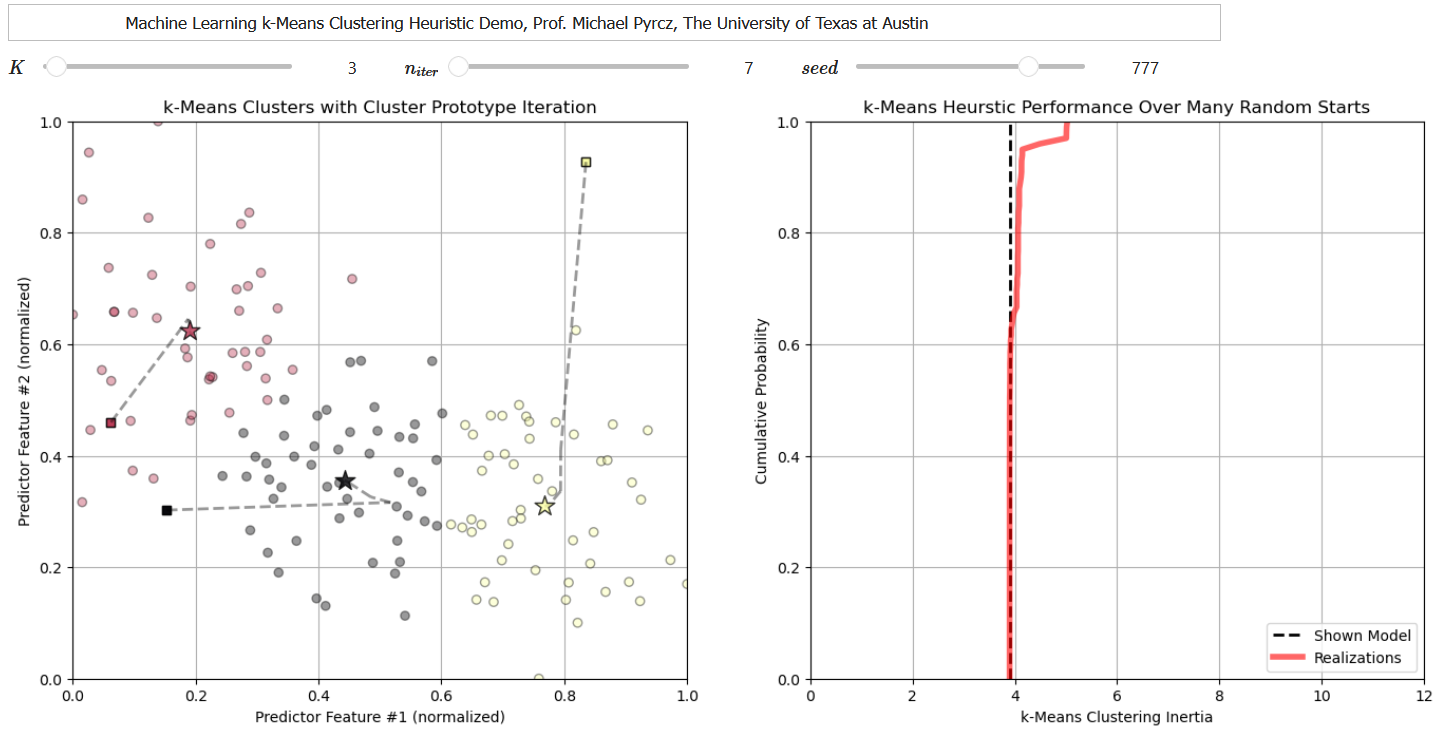
Note, for the workflow below I have modified code from the tutorial provided by Ben Keen as functions to take care of the steps (assign training data to the nearest prototype, update the prototype to the centroid of the assigned data).
The original tutorial is available at here.
My modifications tailor this workflow for my specific example, and to include the normalized and original data. Appreciation to Ben!
Load the Required Libraries#
The following code loads the required libraries. These should have been installed with Anaconda 3.
ignore_warnings = True # ignore warnings?
import numpy as np # ndarrays for gridded data
import pandas as pd # DataFrames for tabular data
import copy # for deep copies
import os # set working directory, run executables
import matplotlib.pyplot as plt # for plotting
from matplotlib.ticker import (MultipleLocator, AutoMinorLocator) # control of axes ticks
import matplotlib.ticker as mtick # control tick label formatting
import seaborn as sns # for matrix scatter plots
from sklearn.preprocessing import MinMaxScaler # min/max normalization
from sklearn.metrics import silhouette_score # calculating the optimum K number of clusters
from sklearn.cluster import KMeans # k-means clustering
plt.rc('axes', axisbelow=True) # plot all grids below the plot elements
if ignore_warnings == True:
import warnings
warnings.filterwarnings('ignore')
cmap = plt.cm.inferno # color map
seed = 42 # random number seed
Declare Functions#
The following functions perform the steps required by K-means clustering.
assign the training data to the nearest prototype
update the prototype to the centroid of the assigned training data
Don’t be concerned if you don’t understand the code, we have used some advanced approaches for the benefit of concise code.
I also added a convenience function to add major and minor gridlines to improve plot interpretability.
# Assignment function to assigned training data to the nearest prototype (code modified from Ben Keen, http://benalexkeen.com/k-means-clustering-in-python/)
def assignment(df,centroids):
for i in centroids.keys():
df['distance_from_{}'.format(i)] = ( # use the normalized features and centroids
np.sqrt(
(df['Norm_Porosity'] - centroids[i][2]) ** 2
+ (df['Norm_AI'] - centroids[i][3]) ** 2
)
)
centroid_distance_cols = ['distance_from_{}'.format(i) for i in centroids.keys()]
df['closest'] = df.loc[:, centroid_distance_cols].idxmin(axis=1)
df['closest'] = df['closest'].map(lambda x: int(x.lstrip('distance_from_')))
df['color'] = df['closest'].map(lambda x: colmap[x])
return
# Update function to shift the prototype to the centroid of the training data assigned to the prototype (code modified from Ben Keen, http://benalexkeen.com/k-means-clustering-in-python/)
def update(df,centroids,x1min,x1max,x2min,x2max):
for i in centroids.keys():
centroids[i][2] = np.mean(df[df['closest'] == i]['Norm_Porosity'])
centroids[i][3] = np.mean(df[df['closest'] == i]['Norm_AI'])
centroids[i][0] = centroids[i][2] * (x1max-x1min) + x1min
centroids[i][1] = centroids[i][3] * (x2max-x2min) + x2min
return
def add_grid():
plt.gca().grid(True, which='major',linewidth = 1.0); plt.gca().grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
Set the Working Directory#
I always like to do this so I don’t lose files and to simplify subsequent read and writes (avoid including the full address each time).
#os.chdir("C:/PGE383") # set the working directory with the input data file
Loading Tabular Data#
Here’s the command to load our comma delimited data file in to a Pandas’ DataFrame object.
Let’s load the provided multivariate, spatial dataset ‘12_sample_data.csv’. It is a comma delimited file with:
X and Y coordinates (\(m\))
facies 0 and 1
porosity (fraction)
permeability (\(mD\))
acoustic impedance (\(\frac{kg}{m^3} \cdot \frac{m}{s} \cdot 10^3\)).
We load it with the pandas ‘read_csv’ function into a DataFrame we called ‘df’ and then preview it to make sure it loaded correctly.
Python Tip: using functions from a package just type the label for the package that we declared at the beginning:
import pandas as pd
so we can access the pandas function ‘read_csv’ with the command:
pd.read_csv()
but read csv has required input parameters. The essential one is the name of the file. For our circumstance all the other default parameters are fine. If you want to see all the possible parameters for this function, just go to the docs here.
The docs are always helpful
There is often a lot of flexibility for Python functions, possible through using various inputs parameters
also, the program has an output, a pandas DataFrame loaded from the data. So we have to specify the name / variable representing that new object.
df = pd.read_csv("12_sample_data.csv")
Let’s run this command to load the data and then this command to extract a random subset of the data.
df = df.sample(frac=.30, random_state = 73073);
df = df.reset_index()
We do this to reduce the number of data for ease of visualization (hard to see if too many points on our plots).
#df = pd.read_csv('12_sample_data.csv') # load our data table from the current directory
df = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/12_sample_data.csv') # or from GtiHub
df = df.iloc[:,1:] # remove a null column
df = df.sample(frac=.30, random_state = seed); df = df.reset_index(drop=True) # extract 30% random to reduce the number of data
Summary Statistics for Tabular Data#
The table includes porosity (fraction) and acoustic impedance (\(\frac{kg}{m^3} \cdot \frac{m}{s} \cdot 10^3\)) that we will work with in the demonstration below.
There are a lot of efficient methods to calculate summary statistics from tabular data in DataFrames. The describe command provides count, mean, minimum, maximum, and quartiles all in a nice data table. We use transpose just to flip the table so that features are on the rows and the statistics are on the columns.
df.describe().transpose() # DataFrame summary statistics
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| X | 144.0 | 3910.668909 | 2563.309885 | 6.161100 | 1978.194998 | 3500.392517 | 5502.096026 | 9703.495538 |
| Y | 144.0 | 5093.498955 | 2861.683625 | 491.789431 | 2503.509193 | 5393.325918 | 7596.505416 | 9897.863401 |
| Facies | 144.0 | 0.618056 | 0.487559 | 0.000000 | 0.000000 | 1.000000 | 1.000000 | 1.000000 |
| Porosity | 144.0 | 0.191045 | 0.031262 | 0.133681 | 0.165889 | 0.185460 | 0.220655 | 0.261091 |
| Perm | 144.0 | 568.892892 | 1265.582175 | 0.035608 | 9.382939 | 64.000905 | 425.323240 | 7452.343369 |
| AI | 144.0 | 3749.924448 | 821.100292 | 1746.387548 | 3131.159498 | 3686.800017 | 4292.981181 | 5725.525232 |
Normalize the Features#
The two features are quite incompatible. They have dramatically different:
variances / ranges
We should normalize each feature to range between 0 to 1. The equation is:
This is a distribution, shift, stretch or squeeze without any distribution shape change.
Now we can use these normalized values for calculating distance in our workflow:
to remove the influence of magnitude and range on our similarity calculation
pormin = df['Porosity'].min(); pormax = df['Porosity'].max() # find min and max for each feature
AImin = df['AI'].min(); AImax = df['AI'].max()
df['Norm_Porosity'] = (df['Porosity']-pormin)/(pormax - pormin) # normalize each feature, this broadcasts over all samples in the DataFrame
df['Norm_AI'] = (df['AI']-AImin)/(AImax - AImin) # and appends a new normalized feature for each
Of course there is a normalize function in scikit-learn, but we did this ‘by-hand’ this first time to ensure the operation is perfectly clear.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_normalized = scaler.fit_transform(X)
Let’s confirm that our normalized porosity and acoustic impedance now range between 0 and 1.
df.describe().transpose() # summary statistics for the DataFrame
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| X | 144.0 | 3910.668909 | 2563.309885 | 6.161100 | 1978.194998 | 3500.392517 | 5502.096026 | 9703.495538 |
| Y | 144.0 | 5093.498955 | 2861.683625 | 491.789431 | 2503.509193 | 5393.325918 | 7596.505416 | 9897.863401 |
| Facies | 144.0 | 0.618056 | 0.487559 | 0.000000 | 0.000000 | 1.000000 | 1.000000 | 1.000000 |
| Porosity | 144.0 | 0.191045 | 0.031262 | 0.133681 | 0.165889 | 0.185460 | 0.220655 | 0.261091 |
| Perm | 144.0 | 568.892892 | 1265.582175 | 0.035608 | 9.382939 | 64.000905 | 425.323240 | 7452.343369 |
| AI | 144.0 | 3749.924448 | 821.100292 | 1746.387548 | 3131.159498 | 3686.800017 | 4292.981181 | 5725.525232 |
| Norm_Porosity | 144.0 | 0.450230 | 0.245367 | 0.000000 | 0.252789 | 0.406397 | 0.682631 | 1.000000 |
| Norm_AI | 144.0 | 0.503510 | 0.206351 | 0.000000 | 0.348008 | 0.487646 | 0.639986 | 1.000000 |
Extract Features of Interest#
Now let’s slice out the porosity and acoustic impedance features and then look at the resulting DataFrame to ensure that we loaded and reformatted as expected.
I often separate only the feature of interest to simplify my workflows and to reduce the probability of blunders, such as accidentally referring to a feature not being used in the current workflow!
Beware, this is a shallow copy; therefore, any changes to the df_subset DataFrame will be reflected in the original df DataFrame. The slice is actually a reference to the original DataFrame in memory.
df_subset = df.iloc[:,[3,5,6,7]] # extract Porosity and AI for a simple 2D example
df_subset.head() # preview the new DataFrame
| Porosity | AI | Norm_Porosity | Norm_AI | |
|---|---|---|---|---|
| 0 | 0.252772 | 2862.446918 | 0.934709 | 0.280478 |
| 1 | 0.181580 | 2919.237330 | 0.375944 | 0.294750 |
| 2 | 0.230303 | 2999.248935 | 0.758358 | 0.314858 |
| 3 | 0.163732 | 3823.747676 | 0.235860 | 0.522063 |
| 4 | 0.197078 | 4609.845251 | 0.497583 | 0.719618 |
Infer Model Parameters#
From the summary statistics we can assign a reasonable minimum and maximum for each feature.
We will use this for plotting.
We will also set the random number seed to ensure that the program does the same thing every time it is run.
Change the seed number for a different result
We will set the number of prototypes / clusters, K
We define a dictionary with the color code for each cluster, \(k = 1,\ldots,K\). Given 7 codes currently, there will be an error if \(K\) is set larger than 7. Add more color codes to the dictionary to allow for more categories.
por_min = 0.12; por_max = 0.28 # min and max values for plotting
AI_min = 1500; AI_max = 6500
K = 6; max_iter = 100 # number of prototypes / categories
colmap = {1: 'r', 2: 'g', 3: 'b', 4: 'm', 5: 'c', 6: 'k', 7: 'w'} # color dictionary for up to 7 categories
prototypes = np.zeros((K,max_iter,2)) # store the prototypes over iterations
norm_prototypes = np.zeros((K,max_iter,2)) # store the prototypes for the standardized features over iterations
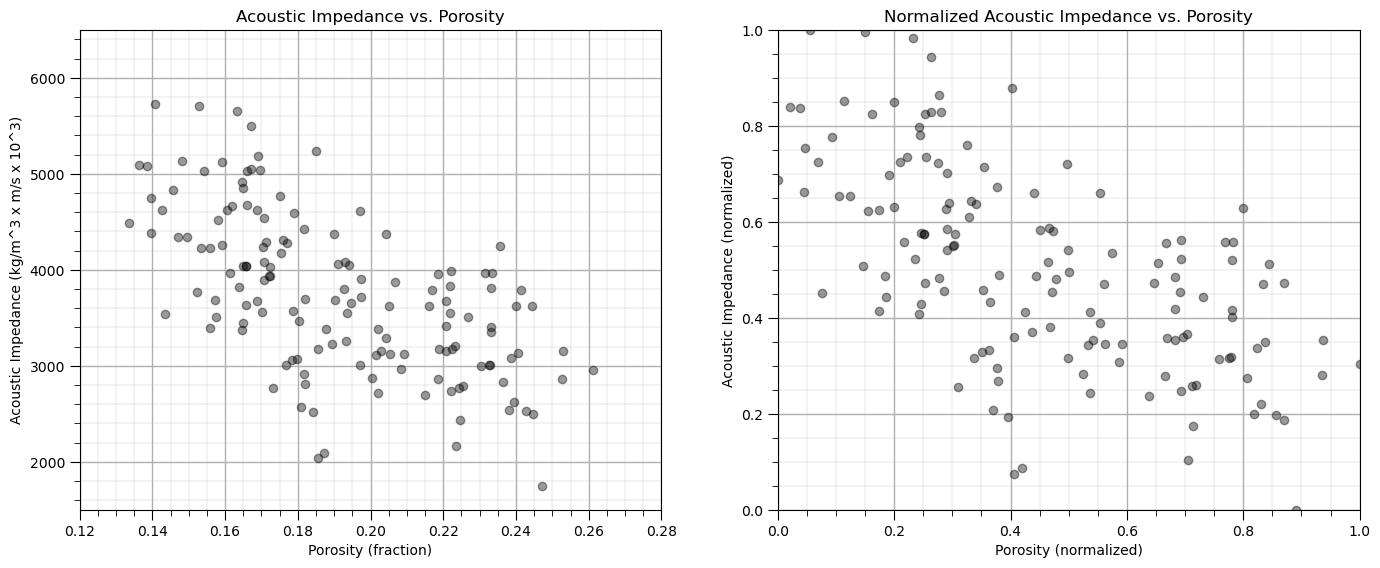
Visualize the Training Data#
In this exercise, we want to use K-means clustering provide facies based on acoustic impedance and porosity predictor features.
This allows use to group rock with similar petrophysical and geophysical properties.
Let’s start by looking at the scatterplot of our training data features, porosity and acoustic impedance.
We will look at the data in original units and normalized units through this entire exercise.
plt.subplot(121) # scatter plot our training data
plt.scatter(df_subset['Porosity'], df['AI'], c="black", alpha = 0.4, linewidths=1.0, edgecolors="black")
plt.title('Acoustic Impedance vs. Porosity'); plt.xlabel('Porosity (fraction)'); plt.ylabel('Acoustic Impedance (kg/m^3 x m/s x 10^3)')
plt.xlim(por_min, por_max); plt.ylim(AI_min, AI_max); add_grid();
plt.subplot(122) # scatter plot our normalized training data
plt.scatter(df_subset['Norm_Porosity'], df['Norm_AI'], c="black", alpha = 0.4, linewidths=1.0, edgecolors="black")
plt.title('Normalized Acoustic Impedance vs. Porosity'); plt.xlabel('Porosity (normalized)'); plt.ylabel('Acoustic Impedance (normalized)')
plt.xlim(0.0,1.0); plt.ylim(0.0,1.0); add_grid();
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.0, wspace=0.2, hspace=0.2); plt.show()
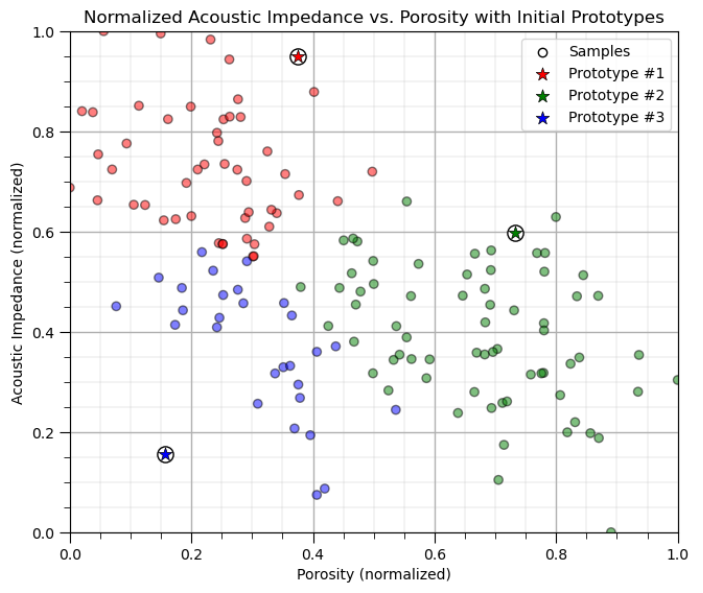
Calculating k-Means Clustering By-hand#
Here’s the steps to calculate k-means clusters for our unlabelled dataset.
Initialize k Prototypes#
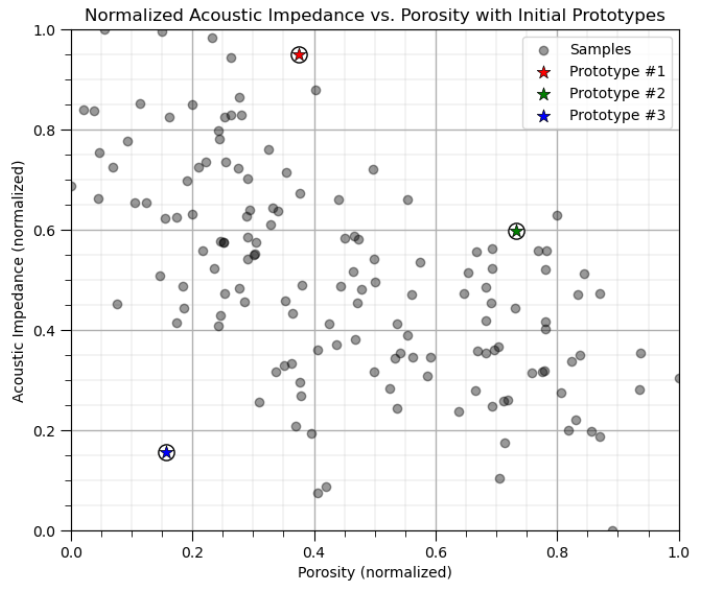
First we will assign k prototypes in the feature space randomly.
for K prototypes assign a random porosity and acoustic impedance
don’t worry, these prototypes won’t make much sense initially, but they will improve
We will do this and then visualize the prototypes as red, green, blue etc. dots.
np.random.seed(seed) # random number seed for repeatability of the results
centroids = {}
for i in range(K): # Assign Initial Prototypes
norm_por = np.random.random(); por = norm_por * (pormax-pormin) + pormin
norm_AI = np.random.random(); AI = norm_AI * (AImax-AImin) + AImin
centroids[i+1] = [por,AI,norm_por,norm_AI]; prototypes[i,0] = [por,AI]; norm_prototypes[i,0] = [norm_por,norm_AI]
plt.subplot(121) # plot the training data and K prototypes
plt.scatter(df_subset['Porosity'], df['AI'],c="black",alpha = 0.4,linewidths=1.0,edgecolors="black",zorder=1,label='Samples')
for i in centroids.keys():
plt.scatter(centroids.get(i)[0], centroids.get(i)[1],color='white',s=120,marker='o',linewidths=1.0, edgecolors="black",zorder=10)
plt.scatter(centroids.get(i)[0], centroids.get(i)[1],color=colmap[i],s=90,marker='*',linewidths=0.5, edgecolors="black",zorder=20,
label='Prototype #'+str(i))
plt.title('Acoustic Impedance vs. Porosity with Initial Prototypes'); plt.xlabel('Porosity (fraction)')
plt.ylabel('Acoustic Impedance (kg/m^3 x m/s x 10^3)')
plt.xlim(por_min, por_max); plt.ylim(AI_min, AI_max); add_grid(); plt.legend(loc='upper right')
plt.subplot(122) # plot the training data and K prototypes
plt.scatter(df_subset['Norm_Porosity'], df['Norm_AI'], c="black", alpha = 0.4, linewidths=1.0, edgecolors="black",label='Samples')
for i in centroids.keys():
plt.scatter(centroids.get(i)[2], centroids.get(i)[3],color='white',s=120,marker='o',linewidths=1.0, edgecolors="black",zorder=10)
plt.scatter(centroids.get(i)[2], centroids.get(i)[3],color=colmap[i],s=90,marker='*',linewidths=0.5, edgecolors="black",zorder=20,
label='Prototype #'+str(i))
plt.title('Normalized Acoustic Impedance vs. Porosity with Initial Prototypes'); plt.xlabel('Porosity (normalized)')
plt.ylabel('Acoustic Impedance (normalized)')
plt.xlim([0, 1]); plt.ylim([0, 1]); add_grid(); plt.legend(loc='upper right')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.0, wspace=0.2, hspace=0.2); plt.show()
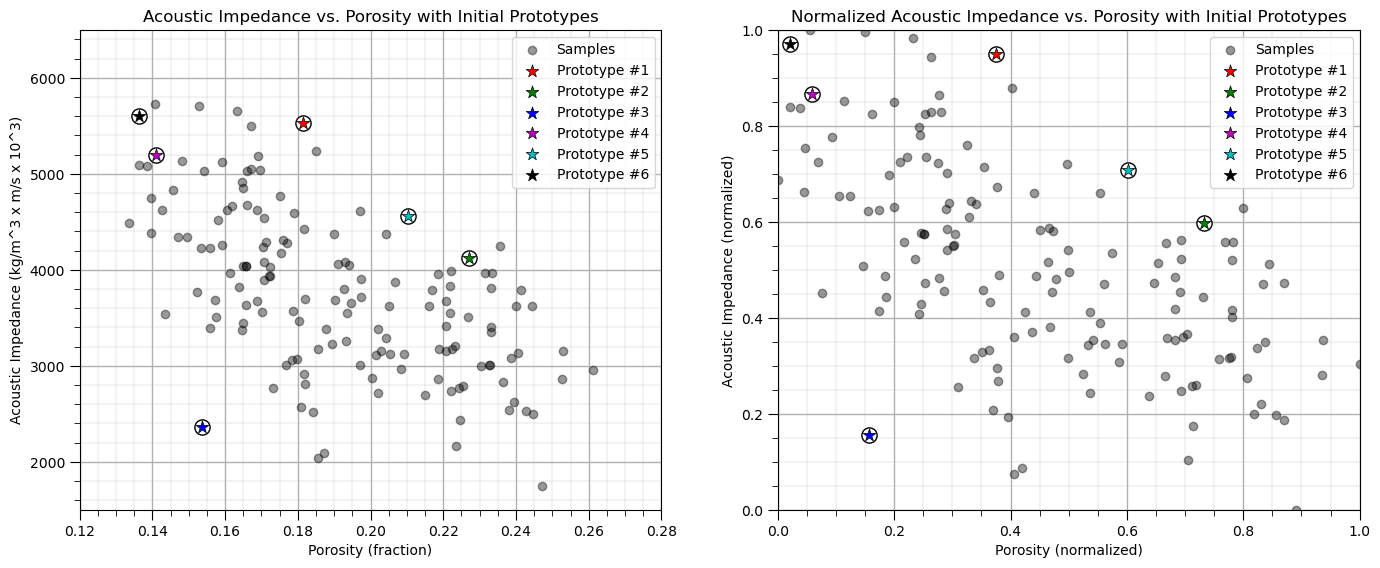
Assignment of Training Data#
All training data are assigned to the nearest prototype.
recall we have a function to do this
df = assignment(df, centroids)
we work with the normalized features and visualize normalized and original features
assignment(df, centroids) # assign training data to the nearest prototype
plt.subplot(121) # plot the assigned training data and K prototypes
plt.scatter(df['Porosity'], df['AI'], color=df['color'], alpha=0.5, edgecolor='k'); plt.scatter(-999,-999,color='white',edgecolors='black',
label='Samples')
for i in centroids.keys():
plt.scatter(centroids.get(i)[0], centroids.get(i)[1],color='white',s=120,marker='o',linewidths=1.0, edgecolors="black",zorder=10)
plt.scatter(centroids.get(i)[0], centroids.get(i)[1],color=colmap[i],s=90,marker='*',linewidths=0.5, edgecolors="black",zorder=20,
label='Prototype #'+str(i))
plt.title('Acoustic Impedance vs. Porosity with Initial Prototypes'); plt.xlabel('Porosity (fraction)')
plt.ylabel('Acoustic Impedance (kg/m^3 x m/s x 10^3)')
plt.xlim(por_min, por_max); plt.ylim(AI_min, AI_max); add_grid(); plt.legend(loc='upper right')
plt.subplot(122) # plot the normalized training data and K prototypes
plt.scatter(df_subset['Norm_Porosity'], df['Norm_AI'], c=df['color'], alpha = 0.5, linewidths=1.0, edgecolors="black")
plt.scatter(-999,-999,color='white',edgecolors='black',label='Samples')
for i in centroids.keys():
plt.scatter(centroids.get(i)[2], centroids.get(i)[3],color='white',s=120,marker='o',linewidths=1.0, edgecolors="black",zorder=10)
plt.scatter(centroids.get(i)[2], centroids.get(i)[3],color=colmap[i],s=90,marker='*',linewidths=0.5, edgecolors="black",zorder=20,
label='Prototype #'+str(i))
plt.title('Normalized Acoustic Impedance vs. Porosity with Initial Prototypes'); plt.xlabel('Porosity (normalized)')
plt.ylabel('Acoustic Impedance (normalized)')
plt.xlim([0, 1]); plt.ylim([0, 1]); add_grid(); plt.legend(loc='upper right')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.0, wspace=0.2, hspace=0.2); plt.show()
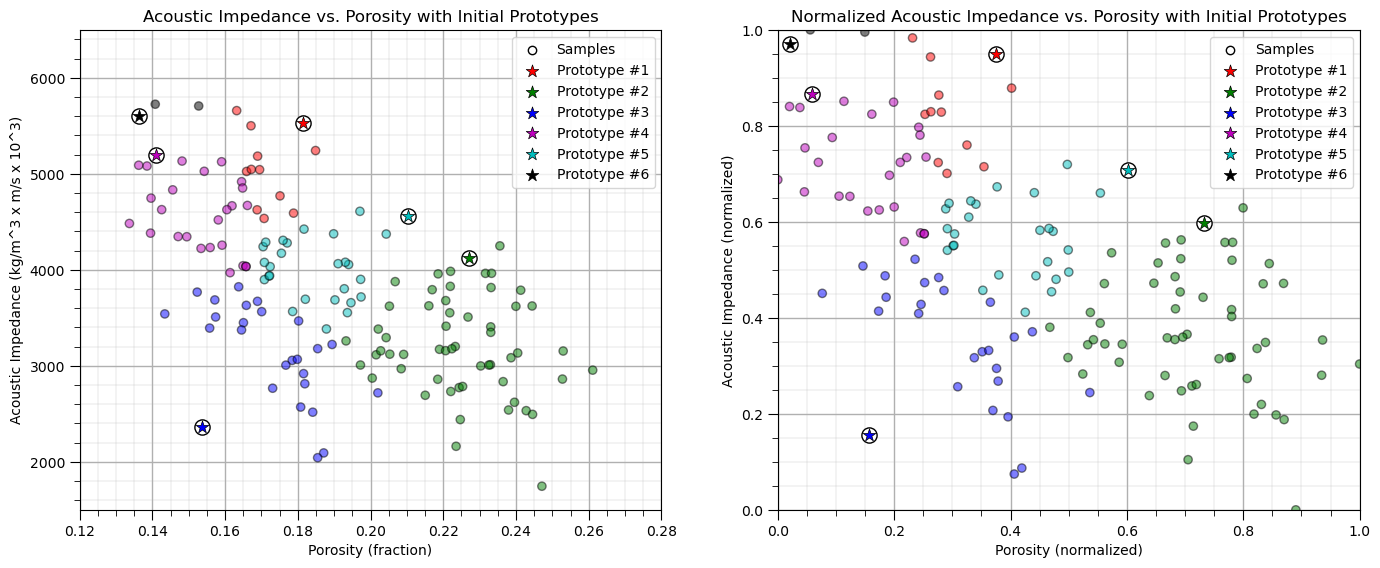
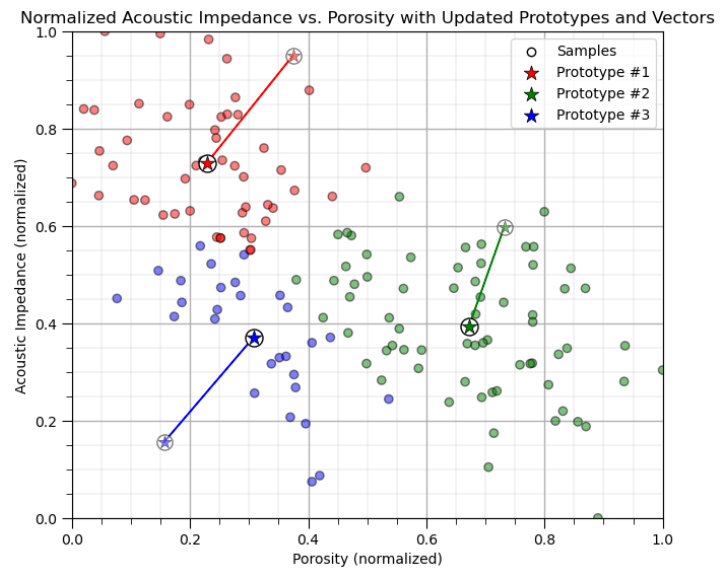
Update the Prototypes#
Now we reassign the prototypes to the centroids of the training data belonging to each.
old_centroids = copy.deepcopy(centroids) # make a deep copy of the centroids for plotting vectors below
update(df,centroids,pormin,pormax,AImin,AImax) # update the centroids to the new data assignments
plt.subplot(121) # plot the assigned training data and k prototypes
ax = plt.gca()
plt.scatter(df['Porosity'], df['AI'], color=df['color'], alpha=0.5, edgecolor='k')
plt.scatter(-999,-999,color='white',edgecolors='black',label='Samples')
for i in centroids.keys():
plt.scatter(old_centroids.get(i)[0], old_centroids.get(i)[1],color='white',s=120,marker='o',linewidths=1.0,alpha=0.5,
edgecolors="black",zorder=10)
plt.scatter(old_centroids.get(i)[0], old_centroids.get(i)[1],color=colmap[i],s=90,marker='*',linewidths=0.5,alpha=0.5,
edgecolors="black",zorder=20)
plt.scatter(centroids.get(i)[0], centroids.get(i)[1],color='white',s=150,marker='o',linewidths=1.0, edgecolors="black",zorder=10)
plt.scatter(centroids.get(i)[0], centroids.get(i)[1],color=colmap[i],s=120,marker='*',linewidths=0.5,
edgecolors="black",zorder=20,label='Prototype #'+str(i))
prototypes[i-1,1] = [centroids[i][0],centroids[i][1]]; norm_prototypes[i-1,1] = [centroids[i][2],centroids[i][3]]
plt.title('Acoustic Impedance vs. Porosity with Updated Prototypes and Vectors'); plt.xlabel('Porosity (fraction)')
plt.ylabel('Acoustic Impedance (kg/m^3 x m/s x 10^3)')
plt.xlim(por_min, por_max); plt.ylim(AI_min, AI_max); add_grid(); plt.legend(loc='upper right')
for i in old_centroids.keys(): # plot the vectors
old_x = old_centroids[i][0]
old_y = old_centroids[i][1]
dx = (centroids[i][0] - old_centroids[i][0])
dy = (centroids[i][1] - old_centroids[i][1])
ax.arrow(old_x, old_y, dx, dy,fc=colmap[i], ec=colmap[i]);
plt.subplot(122) # plot the normalized assigned training data and k prototypes
ax = plt.gca()
plt.scatter(df['Norm_Porosity'], df['Norm_AI'], color=df['color'], alpha=0.5, edgecolor='k')
plt.scatter(-999,-999,color='white',edgecolors='black',label='Samples')
for i in centroids.keys():
plt.scatter(old_centroids.get(i)[2], old_centroids.get(i)[3],color='white',s=120,marker='o',linewidths=1.0,alpha=0.5,
edgecolors="black",zorder=10)
plt.scatter(old_centroids.get(i)[2], old_centroids.get(i)[3],color=colmap[i],s=90,marker='*',linewidths=0.5,alpha=0.5,
edgecolors="black",zorder=20)
plt.scatter(centroids.get(i)[2], centroids.get(i)[3],color='white',s=150,marker='o',linewidths=1.0, edgecolors="black",zorder=10)
plt.scatter(centroids.get(i)[2], centroids.get(i)[3],color=colmap[i],s=120,marker='*',linewidths=0.5, edgecolors="black",zorder=20,
label='Prototype #'+str(i))
plt.title('Normalized Acoustic Impedance vs. Porosity with Updated Prototypes and Vectors'); plt.xlabel('Porosity (normalized)')
plt.ylabel('Acoustic Impedance (normalized)')
plt.xlim([0, 1]); plt.ylim([0, 1]); add_grid(); plt.legend(loc='upper right')
for i in old_centroids.keys(): # plot the vectors
old_x = old_centroids[i][2]
old_y = old_centroids[i][3]
dx = (centroids[i][2] - old_centroids[i][2])
dy = (centroids[i][3] - old_centroids[i][3])
ax.arrow(old_x, old_y, dx, dy,fc=colmap[i], ec=colmap[i])
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.0, wspace=0.2, hspace=0.2); plt.show()
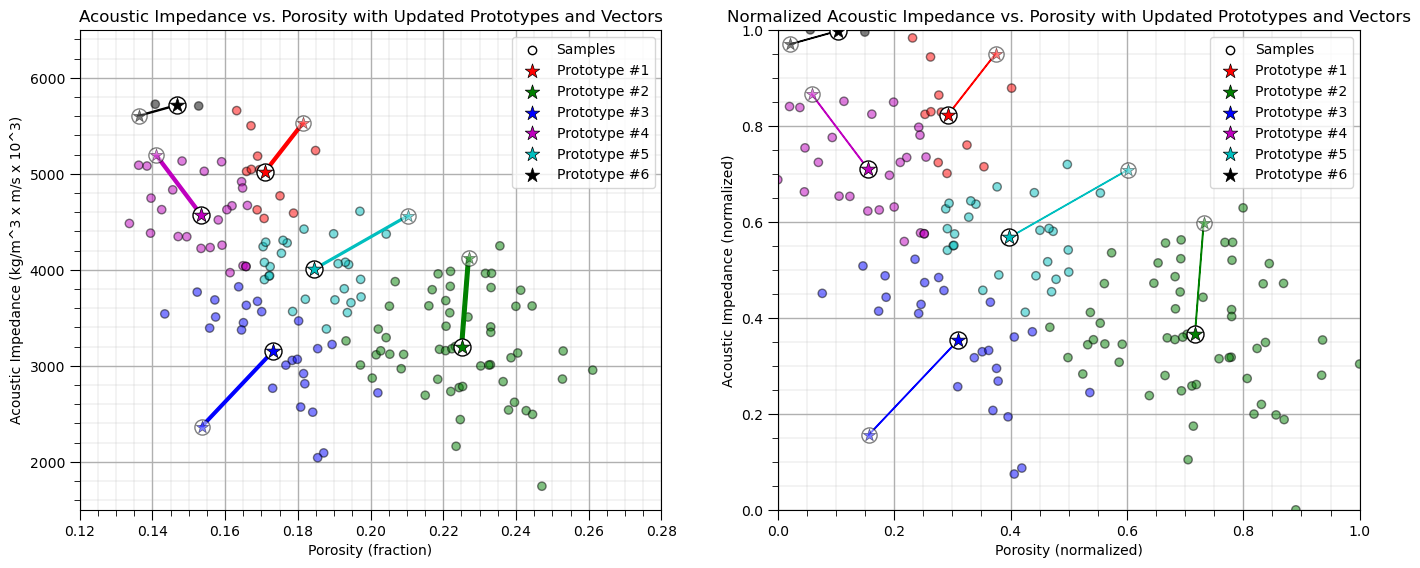
Repeat the Assignment of the Training Data#
Once again we assign the training data to the nearest prototype.
Note the prototypes were updated in the previous step so the assignments may change
assignment(df, centroids) # assign samples to nearest prototype
plt.subplot(121) # plot the assigned training data and K prototypes
plt.scatter(df['Porosity'], df['AI'], color=df['color'], alpha=0.5, edgecolor='k'); plt.scatter(-999,-999,color='white',
edgecolors='black',label='Samples')
for i in centroids.keys():
plt.scatter(centroids.get(i)[0], centroids.get(i)[1],color='white',s=120,marker='o',linewidths=1.0, edgecolors="black",zorder=10)
plt.scatter(centroids.get(i)[0], centroids.get(i)[1],color=colmap[i],s=90,marker='*',linewidths=0.5, edgecolors="black",zorder=20,
label='Prototype #'+str(i))
plt.title('Acoustic Impedance vs. Porosity with Updated Training Data'); plt.xlabel('Porosity (fraction)')
plt.ylabel('Acoustic Impedance (kg/m^3 x m/s x 10^3)')
plt.xlim(por_min, por_max); plt.ylim(AI_min, AI_max); add_grid(); plt.legend(loc='upper right')
plt.subplot(122) # plot the normalized training data and K prototypes
plt.scatter(df_subset['Norm_Porosity'], df['Norm_AI'], c=df['color'], alpha = 0.4, linewidths=1.0, edgecolors="black")
plt.scatter(-999,-999,color='white',edgecolors='black',label='Samples')
for i in centroids.keys():
plt.scatter(centroids.get(i)[2], centroids.get(i)[3],color='white',s=120,marker='o',linewidths=1.0, edgecolors="black",zorder=10)
plt.scatter(centroids.get(i)[2], centroids.get(i)[3],color=colmap[i],s=90,marker='*',linewidths=0.5, edgecolors="black",
zorder=20,label='Prototype #'+str(i))
plt.title('Normalized Acoustic Impedance vs. Porosity with Updated Training Data'); plt.xlabel('Porosity (normalized)')
plt.ylabel('Acoustic Impedance (normalized)')
plt.xlim([0, 1]); plt.ylim([0, 1]); add_grid(); plt.legend(loc='upper right')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.0, wspace=0.2, hspace=0.2); plt.show()
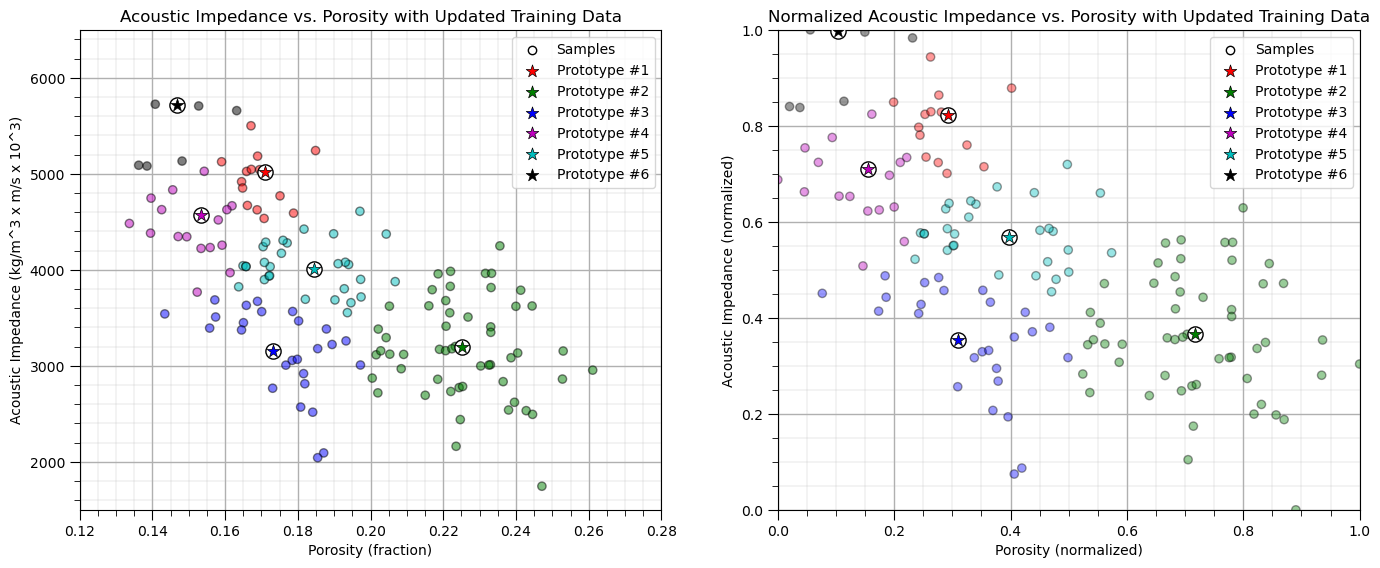
Iterate Until Convergence#
Now we iterate over the previous set of steps:
assign the training data to the nearest prototype
update the prototypes
We do this until there is no further chance in the category assigned to each of the training data.
iteration = 2 # initialize a counter, we already completed iteration 0 and 1 above
while True:
closest_centroids = df['closest'].copy(deep=True)
update(df,centroids,pormin,pormax,AImin,AImax)
for i in centroids.keys():
prototypes[i-1,iteration] = [centroids[i][0],centroids[i][1]]
norm_prototypes[i-1,iteration] = [centroids[i][2],centroids[i][3]]
assignment(df, centroids)
if closest_centroids.equals(df['closest']):
break
iteration = iteration + 1
plt.subplot(121) # plot the assigned training data and K prototypes
plt.scatter(df['Porosity'], df['AI'], color=df['color'], alpha=0.5, edgecolor='k')
for i in centroids.keys():
plt.scatter(prototypes[i-1,0,0], prototypes[i-1,0,1],color='white',s=120,marker='o',linewidths=1.0,alpha=0.5,edgecolors="black",zorder=10)
plt.scatter(prototypes[i-1,0,0], prototypes[i-1,0,1],color=colmap[i],s=90,marker='*',linewidths=0.5,alpha=0.5,edgecolors="black",zorder=20)
plt.scatter(centroids.get(i)[0], centroids.get(i)[1],color='white',s=120,marker='o',linewidths=1.0, edgecolors="black",zorder=10)
plt.scatter(centroids.get(i)[0], centroids.get(i)[1],color=colmap[i],s=90,marker='*',linewidths=0.5, edgecolors="black",
zorder=20,label='Prototype #'+str(i))
plt.plot(prototypes[i-1,:iteration+1,0],prototypes[i-1,:iteration+1,1],color=colmap[i],zorder = 1)
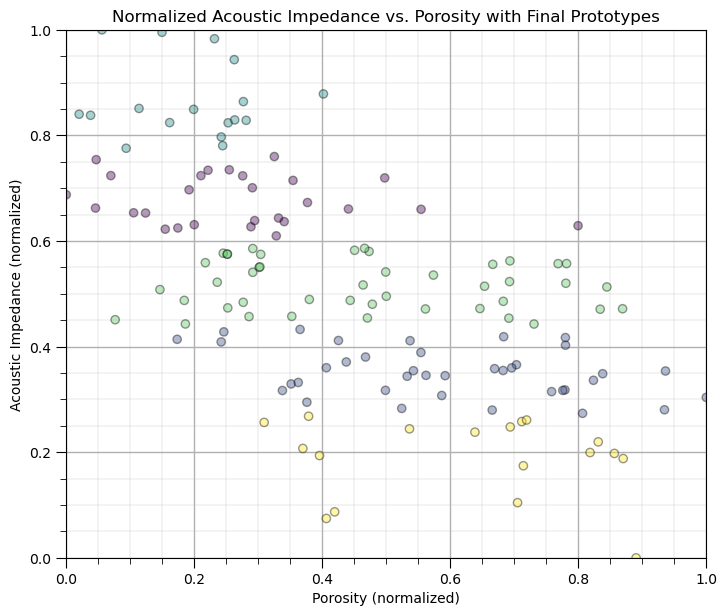
plt.title('Acoustic Impedance vs. Porosity with Final Prototypes'); plt.xlabel('Porosity (fraction)')
plt.ylabel('Acoustic Impedance (kg/m^3 x m/s x 10^3)')
plt.xlim(por_min, por_max); plt.ylim(AI_min, AI_max); add_grid(); plt.legend(loc='upper right')
plt.subplot(122) # plot the training data and K prototypes
plt.scatter(df_subset['Norm_Porosity'], df['Norm_AI'], c=df['color'], alpha = 0.4, linewidths=1.0, edgecolors="black")
for i in centroids.keys():
plt.scatter(norm_prototypes[i-1,0,0], norm_prototypes[i-1,0,1],color='white',s=120,marker='o',linewidths=1.0,alpha=0.5,
edgecolors="black",zorder=10)
plt.scatter(norm_prototypes[i-1,0,0], norm_prototypes[i-1,0,1],color=colmap[i],s=90,marker='*',linewidths=0.5,alpha=0.5,
edgecolors="black",zorder=20)
plt.scatter(centroids.get(i)[2], centroids.get(i)[3],color='white',s=120,marker='o',linewidths=1.0, edgecolors="black",zorder=10)
plt.scatter(centroids.get(i)[2], centroids.get(i)[3],color=colmap[i],s=90,marker='*',linewidths=0.5, edgecolors="black",
zorder=20,label='Prototype #'+str(i))
plt.plot(norm_prototypes[i-1,:iteration+1,0],norm_prototypes[i-1,:iteration+1,1],color=colmap[i],zorder = 1)
plt.title('Normalized Acoustic Impedance vs. Porosity with Final Prototypes'); plt.xlabel('Porosity (normalized)')
plt.ylabel('Acoustic Impedance (normalized)')
plt.xlim([0, 1]); plt.ylim([0, 1]); add_grid(); plt.legend(loc='upper right')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.0, wspace=0.2, hspace=0.2); plt.show()
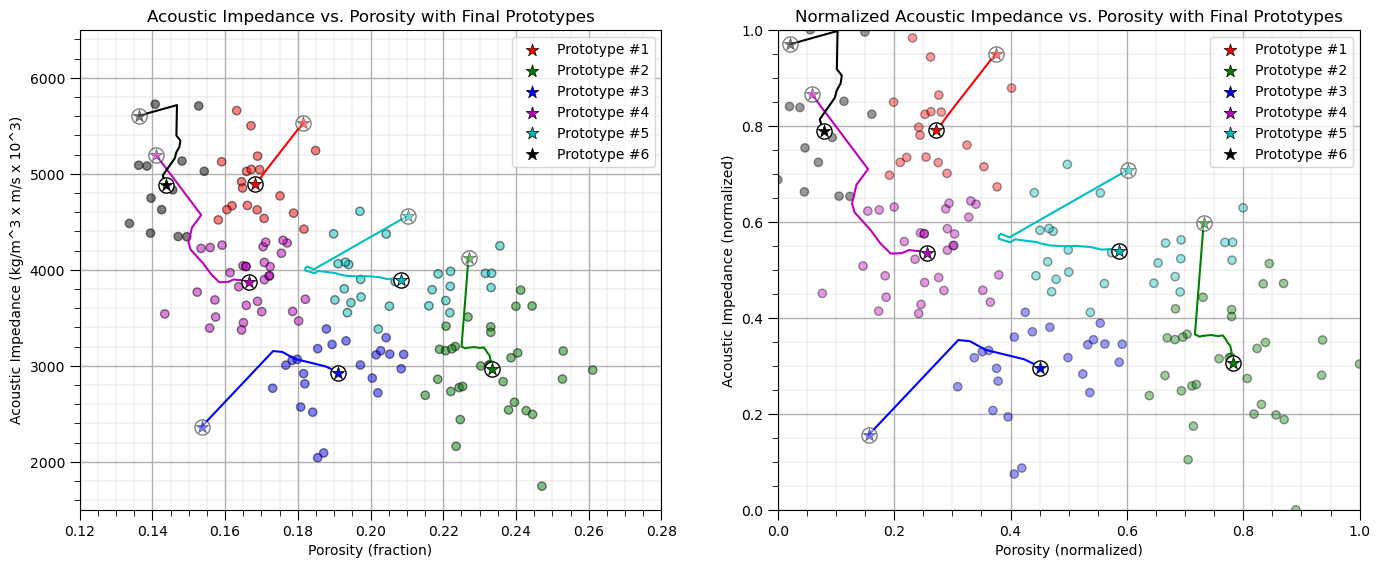
k-Means Clustering with the scikit-learn Function#
Let’s repeat with the scikit-learn function.
K = 5 # number categories / clusters
kmeans = KMeans(n_clusters=K, random_state=seed, n_init = 100).fit(df.loc[:,['Norm_Porosity','Norm_AI']]) # k-means clustering
df['kMeans'] = kmeans.labels_ + 1
plt.subplot(111) # plot the training data and K prototypes
plt.scatter(df_subset['Norm_Porosity'], df['Norm_AI'], c=df['kMeans'], alpha = 0.4, linewidths=1.0, edgecolors="black")
plt.title('Normalized Acoustic Impedance vs. Porosity with Final Prototypes'); plt.xlabel('Porosity (normalized)')
plt.ylabel('Acoustic Impedance (normalized)')
plt.xlim([0, 1]); plt.ylim([0, 1]); add_grid()
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.2, hspace=0.2)
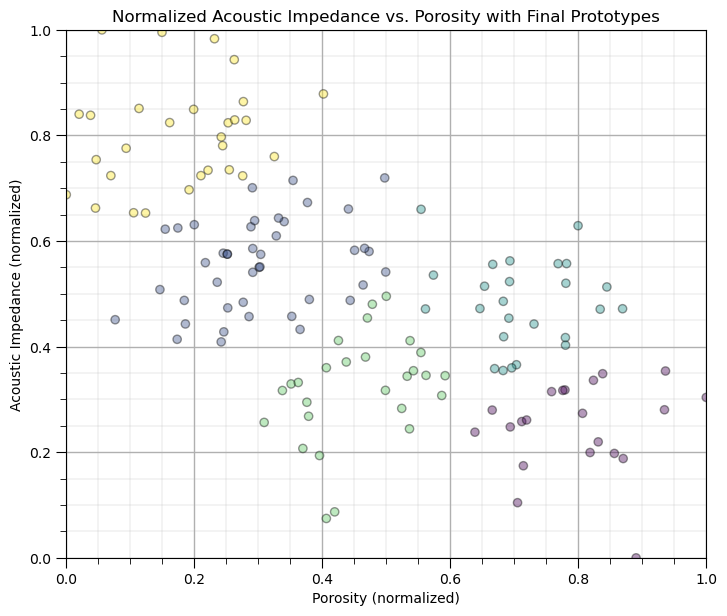
Selecting the Optimum Number of Clusters#
For K-means clustering, the K number of clusters is an input.
in some cases this choice is easy or constrained by the context of the problem, for example, we know that there are 3 distinct facies in our subsurface dataset
this can be seen as a strength for K-means clustering as we can use our expert knowledge to constrain the number of clusters
or this may be seen as a weekness for K-means clustering as the method is unable to determine the number of clusters, as with methods such as DBSCAN
When the number of clusters, K, is not know there are multiple methods to quantitatively determine an optimum K value, including,
Elbow Method - perform k-means clustering for a range of K values and the within-cluster sum of squares (WCSS) or inertia (the sum of squared distances from each point to its assigned cluster centroid) against the number of clusters (K) and look for the “elbow” point where the rate of decrease in WCSS slows down.
Silhouette Score - the silhouette score measures how similar an object is to its own cluster compared to other clusters.
Elbow Method#
The Elbow Method is a heuristic used to determine the optimal number of clusters, \(K\), in a clustering algorithm, such as K-Means.
The idea is to run the clustering algorithm for a range of cluster values \(K\), calculate a performance metric, and plot it. The elbow point on the plot represents the optimal number of clusters, where adding more clusters doesn’t significantly improve the model, that is, further reduce the loss function.
The method is based on the K-means loss function, inertia, also known more decriptively as Within-Cluster Sum of Squares (WCSS), once again this is,
where \(i\) is the cluster index, \(\alpha\) is the data sample index, \(X\) is the data sample and \(\mu_i\) is the \(i\) cluster prototype, \(k\) is the total number of clusters, and \(|| X_m - \mu_m ||\) is the Euclidean distance from a sample to the cluster prototype in \(M\) dimensional space calculated as:
The elbow method proceeds with the following steps,
Fit K-Means for different values of \(K\), select a range of possible values for (K) and for each value of (K), fit the K-Means algorithm and calculate the inertia.
Plot the Intertia vs. \(K\), create a plot where the x-axis represents the number of clusters (\(K\)) and the y-axis represents the inertia.
Look for the “elbow”, The elbow point on the plot is where the decrease in WCSS starts to slow down, indicating that increasing the number of clusters beyond this point provides diminishing returns in terms of reducing inertia.
Advantages of the elbow method include,
For K-means clustering the exact loss function is used for consistency, i.e., the fit is minimizes inertia
The limitations of sihouette score include,
The inertia method, can only be applied to K means clustering, but an elbow approach with k-distance plots is applied with density-based clustering, for example, DBSCAN.
It may not provide clear results for complex datasets with overlapping or irregularly shaped clusters.
max_K = 50 # maximum number of clusters, k
optimal_k = 13
inertia = []
for k in range(2,max_K+1): # loop over number of clusters and store the inertia
kmeans_iter = KMeans(n_clusters=k, random_state=14, n_init = 10).fit(df.loc[:,['Norm_Porosity','Norm_AI']].values)
inertia.append(kmeans_iter.inertia_)
plt.scatter(range(2,max_K+1),inertia,c='red',edgecolor='black',zorder=10)
plt.plot(range(2,max_K+1),inertia,c='red',ls='--',zorder=1)
plt.xlim(2,max_K); plt.xlabel('Number of Clusters'); plt.ylabel('Inertia'); plt.ylim(bottom=0)
plt.vlines(optimal_k,0,np.max(inertia),color='black'); plt.annotate('Optimum K = ' + str(optimal_k),[optimal_k+0.5,4.0],rotation=90.0)
plt.grid(True); plt.title('k-Means Clustering Inertia vs. Number of Clusters')
plt.xlim([0,max_K+1]); plt.ylim([0, np.max(inertia)]); add_grid()
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.2, hspace=0.2); plt.show()
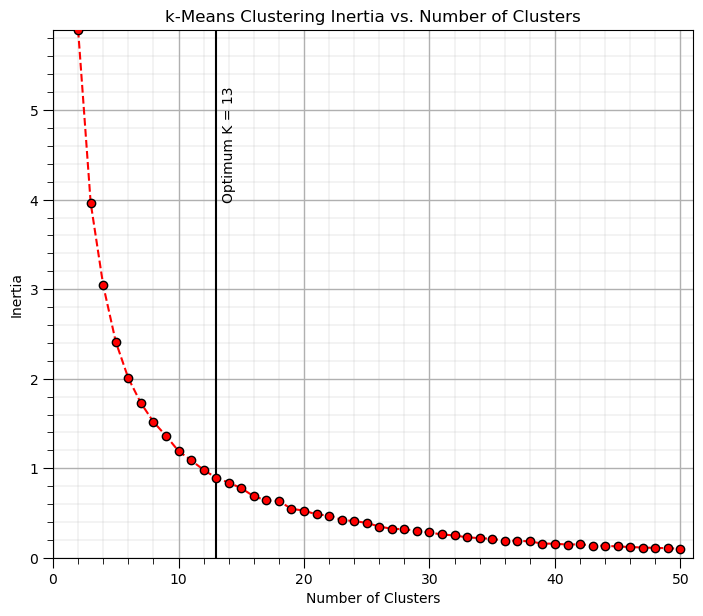
in this case there is a continuous change in gradient and not a clear elbow.
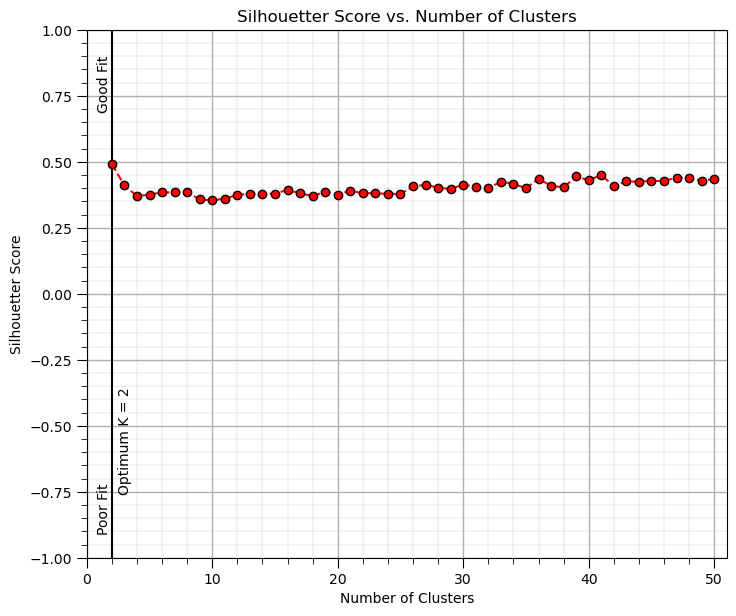
Silhouette Method#
Description: The Silhouette Score measures how similar an object is to its own cluster compared to other clusters. How it works: Compute the silhouette score for each K value. The silhouette score ranges from -1 (poor fit) to +1 (good fit), where higher values indicate better clustering. Interpretation: The optimal K corresponds to the highest average silhouette score. Pros: Provides both cohesion and separation metrics. Cons: Can be computationally expensive for large datasets.
The silhouette calculation proceeds as, for a given data point (i), the silhouette score is calculated using the following steps:
Calculate the average distance within the same cluster,
where, \(C_i\) is the cluster containing point \(i\), \(d(i, j)\) is the Euclidean distance between points \(i\) and \(j\), and \(C_i|\) is the number of points in the cluster \(C_i\).
Calculate the average distance to the nearest cluster,
where \(C_k\) is any other cluster, different from the cluster \(C_i\) that contains point \(i\).
Calculate the silhouette score for point \(i\),
where \(s(i)\) is the silhouette score for point \(i\), \(a(i)\) is the average distance to points in the same cluster, \(b(i)\) is the average distance to points in the nearest neighboring cluster.
Now over all points, calculate the overall silhouette score, the average silhouette score of all points,
where \(n\) is the number of data points, \(s(i)\) is the silhouette score of point \(i\).
We interpret overall silhouette score values as,
+1, the points on average are well clustered and far from neighboring clusters.
0, the points on average are on or very close to the boundary between two clusters.
-1, the points on average are likely assigned to the wrong cluster.
Now we repeat the overall silhouette score calculation on a range of \(K\) values and select the maximium silhouette score case as the optimum \(K\).
Advantages of the silhouette method include,
The silhouette score provides an understanding of both the compactness and separation of clusters.
Can be applied to any clustering algorithm, not just K-Means, i.e., the input is the data and cluster assignments.
The limitations of sihouette score include,
The silhouette method is computationally expensive, especially for large datasets.
It may not provide clear results for complex datasets with overlapping or irregularly shaped clusters.
max_K = 50 # maximum number of clusters, k
silhouette = []
for k in range(2,max_K+1): # loop over number of clusters and store the inertia
kmeans_iter = KMeans(n_clusters=k, random_state=14, n_init = 10).fit(df.loc[:,['Norm_Porosity','Norm_AI']].values)
score = silhouette_score(df.loc[:,['Norm_Porosity','Norm_AI']].values, kmeans_iter.labels_)
silhouette.append(score)
optimal_k = np.argmax(silhouette) + 2
plt.scatter(range(2,max_K+1),silhouette,c='red',edgecolor='black',zorder=10)
plt.annotate('Good Fit',[0.8,0.7],rotation = 90); plt.annotate('Poor Fit',[0.8,-0.9],rotation = 90)
plt.plot(range(2,max_K+1),silhouette,c='red',ls='--',zorder=1)
plt.xlim(2,max_K); plt.xlabel('Number of Clusters'); plt.ylabel('Silhouetter Score'); plt.ylim(bottom=0)
plt.vlines(optimal_k,-1,1,color='black'); plt.annotate('Optimum K = ' + str(optimal_k),[optimal_k+0.5,-0.75],rotation=90.0)
plt.grid(True); plt.title('Silhouetter Score vs. Number of Clusters')
plt.xlim([0,max_K+1]); plt.ylim([-1,1]); add_grid()
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.2, hspace=0.2); plt.show()
Clustering without Normalization / Standardization#
One of the critical assumptions of clustering is that the variability is the same over each feature.
an exception would be if the features have the same units and the variability differences are meaningful
Let’s take this dataset and draw it to scale (to show what a distance metric would see in original units.
we rotate the plot and provide an approximate visualization with porosity 1 unit equal to permeability 1 unit on the plot
effectively the dataset looks 1D to the clustering algorithm, difference in porosity becomes meaningless
Here’s what our plot looks like with equal aspect ratio between the 2 features.
the plot becomes a line and the data does not show up properly.
plt.subplot(121) # scatter plot our training data
plt.scatter(df_subset['Porosity'], df['AI'], c="black", alpha = 0.4, linewidths=1.0, edgecolors="black")
plt.title('Acoustic Impedance vs. Porosity'); plt.xlabel('Porosity (fraction)'); plt.ylabel('Acoustic Impedance (kg/m^3 x m/s x 10^3)')
plt.xlim(por_min, por_max); plt.ylim(AI_min, AI_max); add_grid();
plt.gca().set_aspect('equal', adjustable='box')

Now let’s repeat the previous k-means clustering, but with the original features (not normalized).
K = 5 # number categories / clusters
kmeans = KMeans(n_clusters=K, random_state=seed, n_init = 100).fit(df.loc[:,['Porosity','AI']]) # k-means clustering
df['kMeans_Orig'] = kmeans.labels_ + 1
plt.subplot(111) # plot the training data and K prototypes
plt.scatter(df_subset['Norm_Porosity'], df['Norm_AI'], c=df['kMeans_Orig'], alpha = 0.4, linewidths=1.0, edgecolors="black")
plt.title('Normalized Acoustic Impedance vs. Porosity with Final Prototypes'); plt.xlabel('Porosity (normalized)')
plt.ylabel('Acoustic Impedance (normalized)')
plt.xlim([0, 1]); plt.ylim([0, 1]); add_grid()
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.2, hspace=0.2)
The clusters are only in acoustic impedance since the differences in porosity on not significant due to the much larger range for the acoustic impedance feature.
clusters are orthogonal to acoustic impedance
Practice on a New Dataset#
Ok, time to get to work. Let’s load up a dataset and perform cluster analysis with,
compact code
basic visaulizations
save the output
You can select any of these datasets or modify the code and add your own to do this.
Dataset 0, Unconventional Multivariate v4#
Let’s load the provided multivariate, dataset unconv_MV.csv. This dataset has variables from 1,000 unconventional wells including:
well average porosity
log transform of permeability (to linearize the relationships with other variables)
acoustic impedance (kg/m^3 x m/s x 10^6)
brittleness ratio (%)
total organic carbon (%)
vitrinite reflectance (%)
initial production 90 day average (MCFPD).
Dataset 1, Twelve, 12#
Let’s load the provided multivariate, 2D spatial dataset 12_sample_data.csv. This dataset has variables from 480 unconventional wells including:
X (m), Y (m) location coordinates
facies (0 - shale, 1 - sand)
porosity (%) after units conversion
permeability (mD)
acoustic impedance (kg/m^3 x m/s x 10^6)
Dataset 2, Reservoir 21#
Let’s load the provided multivariate, 3D spatial dataset res21_wells.csv. This dataset has variables from 73 vertical wells over a 10,000m x 10,000m x 50 m reservoir unit:
well (ID)
X (m), Y (m), Depth (m) location coordinates
Porosity (%) after units conversion
Permeability (mD)
Acoustic Impedance (kg/m2s*10^6) after units conversion
Facies (categorical) - ordinal with ordering from Shale, Sandy Shale, Shaley Sand, to Sandstone.
Density (g/cm^3)
Compressible velocity (m/s)
Youngs modulus (GPa)
Shear velocity (m/s)
Shear modulus (GPa)
We load the tabular data with the pandas ‘read_csv’ function into a DataFrame we called ‘my_data’ and then preview it to make sure it loaded correctly.
we also populate lists with data ranges and labels for ease of plotting
Load and format the data,
drop the response feature
reformate the features as needed
also, I like to store the metadata in lists
idata = 0 # select the dataset
if idata == 0:
df_new = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/unconv_MV_v4.csv') # load data from Dr. Pyrcz's GitHub repository
df_new.drop(['Well','Prod'],axis=1,inplace=True) # remove well index and response feature
features = df_new.columns.values.tolist() # store the names of the features
xmin_new = [6.0,0.0,1.0,10.0,0.0,0.9]; xmax_new = [24.0,10.0,5.0,85.0,2.2,2.9] # set the minimum and maximum values for plotting
flabel_new = ['Porosity (%)','Permeability (mD)','Acoustic Impedance (kg/m2s*10^6)','Brittleness Ratio (%)', # set the names for plotting
'Total Organic Carbon (%)','Vitrinite Reflectance (%)']
ftitle_new = ['Porosity','Permeability','Acoustic Impedance','Brittleness Ratio', # set the units for plotting
'Total Organic Carbon','Vitrinite Reflectance']
elif idata == 1:
names = {'Porosity':'Por'}
df_new = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/12_sample_data.csv') # load data from Dr. Pyrcz's GitHub repository
df_new.drop(['X','Y','Unnamed: 0'],axis=1,inplace=True) # remove response feature
df_new = df_new.rename(columns=names)
features = df_new.columns.values.tolist() # store the names of the features
xmin_new = [0.0,0.0,0.0,4.0,0.0,6.5,1.4,1600.0,10.0,1300.0,1.6]; xmax_new = [10000.0,10000.0,1.0,19.0,500.0,8.3,3.6,6200.0,50.0,2000.0,12.0] # set the minimum and maximum values for plotting
flabel_new = ['Well (ID)','X (m)','Y (m)','Depth (m)','Porosity (fraction)','Permeability (mD)','Acoustic Impedance (kg/m2s*10^6)','Facies (categorical)',
'Density (g/cm^3)','Compressible velocity (m/s)','Youngs modulus (GPa)', 'Shear velocity (m/s)', 'Shear modulus (GPa)'] # set the names for plotting
ftitle_new = ['Well','X','Y','Depth','Porosity','Permeability','Acoustic Impedance','Facies',
'Density','Compressible velocity','Youngs modulus', 'Shear velocity', 'Shear modulus']
elif idata == 2:
df_new = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/res21_2D_wells.csv') # load data from Dr. Pyrcz's GitHub repository
df_new.drop(['Well_ID','X','Y','CumulativeOil'],axis=1,inplace=True) # remove Well Index, X and Y coordinates, and response feature
df_new = df_new.dropna(how='any',inplace=False)
features = df_new.columns.values.tolist() # store the names of the features
xmin_new = [1,0.0,0.0,4.0,0.0,6.5,1.4,1600.0,10.0,1300.0,1.6]; xmax_new = [73,10000.0,10000.0,19.0,500.0,8.3,3.6,6200.0,50.0,2000.0,12.0] # set the minimum and maximum values for plotting
flabel_new = ['Well (ID)','X (m)','Y (m)','Depth (m)','Porosity (fraction)','Permeability (mD)','Acoustic Impedance (kg/m2s*10^6)','Facies (categorical)',
'Density (g/cm^3)','Compressible velocity (m/s)','Youngs modulus (GPa)', 'Shear velocity (m/s)', 'Shear modulus (GPa)'] # set the names for plotting
ftitle_new = ['Well','X','Y','Depth','Porosity','Permeability','Acoustic Impedance','Facies',
'Density','Compressible velocity','Youngs modulus', 'Shear velocity', 'Shear modulus']
df_new[df_new.columns] = MinMaxScaler().fit_transform(df_new) # min/max normalize all the features
df_new.head(n=13)
| Por | Perm | AI | Brittle | TOC | VR | |
|---|---|---|---|---|---|---|
| 0 | 0.325294 | 0.204805 | 0.453731 | 0.960076 | 0.569620 | 0.711340 |
| 1 | 0.342941 | 0.274600 | 0.579104 | 0.480038 | 0.455696 | 0.489691 |
| 2 | 0.439412 | 0.167048 | 0.814925 | 0.842894 | 0.455696 | 0.922680 |
| 3 | 0.654118 | 0.643021 | 0.402985 | 0.393378 | 0.535865 | 0.489691 |
| 4 | 0.645294 | 0.393593 | 0.567164 | 0.000000 | 0.717300 | 0.500000 |
| 5 | 0.469412 | 0.421053 | 0.420896 | 0.581278 | 0.476793 | 0.381443 |
| 6 | 0.408235 | 0.282609 | 0.492537 | 0.719035 | 0.417722 | 0.474227 |
| 7 | 0.295882 | 0.217391 | 0.588060 | 0.573103 | 0.371308 | 0.515464 |
| 8 | 0.351176 | 0.181922 | 0.343284 | 0.747105 | 0.481013 | 0.541237 |
| 9 | 0.394118 | 0.321510 | 0.725373 | 0.752964 | 0.561181 | 0.886598 |
| 10 | 0.499412 | 0.372998 | 0.280597 | 0.683608 | 0.535865 | 0.432990 |
| 11 | 0.567059 | 0.591533 | 0.301493 | 0.519962 | 0.725738 | 0.479381 |
| 12 | 0.604118 | 0.490847 | 0.453731 | 0.759095 | 0.573840 | 0.541237 |
Perform Cluster Analysis#
Now calculate the silhouette plot to calculate a good number of categories and perform K-means clustering with that ‘K’.
max_K = min(len(df_new)-1,20) # maximum number of clusters, K
silhouette = []
for k in range(2,max_K+1): # loop over number of clusters and store the inertia
kmeans_iter = KMeans(n_clusters=k, random_state=14, n_init = 10).fit(df_new.values)
score = silhouette_score(df_new.values, kmeans_iter.labels_)
silhouette.append(score)
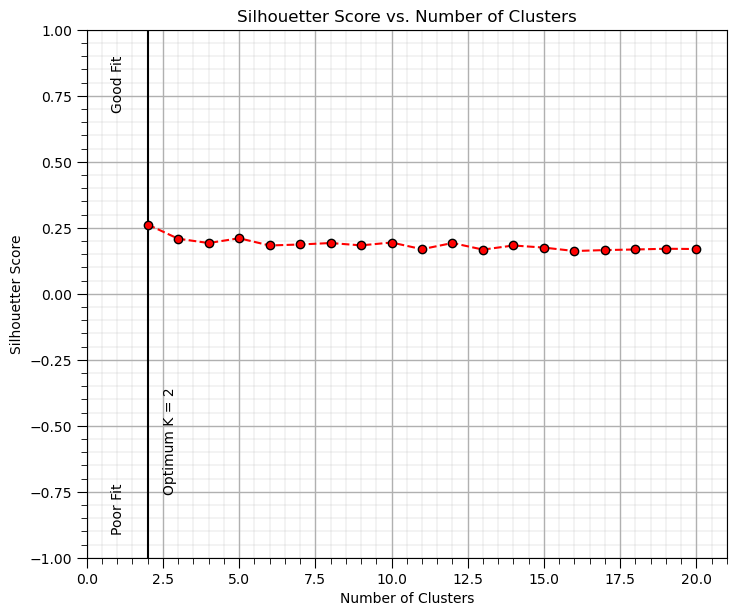
optimal_k = np.argmax(silhouette) + 2
kmeans = KMeans(n_clusters=optimal_k, random_state=seed, n_init = 100).fit(df_new.values) # k-means clustering
df_new['Kmeans'] = kmeans.labels_ + 1
plt.subplot(111)
plt.scatter(range(2,max_K+1),silhouette,c='red',edgecolor='black',zorder=10)
plt.annotate('Good Fit',[0.8,0.7],rotation = 90); plt.annotate('Poor Fit',[0.8,-0.9],rotation = 90)
plt.plot(range(2,max_K+1),silhouette,c='red',ls='--',zorder=1)
plt.xlim(2,max_K); plt.xlabel('Number of Clusters'); plt.ylabel('Silhouetter Score'); plt.ylim(bottom=0)
plt.vlines(optimal_k,-1,1,color='black'); plt.annotate('Optimum K = ' + str(optimal_k),[optimal_k+0.5,-0.75],rotation=90.0)
plt.grid(True); plt.title('Silhouetter Score vs. Number of Clusters')
plt.xlim([0,max_K+1]); plt.ylim([-1,1]); add_grid()
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.2, hspace=0.2); plt.show()
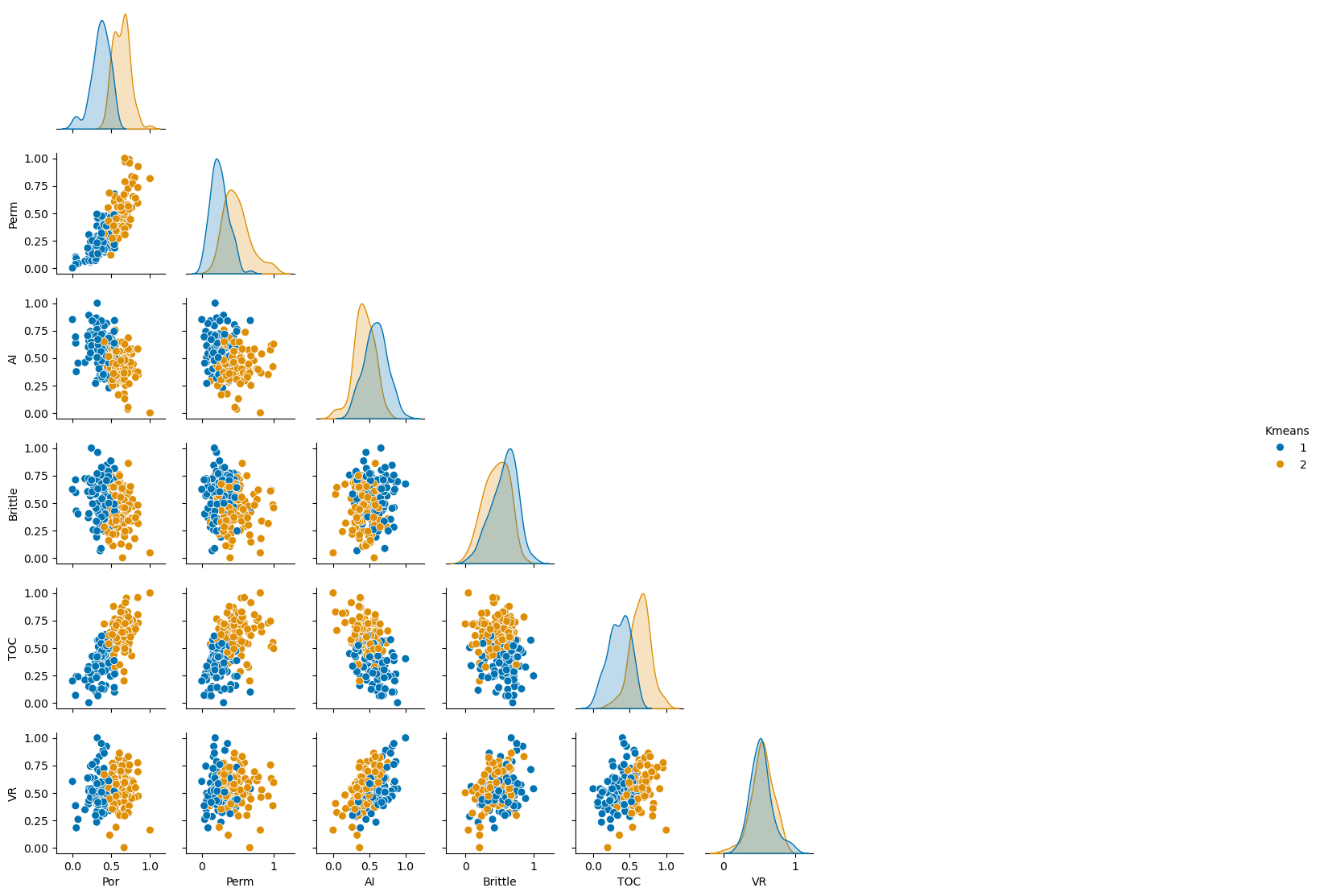
Visualize the Clusters#
Now let’s visualize the clusters with a matrix scatter plot.
sns.pairplot(df_new.iloc[:,:], hue="Kmeans", plot_kws={'alpha':1.0,'s':50}, palette = 'colorblind', corner=True) # matrix scatter plot
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.6, top=0.7, wspace=0.2, hspace=0.2); plt.show()
Save the Clusters#
Now we can choose to write out the DataFrame with the clusters.
save_clusters = False # save the imputed DataFrame?
if save_clusters == True:
folder = r'C:\Local'
file_name = r'dataframe_cluster.csv'
df_new.to_csv(folder + "/" + file_name, index=False)
About the Author#

Michael Pyrcz is a professor in the Cockrell School of Engineering, and the Jackson School of Geosciences, at The University of Texas at Austin, where he researches and teaches subsurface, spatial data analytics, geostatistics, and machine learning. Michael is also,
the principal investigator of the Energy Analytics freshmen research initiative and a core faculty in the Machine Learn Laboratory in the College of Natural Sciences, The University of Texas at Austin
an associate editor for Computers and Geosciences, and a board member for Mathematical Geosciences, the International Association for Mathematical Geosciences.
Michael has written over 70 peer-reviewed publications, a Python package for spatial data analytics, co-authored a textbook on spatial data analytics, Geostatistical Reservoir Modeling and author of two recently released e-books, Applied Geostatistics in Python: a Hands-on Guide with GeostatsPy and Applied Machine Learning in Python: a Hands-on Guide with Code.
All of Michael’s university lectures are available on his YouTube Channel with links to 100s of Python interactive dashboards and well-documented workflows in over 40 repositories on his GitHub account, to support any interested students and working professionals with evergreen content. To find out more about Michael’s work and shared educational resources visit his Website.
Want to Work Together?#
I hope this content is helpful to those that want to learn more about subsurface modeling, data analytics and machine learning. Students and working professionals are welcome to participate.
Want to invite me to visit your company for training, mentoring, project review, workflow design and / or consulting? I’d be happy to drop by and work with you!
Interested in partnering, supporting my graduate student research or my Subsurface Data Analytics and Machine Learning consortium (co-PI is Professor John Foster)? My research combines data analytics, stochastic modeling and machine learning theory with practice to develop novel methods and workflows to add value. We are solving challenging subsurface problems!
I can be reached at mpyrcz@austin.utexas.edu.
I’m always happy to discuss,
Michael
Michael Pyrcz, Ph.D., P.Eng. Professor, Cockrell School of Engineering and The Jackson School of Geosciences, The University of Texas at Austin
More Resources Available at: Twitter | GitHub | Website | GoogleScholar | Book | YouTube | Applied Geostats in Python e-book | LinkedIn
Comments#
This was a basic treatment of cluster analysis. Much more could be done and discussed, I have many more resources. Check out my shared resource inventory and the YouTube lecture links at the start of this chapter with resource links in the videos’ descriptions.
I hope this is helpful,
Michael