

k-nearest Neighbours#
Michael J. Pyrcz, Professor, The University of Texas at Austin
Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Chapter of e-book “Applied Machine Learning in Python: a Hands-on Guide with Code”.
Cite this e-Book as:
Pyrcz, M.J., 2024, Applied Machine Learning in Python: A Hands-on Guide with Code [e-book]. Zenodo. doi:10.5281/zenodo.15169138 ![]()
The workflows in this book and more are available here:
Cite the MachineLearningDemos GitHub Repository as:
Pyrcz, M.J., 2024, MachineLearningDemos: Python Machine Learning Demonstration Workflows Repository (0.0.3) [Software]. Zenodo. DOI: 10.5281/zenodo.13835312. GitHub repository: GeostatsGuy/MachineLearningDemos ![]()
By Michael J. Pyrcz
© Copyright 2024.
This chapter is a tutorial for / demonstration of k-nearest Neighbours.
YouTube Lecture: check out my lectures on:
These lectures are all part of my Machine Learning Course on YouTube with linked well-documented Python workflows and interactive dashboards. My goal is to share accessible, actionable, and repeatable educational content. If you want to know about my motivation, check out Michael’s Story.
Motivations for k-nearest Neighbours Regression#
There are many good reasons to cover k-nearest neighbours regression. In addition to being a simple, interpretable and flexible predictive machine learning model, it also demonstrates important concepts,
non-parametric predictive model - that learns the form of the relationships from the data, i.e., no prior assumption about the form of the relationship
instance-based, lazy learning - model training is postponed until prediction is required, no precalculation of the model. i.e., prediction requires access to the data
hyperparameter tuning - with a understandable hyperparameters that control model fit
very flexible, versatile predictive model - performs well in many situations
Convolution#
In fact, k-nearest neighbours is analogous to spatial estimation through weighted averaging within a local neighbourhood.

The k-nearest neighbours approach is similar to a convolution approach for spatial interpolation. Convolution is the integral product of two functions, after one is reversed and shifted by \(\tau\).
one interpretation is smoothing a function with weighting function, \(𝑓(\Delta)\), is applied to calculate the weighted average of function, \(𝑔(x)\),
this easily extends into multidimensional
The choice of which function is shifted before integration does not change the result, the convolution operator has commutativity,
if either function is reflected then convolution is equivalent to cross-correlation, measure of similarity between 2 signals as a function of displacement.
To demonstrate convolution with an exhaustive \(g(x)\) and sparsely sampled \(g(x)\) I built out an interactive Python convolution dashboard,
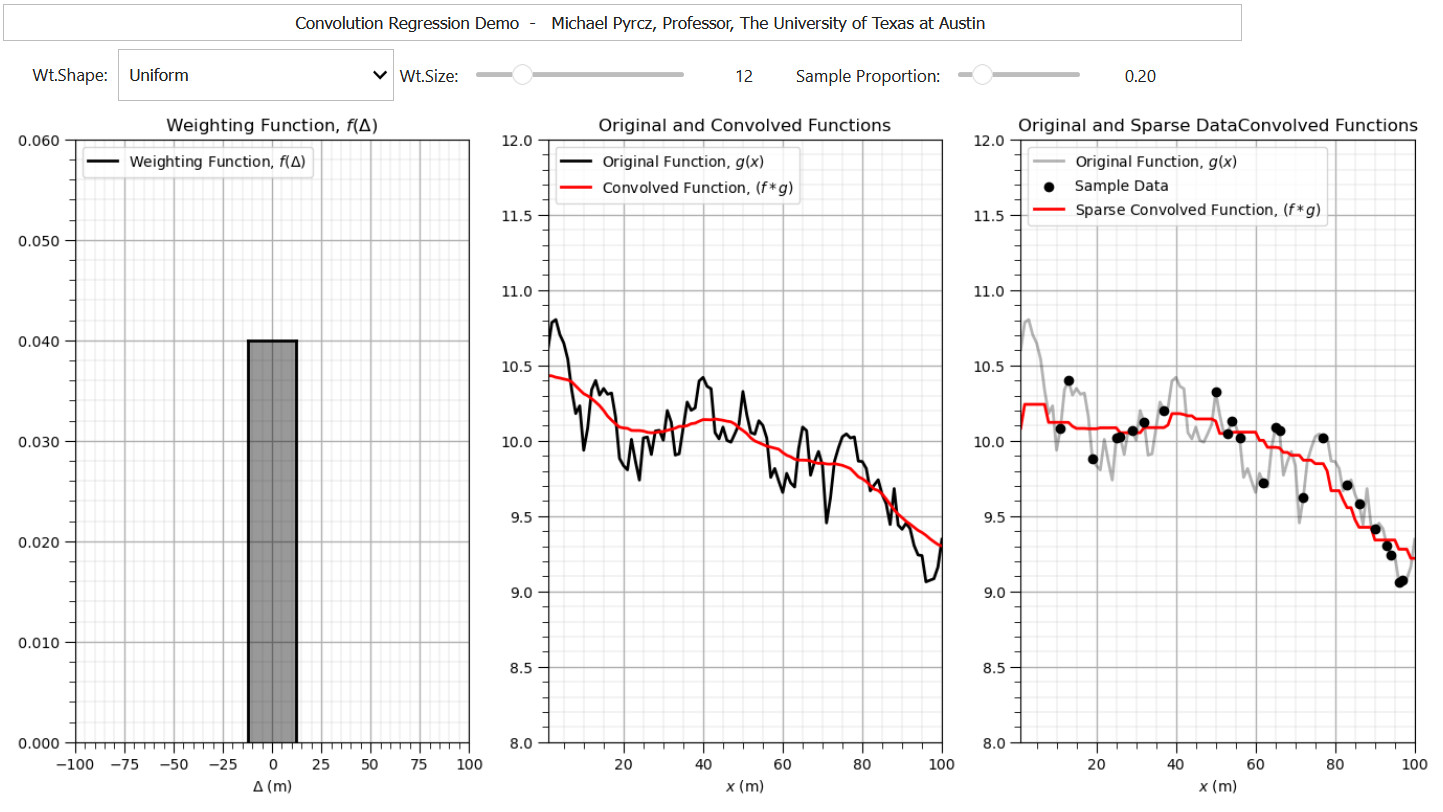
This is a good time to load our libraries.
Load the Required Libraries#
We will also need some standard packages. These should have been installed with Anaconda 3.
%matplotlib inline
suppress_warnings = True
import os # to set current working directory
import math # square root operator
import numpy as np # arrays and matrix math
import scipy.stats as st # statistical methods
import pandas as pd # DataFrames
import pandas.plotting as pd_plot
import matplotlib.pyplot as plt # for plotting
from matplotlib.ticker import (MultipleLocator,AutoMinorLocator,FuncFormatter) # control of axes ticks
from matplotlib.colors import ListedColormap # custom color maps
import seaborn as sns # for matrix scatter plots
from sklearn import metrics # measures to check our models
from sklearn.preprocessing import StandardScaler # standardize the features
from sklearn.neighbors import KNeighborsRegressor # for nearest k neighbours
from sklearn import metrics # measures to check our models
from sklearn.model_selection import (cross_val_score,train_test_split,GridSearchCV,KFold) # model tuning
from scipy.ndimage import convolve1d # exhaustive data convolution
from sklearn.pipeline import (Pipeline,make_pipeline) # machine learning modeling pipeline
import astropy.convolution.convolve as astroconvolve # sparse data convolution
from IPython.display import display, HTML # custom displays
cmap = plt.cm.inferno # default color bar, no bias and friendly for color vision defeciency
plt.rc('axes', axisbelow=True) # grid behind plotting elements
if suppress_warnings == True:
import warnings # suppress any warnings for this demonstration
warnings.filterwarnings('ignore')
seed = 13 # random number seed for workflow repeatability
If you get a package import error, you may have to first install some of these packages. This can usually be accomplished by opening up a command window on Windows and then typing ‘python -m pip install [package-name]’. More assistance is available with the respective package docs.
Demonstrations of Convolution#
Let’s code up a simple demonstration of 1D convolution.
I include following parameters for the demonstration,
kr = 5; kloc = 45 # kernel radius, kernel location for example point
where kr is the radius of the convolution window in cells not including the center cell, so for \(kr = 1\) the convolution window is 3 cells and \(kr = 5\) the convolution window is 11 cells, and kloc is the location of the highlighted convolution case, just for visualization.
seed = 73073 # random number seed
kr = 10; kloc = 45 # kernel radius, kernel location for example point
df_denpor = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/1D_por_perm_smooth.csv') # load data from Dr. Pyrcz's GitHub
plt.subplot(121)
plt.plot(df_denpor['Por'],df_denpor['Depth'],color='black',label='f(x)'); plt.ylabel('Depth (m)'); plt.xlabel('Porosity (%)')
plt.ylim([100,0]); plt.xlim([2,22]); plt.title('Exhaustive Case: Original and Convolved Function'); plt.yticks(np.arange(100, -1, -5));
size = 2 * kr + 1 # make uniform kernel
kernel = np.ones(size) / size # normalize kernel to sum to one for unbiasedness
convolved = np.convolve(df_denpor['Por'].values, kernel, mode='same') # convolution
k = len(kernel)
trim = k // 2 # how many values to trim from each edge
convolved_valid = convolved[trim:-trim] if trim > 0 else convolved
depth_valid = df_denpor['Depth'].values[trim:-trim] if trim > 0 else df_denpor['Depth'].values
convolved_pt = convolved_valid[np.abs(depth_valid - kloc).argmin()]; depth_pt = depth_valid[np.abs(depth_valid - kloc).argmin()]
plt.plot(convolved_valid,depth_valid,color='red',label=r'$(f * g)(x)$'); plt.ylabel('Depth (m)'); plt.xlabel('Porosity (%)');
plt.ylim([100,0]); plt.xlim([2,22]); plt.legend(loc='lower left'); plt.plot([2,22],[depth_pt,depth_pt],color='red',ls='--')
plt.scatter(convolved_pt,depth_pt,color='red',marker='o',edgecolor='black',zorder=10)
plt.subplot(122)
plt.plot(kernel,np.linspace(-1*kr+kloc,kr+kloc,2*kr+1),color='black',label=r'$g(\tau)$'); plt.xlim(0.35,0.0); plt.ylim([100,0]);
plt.yticks(np.arange(100, -1, -5)); plt.plot([kernel[0],0.0],[-1*kr+kloc,-1*kr+kloc],color='black');
plt.plot([kernel[0],0.0],[kr+kloc,kr+kloc],color='black'); plt.legend(loc='lower left'); plt.title('Kernel')
plt.plot([0.35,0.0],[depth_pt,depth_pt],color='red',ls='--'); plt.ylabel('Depth (m)'); plt.xlabel('Weight (unitless)')
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.5, top=1.2, wspace=0.2, hspace=0.2); plt.show()
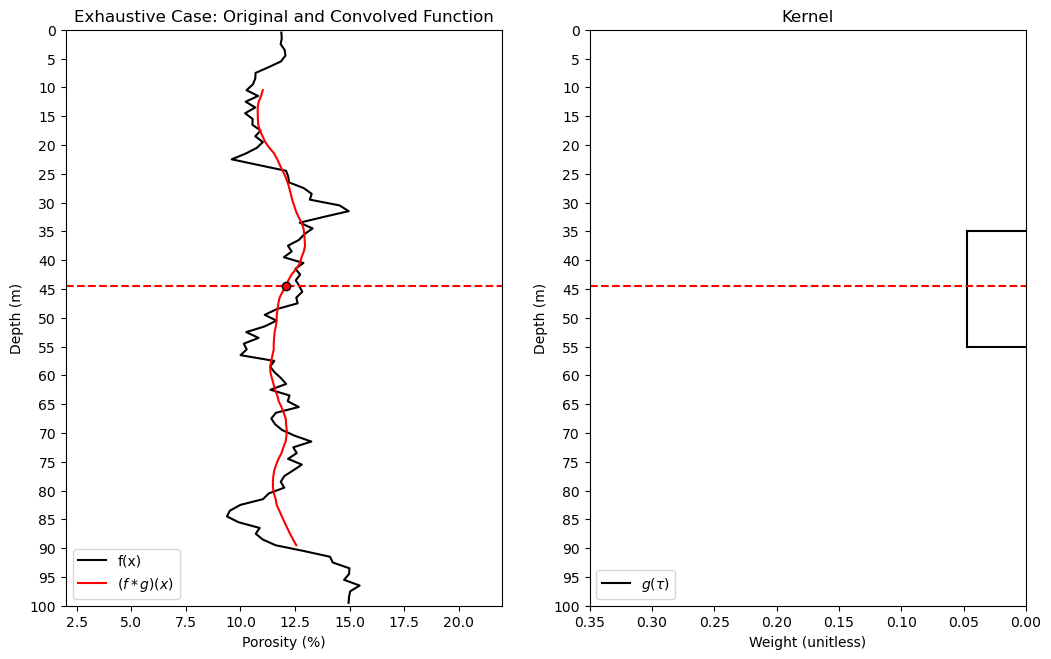
Now let’s demonstrate convolution with sparse data, samples instead of a grid of exhaustive values.
to perform sparse data convolution we use the astropy Python package.
frac = 0.2
df_denpor['Por_Sparse'] = df_denpor['Por'].copy()
np.random.seed(seed = seed)
nan_indices = np.random.choice(len(df_denpor), size=int(len(df_denpor)*(1.0-frac)), replace=False)
df_denpor.loc[nan_indices, 'Por_Sparse'] = np.nan
plt.subplot(121)
plt.scatter(df_denpor['Por_Sparse'],df_denpor['Depth'],color='black',label='f(x) Sparse'); plt.ylabel('Depth (m)'); plt.xlabel('Porosity (%)')
plt.plot(df_denpor['Por'],df_denpor['Depth'],color='black',alpha=0.3,label='f(x) Exhaustive');
plt.ylim([26,0]); plt.xlim([2,22]); plt.title('Sparse Case: Original and Convolved Function'); plt.yticks(np.arange(100, -1, -5));
size = 2 * kr + 1 # make uniform kernel
kernel = np.ones(size) / size # normalize kernel to sum to one for unbiasedness
convolved = astroconvolve(df_denpor['Por_Sparse'].values,kernel,boundary='extend',nan_treatment='interpolate',normalize_kernel=True) # convolve
k = len(kernel)
trim = k // 2 # how many values to trim from each edge
convolved_valid = convolved[trim:-trim] if trim > 0 else convolved
depth_valid = df_denpor['Depth'].values[trim:-trim] if trim > 0 else df_denpor['Depth'].values
convolved_pt = convolved_valid[np.abs(depth_valid - kloc).argmin()]; depth_pt = depth_valid[np.abs(depth_valid - kloc).argmin()]
plt.plot(convolved_valid,depth_valid,color='red',label=r'$(f * g)(x)$'); plt.ylabel('Depth (m)'); plt.xlabel('Porosity (%)');
plt.ylim([100,0]); plt.xlim([2,22]); plt.legend(loc='lower left'); plt.plot([2,22],[depth_pt,depth_pt],color='red',ls='--')
plt.scatter(convolved_pt,depth_pt,color='red',marker='o',edgecolor='black',zorder=10)
plt.subplot(122)
plt.plot(kernel,np.linspace(-1*kr+kloc,kr+kloc,2*kr+1),color='black',label=r'$g(\tau)$'); plt.xlim(0.35,0.0); plt.ylim([100,0]);
plt.yticks(np.arange(100, -1, -5)); plt.plot([kernel[0],0.0],[-1*kr+kloc,-1*kr+kloc],color='black');
plt.plot([kernel[0],0.0],[kr+kloc,kr+kloc],color='black'); plt.legend(loc='lower left'); plt.title('Kernel')
plt.plot([0.35,0.0],[depth_pt,depth_pt],color='red',ls='--'); plt.ylabel('Depth (m)'); plt.xlabel('Weight (unitless)')
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.5, top=1.2, wspace=0.2, hspace=0.2); plt.show()
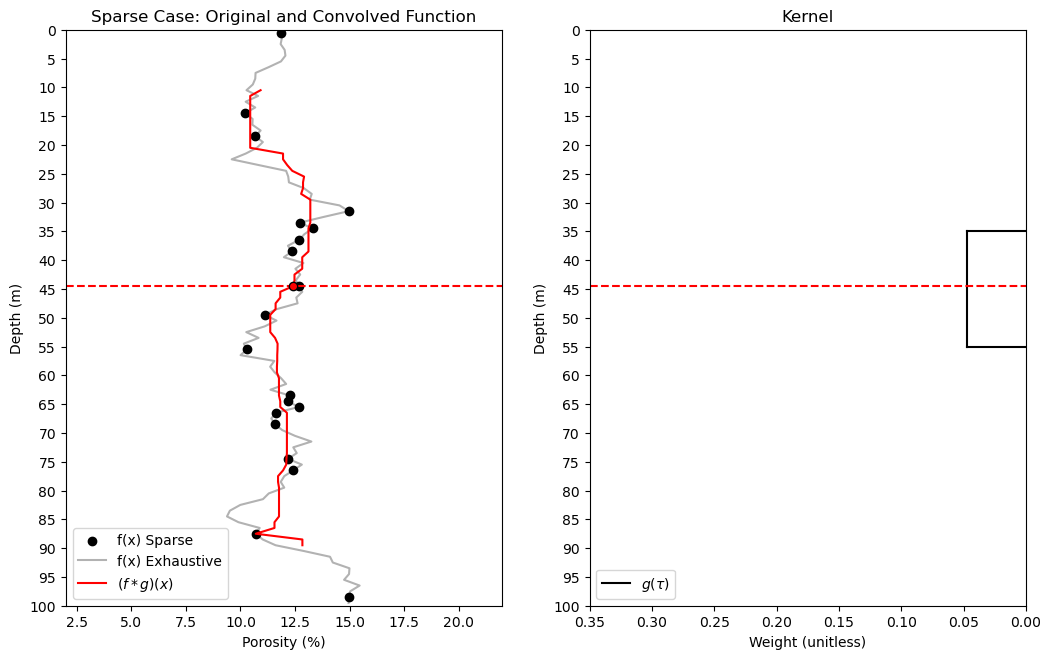
We can observe jumps in the convolved result due to the combination of,
uniform kernel
sparse data
the discontinuities in the convolved values can be improved with a distance weighted kernel.
plt.subplot(121)
plt.scatter(df_denpor['Por_Sparse'],df_denpor['Depth'],color='black',label='f(x) Sparse'); plt.ylabel('Depth (m)'); plt.xlabel('Porosity (%)')
plt.plot(df_denpor['Por'],df_denpor['Depth'],color='black',alpha=0.3,label='f(x) Exhaustive');
plt.ylim([26,0]); plt.xlim([2,22]); plt.title('Sparse Case: Original and Convolved Function'); plt.yticks(np.arange(100, -1, -5));
size = 2 * kr + 1 # make inverse distance kernel
d = np.arange(-kr, kr + 1, dtype=float)
kernel = 1 / np.abs(d)
kernel[kr] = 1.0 # center element (distance = 0)
kernel = kernel / np.sum(kernel) # normalize kernel to sum to one for unbiasedness
convolved = astroconvolve(df_denpor['Por_Sparse'].values,kernel,boundary='extend',nan_treatment='interpolate',normalize_kernel=True) # convolve
k = len(kernel)
trim = k // 2 # how many values to trim from each edge
convolved_valid = convolved[trim:-trim] if trim > 0 else convolved
depth_valid = df_denpor['Depth'].values[trim:-trim] if trim > 0 else df_denpor['Depth'].values
convolved_pt = convolved_valid[np.abs(depth_valid - kloc).argmin()]; depth_pt = depth_valid[np.abs(depth_valid - kloc).argmin()]
plt.plot(convolved_valid,depth_valid,color='red',label=r'$(f * g)(x)$'); plt.ylabel('Depth (m)'); plt.xlabel('Porosity (%)');
plt.ylim([100,0]); plt.xlim([2,22]); plt.legend(loc='lower left'); plt.plot([2,22],[depth_pt,depth_pt],color='red',ls='--')
plt.scatter(convolved_pt,depth_pt,color='red',marker='o',edgecolor='black',zorder=10)
plt.subplot(122)
plt.plot(kernel,np.linspace(-1*kr+kloc,kr+kloc,2*kr+1),color='black',label=r'$g(\tau)$'); plt.xlim(0.35,0.0); plt.ylim([100,0]);
plt.yticks(np.arange(100, -1, -5)); plt.plot([kernel[0],0.0],[-1*kr+kloc,-1*kr+kloc],color='black');
plt.plot([kernel[0],0.0],[kr+kloc,kr+kloc],color='black'); plt.legend(loc='lower left'); plt.title('Kernel')
plt.plot([0.35,0.0],[depth_pt,depth_pt],color='red',ls='--'); plt.ylabel('Depth (m)'); plt.xlabel('Weight (unitless)')
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.5, top=1.2, wspace=0.2, hspace=0.2); plt.show()
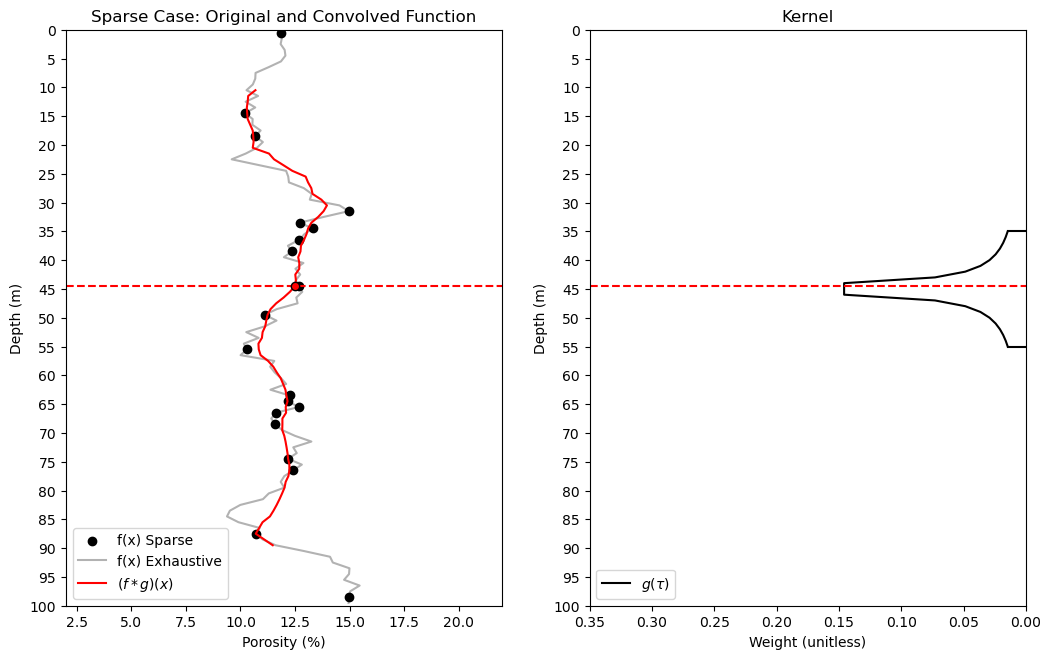
It is useful to review and discuss convolution as it introduces important concepts that we can used with \(k\) nearest neighbours,
kernel size - larger the window over which we gather training data, the smoother the model
kernel shape - uniform may cause jumps in the solution, while tapered can smooth these out
but, k-nearest neighbours departs from convolution with the specification of \(k\) nearest neighbours to include in the weighted average,
specifying \(k\) results in a locally adaptive window size, the local neighbourhood extends far enough to find \(k\) training data

k-nearest Neighbours Hyperparameters#
Now let’s discuss the k-nearest neighbours hyperparameters.
k number of nearest data - to utilize for prediction
data weighting - for example uniform weighting (use local training data average), inverse distance weighting
Note, for the case of inverse distance weighting, the method is analogous to inverse distance weighted interpolation with a maximum number of local data constraint commonly applied for spatial interpolation. Inverse distance is available in GeostatsPy for spatial mapping.
Distance Metric - training data within the predictor feature space are ranked by distance, closest to farthest, a variety of distance metrics may be applied, including:
Euclidian distance
\begin{equation}
d_i = \sqrt{\sum_{\alpha = 1}^{m} \left(x_{\alpha,i} - x_{\alpha,0}\right)^2}
\end{equation}
Minkowski Distance - a generalized form of distance with well-known Manhattan and Euclidean distances are special cases,
when \(p=2\), this becomes the Euclidean distance
when \(p=1\) it becomes the Manhattan distance
Declare Functions#
Let’s define a couple of functions to streamline plotting correlation matrices, visualization of a decision tree regression model, and the addition specified percentiles and major and minor gridlines to our plots.
def comma_format(x, pos):
return f'{int(x):,}'
def feature_rank_plot(pred,metric,mmin,mmax,nominal,title,ylabel,mask): # feature ranking plot
mpred = len(pred); mask_low = nominal-mask*(nominal-mmin); mask_high = nominal+mask*(mmax-nominal); m = len(pred) + 1
plt.plot(pred,metric,color='black',zorder=20)
plt.scatter(pred,metric,marker='o',s=10,color='black',zorder=100)
plt.plot([-0.5,m-1.5],[0.0,0.0],'r--',linewidth = 1.0,zorder=1)
plt.fill_between(np.arange(0,mpred,1),np.zeros(mpred),metric,where=(metric < nominal),interpolate=True,color='dodgerblue',alpha=0.3)
plt.fill_between(np.arange(0,mpred,1),np.zeros(mpred),metric,where=(metric > nominal),interpolate=True,color='lightcoral',alpha=0.3)
plt.fill_between(np.arange(0,mpred,1),np.full(mpred,mask_low),metric,where=(metric < mask_low),interpolate=True,color='blue',alpha=0.8,zorder=10)
plt.fill_between(np.arange(0,mpred,1),np.full(mpred,mask_high),metric,where=(metric > mask_high),interpolate=True,color='red',alpha=0.8,zorder=10)
plt.xlabel('Predictor Features'); plt.ylabel(ylabel); plt.title(title)
plt.ylim(mmin,mmax); plt.xlim([-0.5,m-1.5]); add_grid();
return
def plot_corr(corr_matrix,title,limits,mask): # plots a graphical correlation matrix
my_colormap = plt.get_cmap('RdBu_r', 256)
newcolors = my_colormap(np.linspace(0, 1, 256))
white = np.array([256/256, 256/256, 256/256, 1])
white_low = int(128 - mask*128); white_high = int(128+mask*128)
newcolors[white_low:white_high, :] = white # mask all correlations less than abs(0.8)
newcmp = ListedColormap(newcolors)
m = corr_matrix.shape[0]
im = plt.matshow(corr_matrix,fignum=0,vmin = -1.0*limits, vmax = limits,cmap = newcmp)
plt.xticks(range(len(corr_matrix.columns)), corr_matrix.columns); ax = plt.gca()
ax.xaxis.set_label_position('bottom'); ax.xaxis.tick_bottom()
plt.yticks(range(len(corr_matrix.columns)), corr_matrix.columns)
cbar = plt.colorbar(im, orientation = 'vertical')
cbar.ax.yaxis.set_major_formatter(FuncFormatter(comma_format))
plt.title(title)
for i in range(0,m):
plt.plot([i-0.5,i-0.5],[-0.5,m-0.5],color='black')
plt.plot([-0.5,m-0.5],[i-0.5,i-0.5],color='black')
plt.ylim([-0.5,m-0.5]); plt.xlim([-0.5,m-0.5])
def visualize_model(model,xfeature,x_min,x_max,yfeature,y_min,y_max,response,z_min,z_max,title,axes_commas = True): # plots the data points and the decision tree prediction
n_classes = 10
cmap_temp = plt.cm.inferno
xplot_step = (x_max-x_min)/100; yplot_step = (y_max-y_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, xplot_step),
np.arange(y_min, y_max, yplot_step))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=cmap_temp,vmin=z_min, vmax=z_max, levels=np.linspace(z_min, z_max, 100))
im = plt.scatter(xfeature,yfeature,s=30, c=response, marker=None, cmap=cmap_temp, norm=None, vmin=z_min, vmax=z_max,
alpha=1.0, linewidths=0.8, edgecolors="black",zorder=10)
plt.scatter(xfeature,yfeature,s=60, c='white', marker=None, cmap=cmap_temp, norm=None, vmin=z_min, vmax=z_max,
alpha=1.0, linewidths=0.8, edgecolors=None,zorder=8)
plt.title(title); plt.xlabel(xfeature.name); plt.ylabel(yfeature.name)
cbar = plt.colorbar(im, orientation = 'vertical'); cbar.set_label(response.name, rotation=270, labelpad=20)
cbar.ax.yaxis.set_major_formatter(FuncFormatter(comma_format))
if axes_commas == True:
plt.gca().xaxis.set_major_formatter(FuncFormatter(comma_format))
plt.gca().yaxis.set_major_formatter(FuncFormatter(comma_format))
return Z
def visualize_tuned_model(k_tuned,k_mat,score_mat):
plt.scatter(k_mat,score_mat,s=10.0, c="red", marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=0.8,
linewidths=0.5, edgecolors="black")
plt.plot([k_tuned,k_tuned],[0,10000000],color='black',linestyle=(6, (2,3)),label='tuned',zorder=1)
plt.title('k-fold Cross Validation Error (MSE) vs. k Nearest Neighbours'); plt.xlabel('Number of Nearest Neighbours')
plt.ylabel('Mean Square Error')
plt.xlim(k_min,k_max); plt.ylim(0,np.max(score_mat))
def check_model(model,xtrain,ytrain,xtest,ytest,ymin,ymax,rtrain,rtest,title): # plots the estimated vs. the actual
predict_train = model.predict(np.c_[xtrain,ytrain])
predict_test = model.predict(np.c_[xtest,ytest])
plt.scatter(rtrain,predict_train,s=None, c='darkorange',marker=None, cmap=None, norm=None, vmin=None, vmax=None,
alpha=0.8, linewidths=0.8, edgecolors="black",label='Train')
plt.scatter(rtest,predict_test,s=None, c='red',marker=None, cmap=None, norm=None, vmin=None, vmax=None,
alpha=0.8, linewidths=0.8, edgecolors="black",label='Test')
plt.title(title); plt.xlabel('Actual Production (MCFPD)'); plt.ylabel('Estimated Production (MCFPD)')
plt.xlim(ymin,ymax); plt.ylim(ymin,ymax)
plt.arrow(ymin,ymin,ymax,ymax,width=0.02,color='black',head_length=0.0,head_width=0.0)
MSE_train = metrics.mean_squared_error(rtrain,predict_train)
Var_Explained_train = metrics.explained_variance_score(rtrain,predict_train)
cor_train = math.sqrt(metrics.r2_score(rtrain,predict_train))
MSE_test = metrics.mean_squared_error(rtest,predict_test)
plt.gca().xaxis.set_major_formatter(FuncFormatter(comma_format))
plt.gca().yaxis.set_major_formatter(FuncFormatter(comma_format))
plt.annotate('Train MSE: ' + str(f'{(np.round(MSE_train,2)):,}'),[0.05*(ymax-ymin)+ymin,0.95*(ymax-ymin)+ymin])
plt.annotate('Test MSE: ' + str(f'{(np.round(MSE_test,2)):,}'),[0.05*(ymax-ymin)+ymin,0.90*(ymax-ymin)+ymin])
add_grid(); plt.legend(loc='lower right')
# print('Mean Squared Error on Training = ', round(MSE_test,2),', Variance Explained =', round(Var_Explained,2),'Cor =', round(cor,2))
def weighted_percentile(data, weights, perc): # calculate weighted percentile (iambr on StackOverflow @ https://stackoverflow.com/questions/21844024/weighted-percentile-using-numpy/32216049)
ix = np.argsort(data)
data = data[ix]
weights = weights[ix]
cdf = (np.cumsum(weights) - 0.5 * weights) / np.sum(weights)
return np.interp(perc, cdf, data)
def histogram_bounds(values,weights,color): # add uncertainty bounds to a histogram
p10 = weighted_percentile(values,weights,0.1); avg = np.average(values,weights=weights); p90 = weighted_percentile(values,weights,0.9)
plt.plot([p10,p10],[0.0,45],color = color,linestyle='dashed')
plt.plot([avg,avg],[0.0,45],color = color)
plt.plot([p90,p90],[0.0,45],color = color,linestyle='dashed')
def add_grid():
plt.gca().grid(True, which='major',linewidth = 1.0); plt.gca().grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
def display_sidebyside(*args): # display DataFrames side-by-side (ChatGPT 4.0 generated Spet, 2024)
html_str = ''
for df in args:
html_str += df.head().to_html() # Using .head() for the first few rows
display(HTML(f'<div style="display: flex;">{html_str}</div>'))
Set the Working Directory#
I always like to do this so I don’t lose files and to simplify subsequent read and writes (avoid including the full address each time).
#os.chdir("c:/PGE383") # set the working directory
You will have to update the part in quotes with your own working directory and the format is different on a Mac (e.g. “~/PGE”).
Loading Tabular Data#
Here’s the command to load our comma delimited data file in to a Pandas’ DataFrame object.
Let’s load the provided multivariate, spatial dataset ‘unconv_MV.csv’. This dataset has variables from 1,000 unconventional wells including:
well average porosity
log transform of permeability (to linearize the relationships with other variables)
acoustic impedance (kg/m^3 x m/s x 10^6)
brittleness ratio (%)
total organic carbon (%)
vitrinite reflectance (%)
initial production 90 day average (MCFPD).
Note, the dataset is synthetic.
We load it with the pandas ‘read_csv’ function into a DataFrame we called ‘my_data’ and then preview it to make sure it loaded correctly.
Optional: Add Random Noise to the Response Feature#
We can do this to observe the impact of data noise on overfit and hyperparameter tuning.
This is for experiential learning, of course we wouldn’t add random noise to our data
We set the random number seed for reproducibility
df_load = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/unconv_MV_v4.csv') # load data from Dr. Pyrcz's GitHub
df_load = df_load.iloc[:,1:8] # copy all rows and columns 1 through 8, note 0 column is removed
response = 'Prod' # specify the response feature
add_noise = True # set True to add noise to response feature to demonstrate overfit
noise_stdev = 500 # amount of noise to add to response feature to demonstrate overfit
np.random.seed(seed = seed) # set the random number seed
if add_noise == True:
df_load[response] = df_load[response] + np.random.normal(loc=0.0,scale=noise_stdev,size = len(df_load))
X = df_load.copy(deep = False)
X = X.drop([response],axis='columns') # make predictor and response DataFrames
y = df_load.loc[:,response]
features = X.columns.values.tolist() + [y.name] # store the names of the features
pred = X.columns.values.tolist()
resp = [y.name]
Xmin = [6.0,0.0,1.0,10.0,0.0,0.9]; Xmax = [24.0,10.0,5.0,85.0,2.2,2.9] # set the minumum and maximum values for plotting
ymin = 1000.0; ymax = 9000.0
predlabel = ['Porosity (%)','Permeability (mD)','Acoustic Impedance (kg/m2s*10^6)','Brittleness Ratio (%)', # set the names for plotting
'Total Organic Carbon (%)','Vitrinite Reflectance (%)']
resplabel = 'Initial Production (MCFPD)'
predtitle = ['Porosity','Permeability','Acoustic Impedance','Brittleness Ratio', # set the units for plotting
'Total Organic Carbon','Vitrinite Reflectance']
resptitle = 'Initial Production'
featurelabel = predlabel + [resplabel] # make feature labels and titles for concise code
featuretitle = predtitle + [resptitle]
m = len(pred) + 1
mpred = len(pred)
df = pd.concat([X,y],axis=1) # make one DataFrame with both X and y (remove all other features)
Visualize the DataFrame#
Visualizing the DataFrame is useful first check of the data.
many things can go wrong, e.g., we loaded the wrong data, all the features did not load, etc.
We can preview by utilizing the ‘head’ DataFrame member function (with a nice and clean format, see below).
add parameter ‘n=13’ to see the first 13 rows of the dataset.
df.head(n=13)
| Por | Perm | AI | Brittle | TOC | VR | Prod | |
|---|---|---|---|---|---|---|---|
| 0 | 12.08 | 2.92 | 2.80 | 81.40 | 1.16 | 2.31 | 1310.036546 |
| 1 | 12.38 | 3.53 | 3.22 | 46.17 | 0.89 | 1.88 | 3382.396297 |
| 2 | 14.02 | 2.59 | 4.01 | 72.80 | 0.89 | 2.72 | 2518.403893 |
| 3 | 17.67 | 6.75 | 2.63 | 39.81 | 1.08 | 1.88 | 5652.465679 |
| 4 | 17.52 | 4.57 | 3.18 | 10.94 | 1.51 | 1.90 | 3399.441438 |
| 5 | 14.53 | 4.81 | 2.69 | 53.60 | 0.94 | 1.67 | 3837.089989 |
| 6 | 13.49 | 3.60 | 2.93 | 63.71 | 0.80 | 1.85 | 2279.013134 |
| 7 | 11.58 | 3.03 | 3.25 | 53.00 | 0.69 | 1.93 | 2843.427906 |
| 8 | 12.52 | 2.72 | 2.43 | 65.77 | 0.95 | 1.98 | 2496.015787 |
| 9 | 13.25 | 3.94 | 3.71 | 66.20 | 1.14 | 2.65 | 2600.916534 |
| 10 | 15.04 | 4.39 | 2.22 | 61.11 | 1.08 | 1.77 | 3955.833889 |
| 11 | 16.19 | 6.30 | 2.29 | 49.10 | 1.53 | 1.86 | 4868.823958 |
| 12 | 16.82 | 5.42 | 2.80 | 66.65 | 1.17 | 1.98 | 4421.655228 |
Summary Statistics for Tabular Data#
There are a lot of efficient methods to calculate summary statistics from tabular data in DataFrames. The describe command provides count, mean, minimum, maximum in a nice data table.
we have some negative TOC values! Let’s check the distribution.
df.describe().transpose() # calculate summary statistics for the data
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Por | 200.0 | 14.991150 | 2.971176 | 6.550000 | 12.912500 | 15.070000 | 17.402500 | 23.550000 |
| Perm | 200.0 | 4.330750 | 1.731014 | 1.130000 | 3.122500 | 4.035000 | 5.287500 | 9.870000 |
| AI | 200.0 | 2.968850 | 0.566885 | 1.280000 | 2.547500 | 2.955000 | 3.345000 | 4.630000 |
| Brittle | 200.0 | 48.161950 | 14.129455 | 10.940000 | 37.755000 | 49.510000 | 58.262500 | 84.330000 |
| TOC | 200.0 | 0.990450 | 0.481588 | -0.190000 | 0.617500 | 1.030000 | 1.350000 | 2.180000 |
| VR | 200.0 | 1.964300 | 0.300827 | 0.930000 | 1.770000 | 1.960000 | 2.142500 | 2.870000 |
| Prod | 200.0 | 3877.829073 | 1592.393141 | 841.518737 | 2681.399789 | 3585.028984 | 4867.418216 | 8093.026321 |
There are just a couple slightly negative values, let’s just truncate them at zero. We can use this command below to set all TOC values in the DataFrame that are less than 0.0 as 0.0, otherwise we keep the original TOC value.
num = df._get_numeric_data() # get the numerical values
num[num < 0] = 0 # truncate negative values to 0.0
df.describe().transpose() # calculate summary statistics for the data
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Por | 200.0 | 14.991150 | 2.971176 | 6.550000 | 12.912500 | 15.070000 | 17.402500 | 23.550000 |
| Perm | 200.0 | 4.330750 | 1.731014 | 1.130000 | 3.122500 | 4.035000 | 5.287500 | 9.870000 |
| AI | 200.0 | 2.968850 | 0.566885 | 1.280000 | 2.547500 | 2.955000 | 3.345000 | 4.630000 |
| Brittle | 200.0 | 48.161950 | 14.129455 | 10.940000 | 37.755000 | 49.510000 | 58.262500 | 84.330000 |
| TOC | 200.0 | 0.991950 | 0.478264 | 0.000000 | 0.617500 | 1.030000 | 1.350000 | 2.180000 |
| VR | 200.0 | 1.964300 | 0.300827 | 0.930000 | 1.770000 | 1.960000 | 2.142500 | 2.870000 |
| Prod | 200.0 | 3877.829073 | 1592.393141 | 841.518737 | 2681.399789 | 3585.028984 | 4867.418216 | 8093.026321 |
It is good that we checked the summary statistics.
there are no obvious issues
check out the range of values for each feature to set up and adjust plotting limits. See above.
Calculate the Correlation Matrix and Correlation with Response Ranking#
Let’s perform with correlation analysis. We can calculate and view the correlation matrix and correlation to the response features with these previously declared functions.
correlation analysis is based on the assumption of linear relationships, but it is a good start
corr_matrix = df.corr()
correlation = corr_matrix.iloc[:,-1].values[:-1]
plt.subplot(121)
plot_corr(corr_matrix,'Correlation Matrix',1.0,0.5) # using our correlation matrix visualization function
plt.xlabel('Features'); plt.ylabel('Features')
plt.subplot(122)
feature_rank_plot(pred,correlation,-1.0,1.0,0.0,'Feature Ranking, Correlation with ' + resp[0],'Correlation',0.5)
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=0.8, wspace=0.2, hspace=0.3); plt.show()
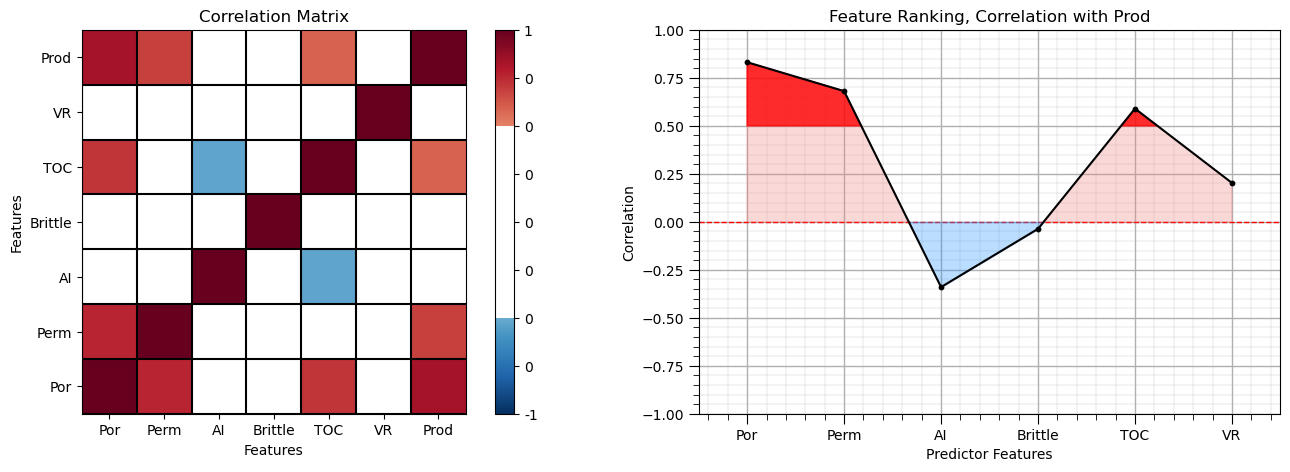
Note the 1.0 diagonal resulting from the correlation of each variable with themselves.
This looks good. There is a mix of correlation magnitudes. Of course, correlation coefficients are limited to degree of linear correlations.
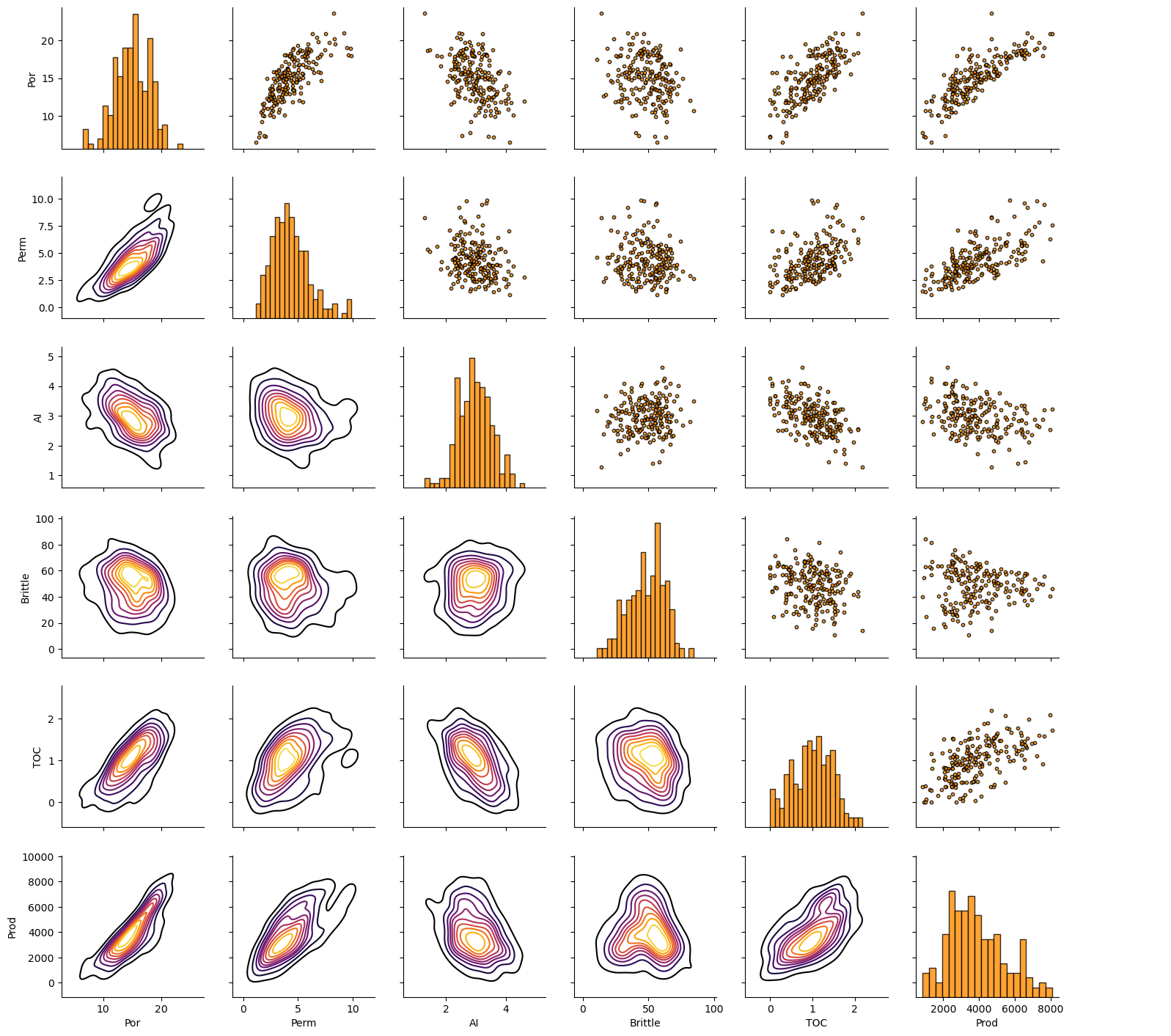
Let’s look at the matrix scatter plot to see the pairwise relationship between the features.
pairgrid = sns.PairGrid(df,vars=['Por','Perm','AI','Brittle','TOC','Prod']) # matrix scatter plots
pairgrid = pairgrid.map_upper(plt.scatter, color = 'darkorange', edgecolor = 'black', alpha = 0.8, s = 10)
pairgrid = pairgrid.map_diag(plt.hist, bins = 20, color = 'darkorange',alpha = 0.8, edgecolor = 'k')# Map a density plot to the lower triangle
pairgrid = pairgrid.map_lower(sns.kdeplot, cmap = plt.cm.inferno,
alpha = 1.0, n_levels = 10)
pairgrid.add_legend()
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.9, top=0.9, wspace=0.2, hspace=0.2); plt.show()
Train and Test Split and Standardizing Predictor Features#
The k-nearest neighbour method uses a nearest training sample search in feature space (like k-means clustering). To remove the impact feature range from the approach we standardize the predictor features.
we will standardize our predictor features to have a mean of zero and a variance of one.
we use the scikit-learn preprocessing module to simplify this step and provide a convenient and safe reverse transform
We fit the transform on training data only,
to avoid information leakage
we then apply the same transform to testing data (fit on training) data,
to ensure consistency and to avoid masking drift
if1, if2 = 0, 3 # select 2 predictor features for ease of data and model visualization
X_sel = X.iloc[:, [if1, if2]]
X_train, X_test, y_train, y_test = train_test_split(X_sel, y, test_size=0.25, random_state=seed) # train and test split
y_train = y_train.to_frame(); y_test = y_test.to_frame() # force as 1 column dataframes
scaler = StandardScaler()
sX_train = pd.DataFrame(
scaler.fit_transform(X_train),
columns=[f"s{c}" for c in X_train.columns],
index=X_train.index
)
sX_test = pd.DataFrame(
scaler.transform(X_test),
columns=[f"s{c}" for c in X_test.columns],
index=X_test.index
)
sel_pred = X_train.columns; sel_spred = sX_train.columns
X_train = pd.concat([X_train, sX_train], axis=1) ## combine original and standardized predictors
X_test = pd.concat([X_test, sX_test], axis=1)
sel_spredlabel = ['Standardized ' + element for element in predlabel] # standardized predictors label list
print('Selected Predictor Features: ' + str(sel_pred.values))
print('Standardized Selected Predictor Features: ' + str(sel_spred.values))
print('Response Feature: ' + str([resp[0]]))
df.head()
print(' Train DataFrame Test DataFrame')
display_sidebyside(X_train,X_test) # custom function for side-by-side DataFrame display
Selected Predictor Features: ['Por' 'Brittle']
Standardized Selected Predictor Features: ['sPor' 'sBrittle']
Response Feature: ['Prod']
Train DataFrame Test DataFrame
| Por | Brittle | sPor | sBrittle | |
|---|---|---|---|---|
| 4 | 17.52 | 10.94 | 0.849184 | -2.667354 |
| 41 | 15.40 | 46.29 | 0.133295 | -0.113225 |
| 196 | 17.99 | 44.32 | 1.007895 | -0.255562 |
| 146 | 15.80 | 42.13 | 0.268368 | -0.413795 |
| 165 | 16.61 | 60.13 | 0.541892 | 0.886751 |
| Por | Brittle | sPor | sBrittle | |
|---|---|---|---|---|
| 93 | 10.69 | 84.33 | -1.457194 | 2.635264 |
| 96 | 16.95 | 61.43 | 0.656704 | 0.980680 |
| 137 | 14.69 | 62.93 | -0.106460 | 1.089058 |
| 188 | 16.14 | 38.03 | 0.383181 | -0.710031 |
| 181 | 14.48 | 47.44 | -0.177374 | -0.030134 |
Let’s demonstrate the reverse transform from standardized features back to the original features.
we won’t need this in our workflow since the we only need to forward transform the predictor features to train the model and make predictions
print('Backtransformed: \n Por Brittle')
scaler.inverse_transform(sX_train)[:5,:] # check the reverse standardization
Backtransformed:
Por Brittle
array([[17.52, 10.94],
[15.4 , 46.29],
[17.99, 44.32],
[15.8 , 42.13],
[16.61, 60.13]])
We can compare the output above with the original porosity and brittleness. The reverse transform works!
We will use this method to return to original feature units when needed.
In general, the back transformation is not needed for predictor features, well only forward transform the predictor features to make predictions of the response feature.
In this example, we don’t need to transform the response feature while building our model. The response feature distribution is well-behaved and there is not theory in k-nearest neighbours that expects a specific range or distribution share for the response feature.
Feature Ranges#
Let’s set some ranges for plotting. Note for the standardized predictor features we use -3.0 to 3.0 as the limits.
Xmin = [5.0, 0.0]; Xmax = [25.0,100.0] # selected predictor features min and max
Let’s first check the univariate statistics of Porosity, Brittleness and Production.
nbins = 20 # number of histogram bins
plt.subplot(221)
plt.hist(X_train[sel_spred[0]],alpha = 0.8,color = 'darkorange',edgecolor = 'black',bins=np.linspace(-3,3,nbins),label='Train')
plt.hist(X_test[sel_spred[0]],alpha = 0.8,color = 'red',edgecolor = 'black',bins=np.linspace(-3,3,nbins),label='Test')
plt.title(sel_spred[0]); plt.xlim(-3,3); plt.xlabel(sel_spredlabel[0]); plt.ylabel('Frequency'); add_grid(); plt.legend(loc='upper right')
plt.subplot(222)
plt.hist(X_train[sel_spred[1]],alpha = 0.8,color = 'darkorange',edgecolor = 'black',bins=np.linspace(-3,3,nbins),label='Train')
plt.hist(X_test[sel_spred[1]],alpha = 0.8,color = 'red',edgecolor = 'black',bins=np.linspace(-3,3,nbins),label='Test')
plt.title(sel_spred[1]); plt.xlim(-3,3); plt.xlabel(sel_spredlabel[1]); plt.ylabel('Frequency'); add_grid(); plt.legend(loc='upper right')
plt.subplot(223)
plt.hist(y_train[resp],alpha = 0.8,color = 'darkorange',edgecolor = 'black',bins=np.linspace(ymin,ymax,nbins),label='Train')
plt.hist(y_test[resp],alpha = 0.8,color = 'red',edgecolor = 'black',bins=np.linspace(ymin,ymax,nbins),label='Test')
plt.legend(loc='upper right'); plt.title(resp[0]); plt.xlim(ymin,ymax)
plt.gca().xaxis.set_major_formatter(FuncFormatter(comma_format))
plt.xlabel(resplabel); plt.ylabel('Frequency'); add_grid()
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=2.1, wspace=0.2, hspace=0.2); plt.show()
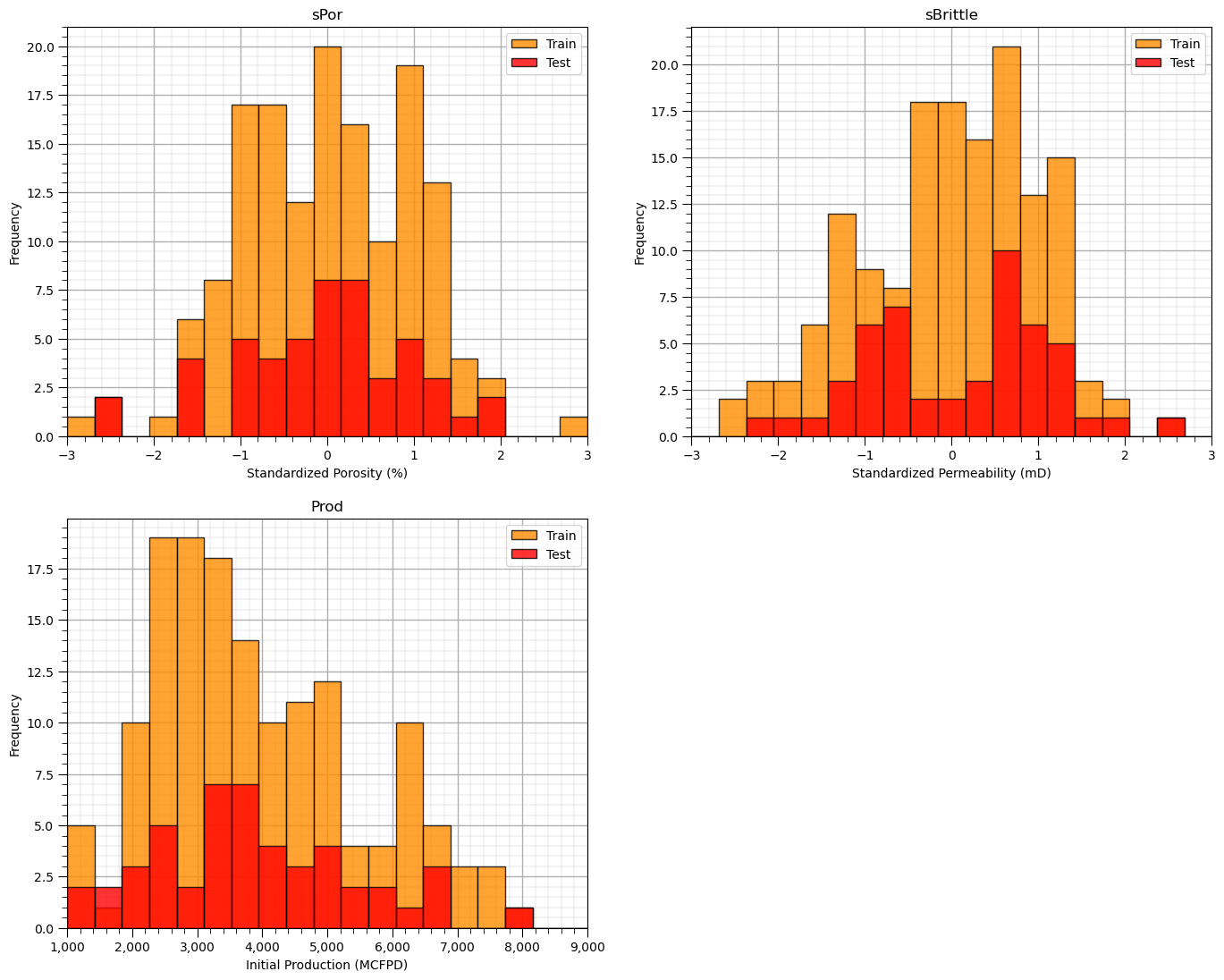
The distributions are well behaved,
we cannot observe obvious gaps nor truncations.
check coverage of the train and test data
Let’s look at a scatter plot of Porosity vs. Brittleness with points colored by Production.
plt.subplot(121) # train data plot
im = plt.scatter(X_train[sel_spred[0]],X_train[sel_spred[1]],s=None, c=y_train[resp[0]], marker=None, cmap=cmap, norm=None, vmin=ymin,
vmax=ymax, alpha=0.8, linewidths=0.3, edgecolors="black")
plt.title('Train ' + resp[0] + ' vs. ' + sel_spred[1] + ' and ' + sel_spred[1]); plt.xlabel(sel_spredlabel[0]); plt.ylabel(sel_spredlabel[1])
plt.xlim(-3,3); plt.ylim(-3,3)
cbar = plt.colorbar(im, orientation = 'vertical')
cbar.set_label(resplabel, rotation=270, labelpad=20)
cbar.ax.yaxis.set_major_formatter(FuncFormatter(comma_format))
add_grid()
plt.subplot(122) # test data plot
im = plt.scatter(X_test[sel_spred[0]],X_test[sel_spred[1]],s=None, c=y_test[resp[0]], marker=None, cmap=cmap, norm=None, vmin=ymin,
vmax=ymax, alpha=0.8, linewidths=0.3, edgecolors="black")
plt.title('Test ' + resp[0] + ' vs. ' + sel_spred[1] + ' and ' + sel_spred[1]); plt.xlabel(sel_spredlabel[0]); plt.ylabel(sel_spredlabel[1])
plt.xlim(-3,3); plt.ylim(-3,3)
cbar = plt.colorbar(im, orientation = 'vertical')
cbar.set_label(resplabel, rotation=270, labelpad=20)
cbar.ax.yaxis.set_major_formatter(FuncFormatter(comma_format))
add_grid()
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.2, wspace=0.2, hspace=0.2); plt.show()
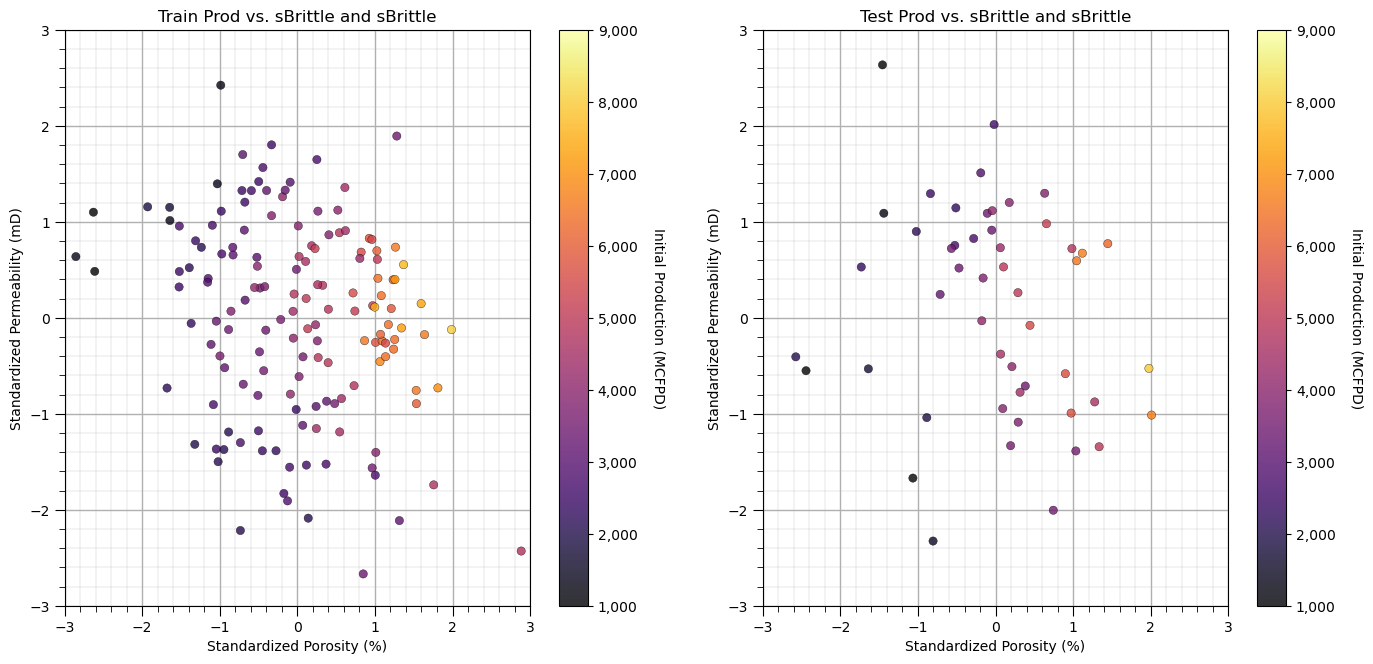
This problem looks nonlinear and could not be modeled with simple linear regression.
It appears there is a sweet spot for Brittleness and increasing Porosity is always beneficial for Production.
Instantiate, Fit and Predict with k-nearest Neighbour#
Let’s instantiate, fit and predict with a k-nearest neighbour model.
instantiate it with the hyperparameters, k-nearest neighbours
train with the training data, we use the standard fit function from scikit-learn
n_neighbours = 10; p = 2; weights = 'uniform' # model hyperparameters
neigh = KNeighborsRegressor(weights = weights, n_neighbors=n_neighbours, p = p) # instantiate the prediction model
We have set the hyperparameters:
weights = averaging weights for the prediction given the nearest neighbours. ‘uniform’ is arithmetic average, while ‘distance’ is inverse distance weighting.
n_neighbours = maximum number of neighbours. Note, we constrain our prediction by limiting it to 5 nearest neighbours.
p = distance metric power or Minkowski metric (1 = Manhattan distance, 2 for Euclidian distance) for finding the nearest neighbours.
Now we are ready to fit our model for prediction of Production given Porosity and Brittleness.
We will use our two functions defined above to visualize the k-nearest neighbour prediction over the feature space and the cross plot of actual and estimated production for the training data along with three model metrics from the sklearn.metric module.
neigh_fit = neigh.fit(sX_train,y_train) # train the model with the training data
plt.subplot(221) # training data vs. the model predictions
Z = visualize_model(neigh_fit,X_train[sel_spred[0]],-3.5,3.5,X_train[sel_spred[1]],-3.5,3.5,y_train[resp[0]],ymin,ymax,
'Training Data and k Nearest Neighbours')
plt.annotate('Hyperparameters',[1.5,3.2],color='white'); plt.annotate('weights: ' + weights,[1.5,2.9],color='white')
plt.annotate('n neighbours: ' + str(n_neighbours),[1.5,2.6],color='white'); plt.annotate('distance norm: ' + str(p),[1.5,2.3],color='white')
plt.subplot(222) # testing data vs. the model predictions
visualize_model(neigh_fit,X_test[sel_spred[0]],-3.5,3.5,X_test[sel_spred[1]],-3.5,3.5,y_test[resp[0]],ymin,ymax,
'Testing Data and k Nearest Neighbours')
plt.annotate('Hyperparameters',[1.5,3.2],color='white'); plt.annotate('weights: ' + weights,[1.5,2.9],color='white')
plt.annotate('n neighbours: ' + str(n_neighbours),[1.5,2.6],color='white'); plt.annotate('distance norm: ' + str(p),[1.5,2.3],color='white')
# plt.subplot(223) # model accuracy check
# check_model(neigh_fit,X_train[sel_spred[0]],X_train[sel_spred[1]],X_test[sel_spred[0]],X_test[sel_spred[1]],ymin,ymax,
# y_train[resp[0]],y_test[resp[0]],'K Nearest Neighbour Regression Model Accuracy')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=2.1, wspace=0.25, hspace=0.2); plt.show()
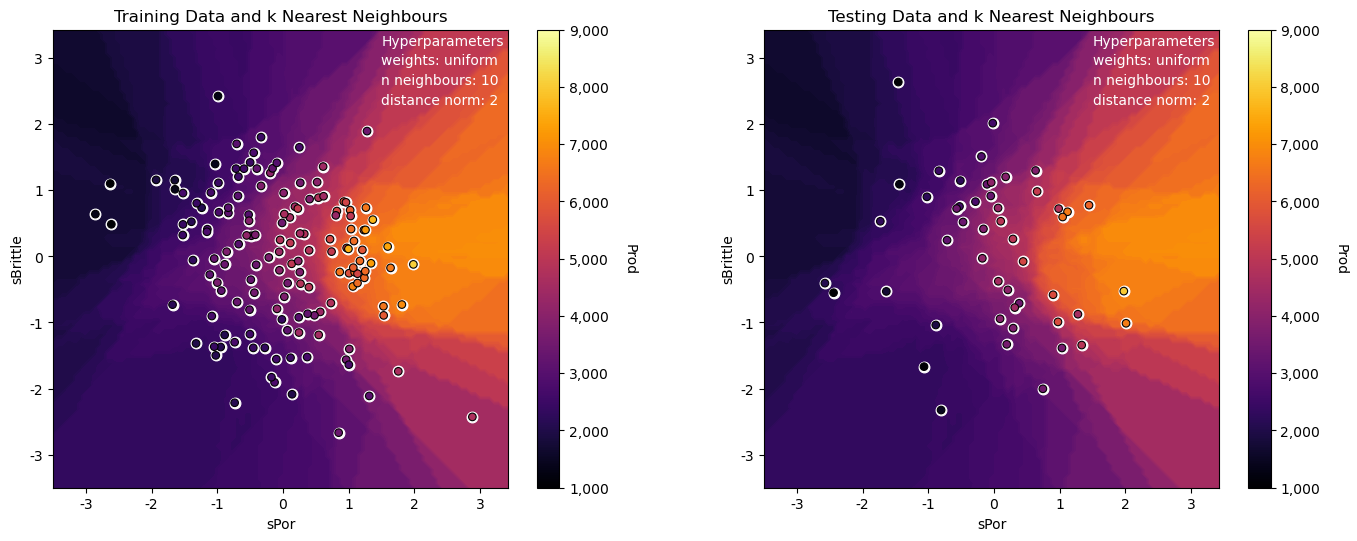
The model looks good:
the nonparametric approach is quite flexible to fit the nonlinear response patterns in the predictor feature space
we can see some search artifacts due to limited k nearest data and the use of uniform weighting
we have dense data for this low dimensional problem (only 2 predictor features)
the testing and training data are consistent and close to each other in the predictor feature space
Let’s try to overfit the model by using a very large k hyperparameter.
n_neighbours = 100; p = 2; weights = 'uniform' # model hyperparameters
neigh = KNeighborsRegressor(weights = weights,n_neighbors=n_neighbours,p = p) # instantiate the prediction model
neigh_fit = neigh.fit(sX_train,y_train) # train the model with the training data
plt.subplot(221) # training data vs. the model predictions
Z = visualize_model(neigh_fit,X_train[sel_spred[0]],-3.5,3.5,X_train[sel_spred[1]],-3.5,3.5,y_train[resp[0]],ymin,ymax,
'Training Data and k Nearest Neighbours')
plt.annotate('Hyperparameters',[1.5,3.2],color='white'); plt.annotate('weights: ' + weights,[1.5,2.9],color='white')
plt.annotate('n neighbours: ' + str(n_neighbours),[1.5,2.6],color='white'); plt.annotate('distance norm: ' + str(p),[1.5,2.3],color='white')
plt.subplot(222) # testing data vs. the model predictions
visualize_model(neigh_fit,X_test[sel_spred[0]],-3.5,3.5,X_test[sel_spred[1]],-3.5,3.5,y_test[resp[0]],ymin,ymax,
'Testing Data and k Nearest Neighbours')
plt.annotate('Hyperparameters',[1.5,3.2],color='white'); plt.annotate('weights: ' + weights,[1.5,2.9],color='white')
plt.annotate('n neighbours: ' + str(n_neighbours),[1.5,2.6],color='white'); plt.annotate('distance norm: ' + str(p),[1.5,2.3],color='white')
plt.subplot(223) # model accuracy check
check_model(neigh_fit,X_train[sel_spred[0]],X_train[sel_spred[1]],X_test[sel_spred[0]],X_test[sel_spred[1]],ymin,ymax,
y_train[resp[0]],y_test[resp[0]],'K Nearest Neighbour Regression Model Accuracy')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=2.1, wspace=0.25, hspace=0.2); plt.show()
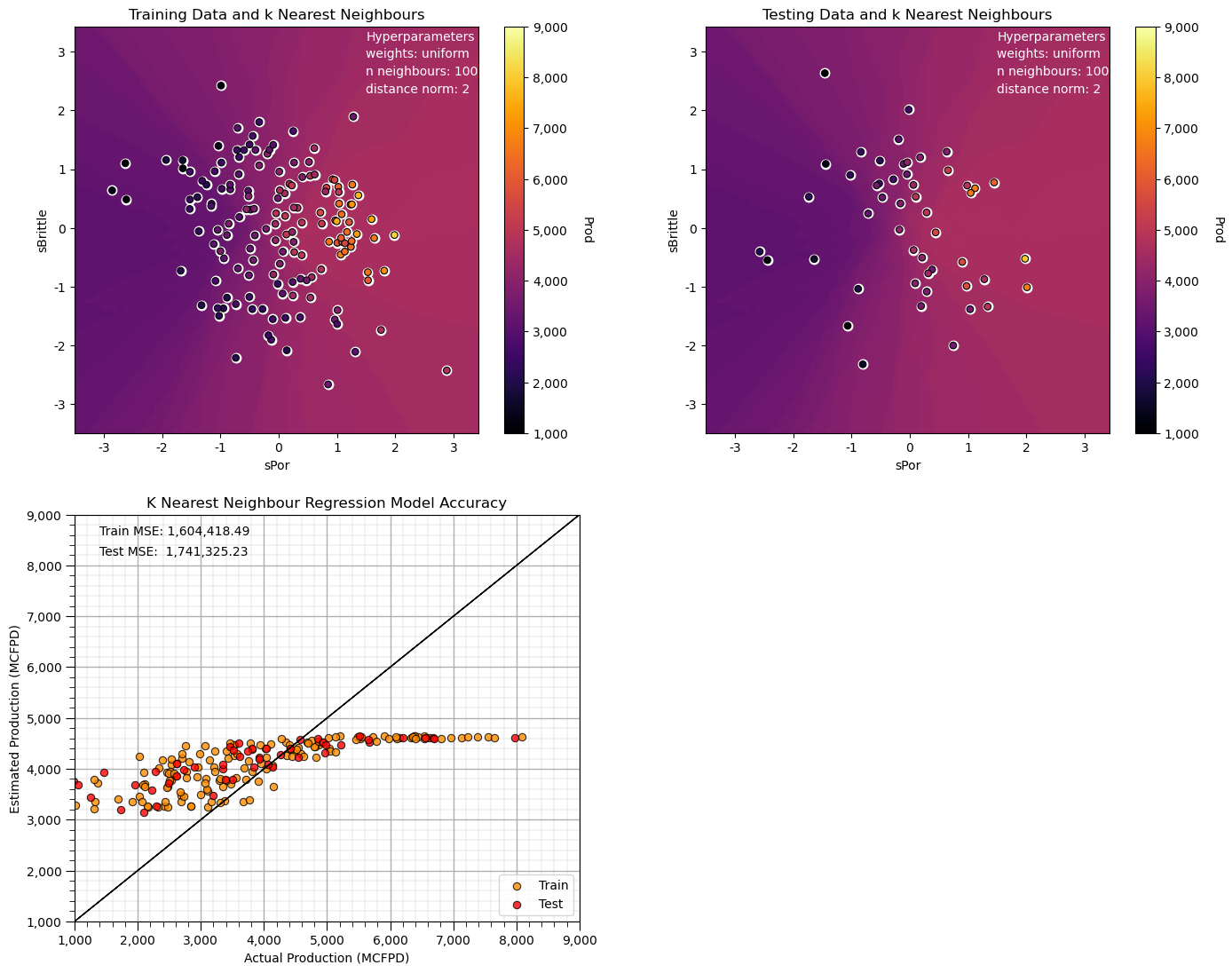
Note that this smoothed out the response, and the predictions are approaching the global mean.
we have an underfit model.
Next let’s use a smaller k hyperparameter for our k-nearest neighbours prediction model.
n_neighbours = 1; p = 2; weights = 'uniform' # model hyperparameters
neigh = KNeighborsRegressor(weights = weights,n_neighbors=n_neighbours,p = p) # instantiate the prediction model
neigh_fit = neigh.fit(sX_train,y_train) # train the model with the training data
plt.subplot(221) # training data vs. the model predictions
Z = visualize_model(neigh_fit,X_train[sel_spred[0]],-3.5,3.5,X_train[sel_spred[1]],-3.5,3.5,y_train[resp[0]],ymin,ymax,
'Training Data and k Nearest Neighbours')
plt.annotate('Hyperparameters',[1.5,3.2],color='white'); plt.annotate('weights: ' + weights,[1.5,2.9],color='white')
plt.annotate('n neighbours: ' + str(n_neighbours),[1.5,2.6],color='white'); plt.annotate('distance norm: ' + str(p),[1.5,2.3],color='white')
plt.subplot(222) # testing data vs. the model predictions
visualize_model(neigh_fit,X_test[sel_spred[0]],-3.5,3.5,X_test[sel_spred[1]],-3.5,3.5,y_test[resp[0]],ymin,ymax,
'Testing Data and k Nearest Neighbours')
plt.annotate('Hyperparameters',[1.5,3.2],color='white'); plt.annotate('weights: ' + weights,[1.5,2.9],color='white')
plt.annotate('n neighbours: ' + str(n_neighbours),[1.5,2.6],color='white'); plt.annotate('distance norm: ' + str(p),[1.5,2.3],color='white')
plt.subplot(223) # model accuracy check
check_model(neigh_fit,X_train[sel_spred[0]],X_train[sel_spred[1]],X_test[sel_spred[0]],X_test[sel_spred[1]],ymin,ymax,
y_train[resp[0]],y_test[resp[0]],'K Nearest Neighbour Regression Model Accuracy')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=2.1, wspace=0.25, hspace=0.2); plt.show()
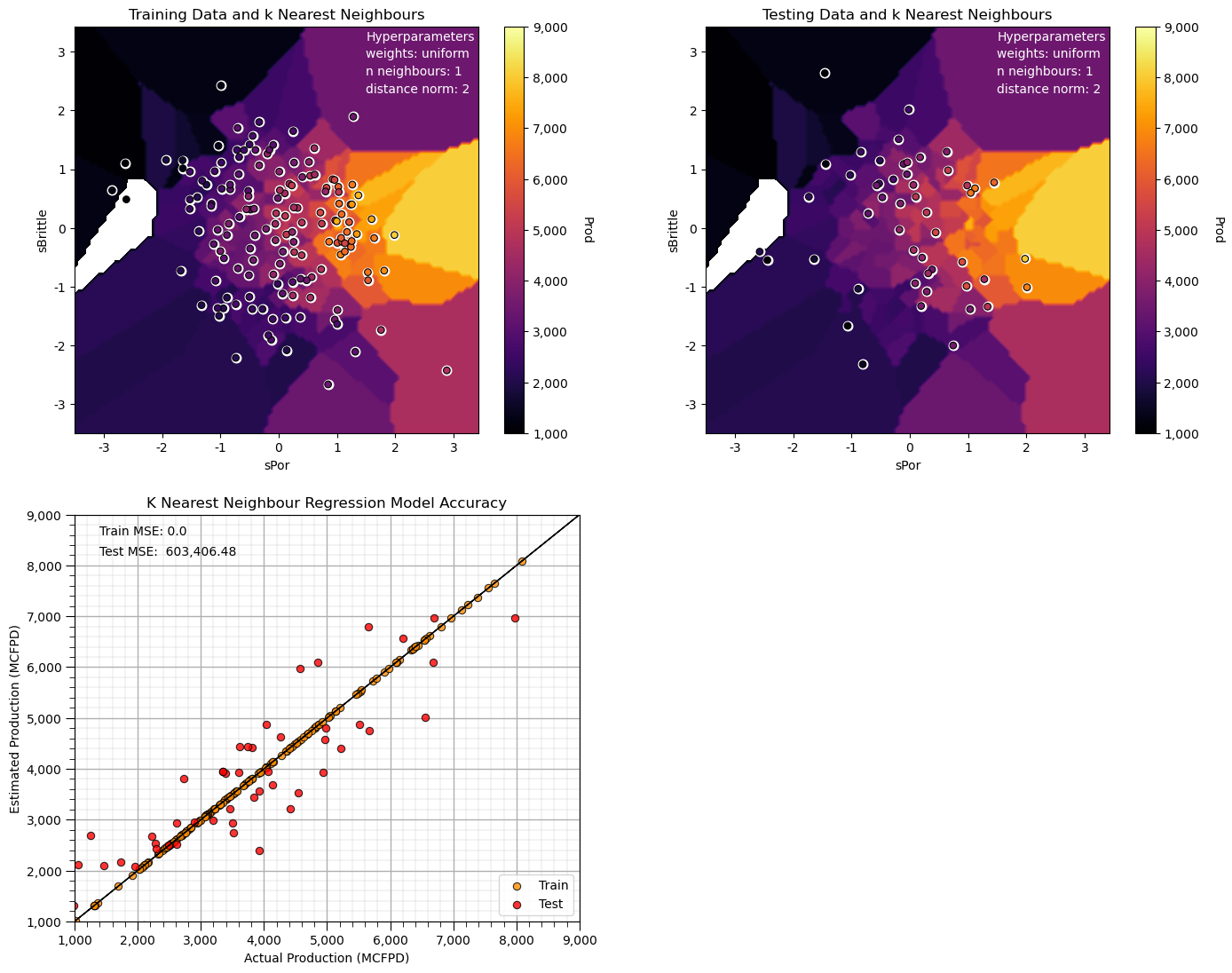
Now we have an extreme overfit model.
The training MSE is 0.0 and the testing error is quite high.
Note, some of our predictions in our overfit model are outside the plotting min and max response feature values.
Let’s try to use a L1, Manhattan distance to find the k nearest neighbours.
n_neighbours = 10; p = 1; weights = 'uniform' # model hyperparameters
neigh = KNeighborsRegressor(weights = weights,n_neighbors=n_neighbours,p = p) # instantiate the prediction model
neigh_fit = neigh.fit(sX_train,y_train) # train the model with the training data
plt.subplot(221) # training data vs. the model predictions
Z = visualize_model(neigh_fit,X_train[sel_spred[0]],-3.5,3.5,X_train[sel_spred[1]],-3.5,3.5,y_train[resp[0]],ymin,ymax,
'Training Data and k Nearest Neighbours')
plt.annotate('Hyperparameters',[1.5,3.2],color='white'); plt.annotate('weights: ' + weights,[1.5,2.9],color='white')
plt.annotate('n neighbours: ' + str(n_neighbours),[1.5,2.6],color='white'); plt.annotate('distance norm: ' + str(p),[1.5,2.3],color='white')
plt.subplot(222) # testing data vs. the model predictions
visualize_model(neigh_fit,X_test[sel_spred[0]],-3.5,3.5,X_test[sel_spred[1]],-3.5,3.5,y_test[resp[0]],ymin,ymax,
'Testing Data and k Nearest Neighbours')
plt.annotate('Hyperparameters',[1.5,3.2],color='white'); plt.annotate('weights: ' + weights,[1.5,2.9],color='white')
plt.annotate('n neighbours: ' + str(n_neighbours),[1.5,2.6],color='white'); plt.annotate('distance norm: ' + str(p),[1.5,2.3],color='white')
plt.subplot(223) # model accuracy check
check_model(neigh_fit,X_train[sel_spred[0]],X_train[sel_spred[1]],X_test[sel_spred[0]],X_test[sel_spred[1]],ymin,ymax,
y_train[resp[0]],y_test[resp[0]],'K Nearest Neighbour Regression Model Accuracy')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=2.1, wspace=0.25, hspace=0.2); plt.show()
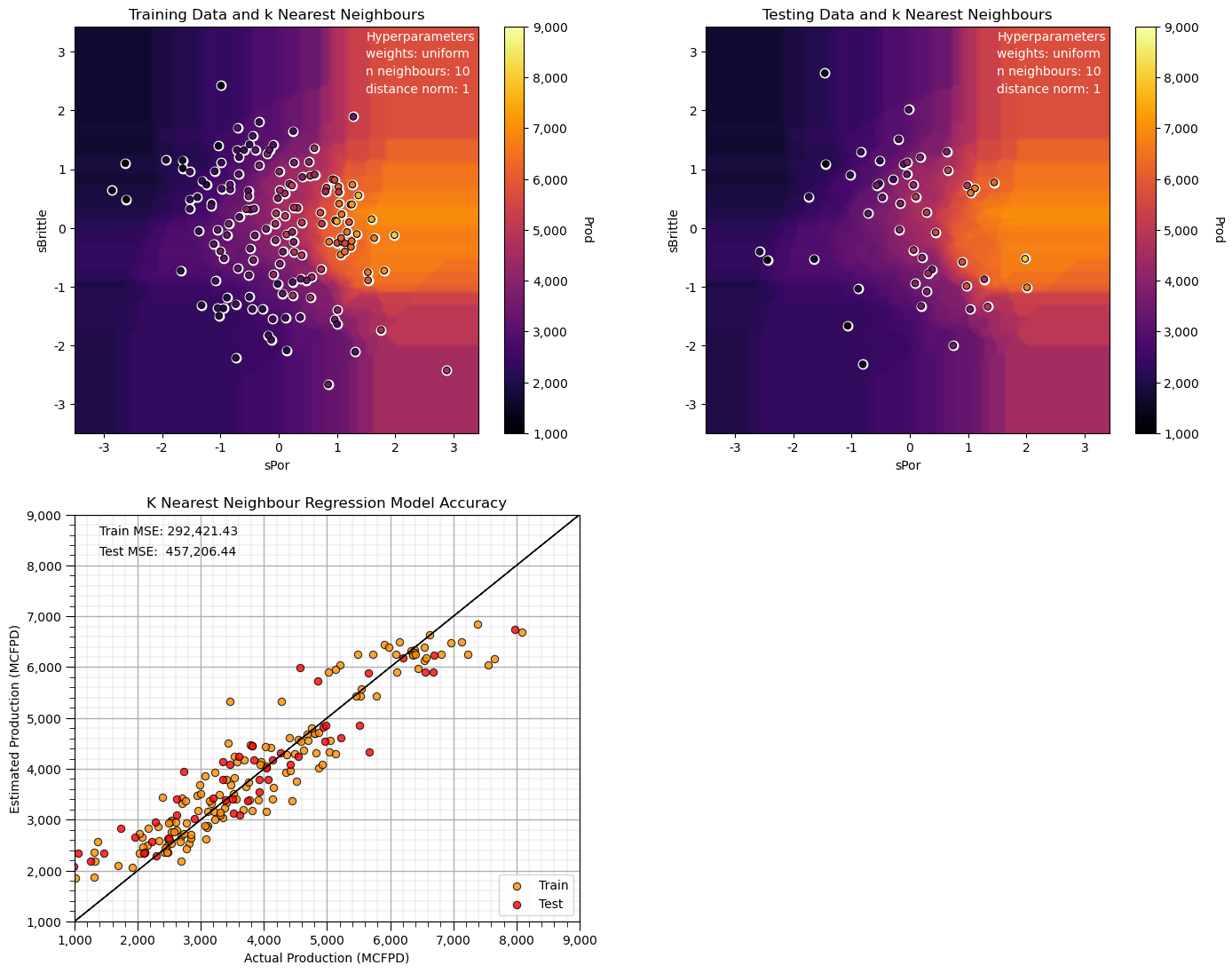
Compare this prediction model to our first model, all we changes is the distance search for the k nearest samples to Manhattan from Euclidean distance.
the search artifacts are now aligned on the features (the rays are oriented in the x and y directions)
Hyperparameter Tuning for k-Nearest Neighbours#
Let’s check this out as we tune the hyper parameters.
So what does the \(k\) do?
small \(k\) hyperparameter results in a local specific prediction model over the predictor feature space
large \(k\) hyperparameter results in a more smooth, globally fit prediction model over the predictor features space
This is analogous to the low to high complexity we have observed with other models (like decision trees).
small \(k\) is complex
large \(k\) is simple
We need to tune the complexity to optimize model performance.
Tuning the Hyperparameters#
Let’s loop over multiple \(k\) nearest neighbours for average and inverse distance estimates to access the best hyperparameters with respect to accuracy in testing.
k = 1 # set initial, lowest k hyperparameter
dist_error = []; unif_error = []; k_mat = [] # make lists to store the results
while k <= 150: # loop over the k hyperparameter
neigh_dist = KNeighborsRegressor(weights = 'distance', n_neighbors=k, p = 2) # instantiate the model
neigh_dist_fit = neigh_dist.fit(sX_train,y_train) # train the model with the training data
y_pred = neigh_dist_fit.predict(sX_test) # predict over the testing cases
MSE = metrics.mean_squared_error(y_test,y_pred) # calculate the MSE testing
dist_error.append(MSE) # add to the list of MSE
neigh_unif = KNeighborsRegressor(weights = 'uniform', n_neighbors=k, p = 2)
neigh_unif_fit = neigh_unif.fit(sX_train,y_train) # train the model with the training data
y_pred = neigh_unif_fit.predict(sX_test) # predict over the testing cases
MSE = metrics.mean_squared_error(y_test,y_pred) # calculate the MSE testing
unif_error.append(MSE) # add to the list of MSE
k_mat.append(k) # append k to an array for plotting
k = k + 1
Now let’s plot the result.
plt.subplot(111)
plt.scatter(k_mat,dist_error,s=None, c='red',label = 'inverse distance weighted', marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=0.8, linewidths=0.3, edgecolors="black")
plt.scatter(k_mat,unif_error,s=None, c='blue',label = 'arithmetic average', marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=0.8, linewidths=0.3, edgecolors="black")
plt.title('Testing Error vs. Number of Nearest Neighbours'); plt.xlabel('Number of Nearest Neighbours'); plt.ylabel('Mean Square Error')
plt.legend(); add_grid()
plt.xlim(0,150); plt.ylim([0,4000000])
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.8, top=0.8,wspace=0.15,hspace=0.2); plt.show()
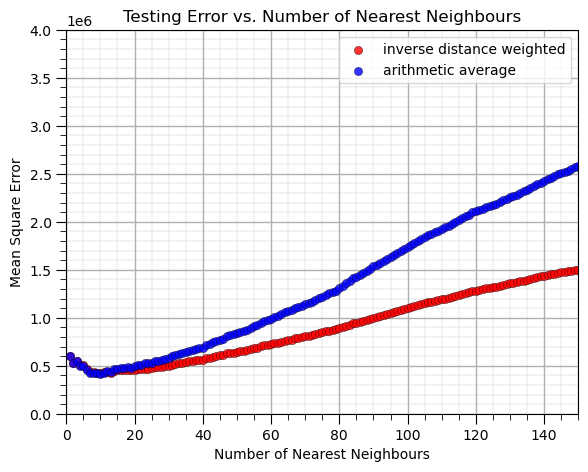
What can we observe from this result?
at \(k = 10\) nearest neighbours we minimize the mean square error in testing.
we have better performance with the inverse distance weighted than the arithmetic average (uniform weighting of k nearest training data in predictor feature space)
There is an optimum degree of specificity / complexity to our model.
1 nearest neighbour is a very locally specific model (overfit)
many nearest neighbours includes too much information and is too general (underfit)
We are observing the accuracy vs. complexity trade-off for the \(k\) nearest neighbour model.
k-fold Cross Validation#
It is useful to evaluate the performance of our model by observing the accuracy vs. complexity trade-off.
Yet, what we really want to do is rigorously test our model performance. We should perform a more rigorous cross validation that does a better job evaluating over different sets of training and testing data. scikit learn has a built in cross validation method called cross_val_score that we can use to:
Apply k-fold approach with iterative separation of training and testing data
Automate the model construction, looping over folds and averaging the metric of interest
Let’s try it out on our k nearest neighbour prediction with variable number of \(k\) nearest neighbours. Note the cross validation is set to use 4 processors, but still will likely take a couple of minutes to run.
score = []
k_mat = []
for k in range(1,150):
pipe = Pipeline([
('scaler', StandardScaler()),
('model', KNeighborsRegressor(weights = 'distance', n_neighbors=k, p = 1))
])
cv = KFold(n_splits=5, shuffle=True, random_state=seed)
scores = cross_val_score(pipe, X, y, cv=cv, scoring='neg_mean_squared_error')
score.append(abs(scores.mean()))
k_mat.append(k)
The output is an array of average scores (MSE) over the k-folds for each level of complexity (number of \(k\) nearest neighbours), along with an array with the \(k\)s.
plt.figure(figsize=(8,6))
plt.scatter(k_mat,score,s=None, c="red", marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=0.8, linewidths=0.5, edgecolors="black")
plt.title('k-fold Cross Validation Error (MSE) vs. k Nearest Neighbours'); plt.xlabel('Number of Nearest Neighbours'); plt.ylabel('Mean Square Error')
plt.xlim(1,150); plt.ylim([0,1400000]); add_grid()
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.8, top=0.8,wspace=0.15,hspace=0.2); plt.show()
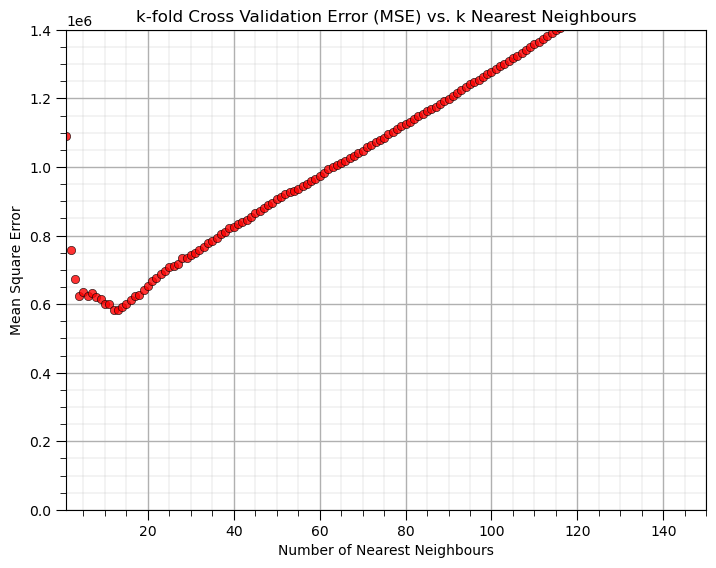
With the hyperparameter of 10 nearest neighbours we get the greatest accuracy in k-fold cross validation model testing.
Predictor Feature Standardization#
We have standardized the predictor feature to remove the influence of their ranges.
What would happen if we worked with the original predictor features?
Let’s try it out.
we first apply train and test split with the original features, without standardization
neigh = KNeighborsRegressor(weights = 'distance', n_neighbors=15, p = 1)
neigh_fit = neigh.fit(X_train[[sel_pred[0],sel_pred[1]]],y_train) # train the model with the training data
plt.subplot(121) # training data vs. the model predictions
Z = visualize_model(neigh_fit,X_train[sel_pred[0]],Xmin[0],Xmax[0],X_train[sel_pred[1]],Xmin[1],Xmax[1],y_train[resp[0]],ymin,ymax,
'Training Data and k Nearest Neighbours')
plt.annotate('Hyperparameters',[1.5,3.2],color='white'); plt.annotate('weights: ' + weights,[1.5,2.9],color='white')
plt.annotate('n neighbours: ' + str(n_neighbours),[1.5,2.6],color='white'); plt.annotate('distance norm: ' + str(p),[1.5,2.3],color='white')
plt.subplot(122) # testing data vs. the model predictions
visualize_model(neigh_fit,X_test[sel_pred[0]],Xmin[0],Xmax[0],X_test[sel_pred[1]],Xmin[1],Xmax[1],y_test[resp[0]],ymin,ymax,
'Testing Data and k Nearest Neighbours')
plt.annotate('Hyperparameters',[1.5,3.2],color='white'); plt.annotate('weights: ' + weights,[1.5,2.9],color='white')
plt.annotate('n neighbours: ' + str(n_neighbours),[1.5,2.6],color='white'); plt.annotate('distance norm: ' + str(p),[1.5,2.3],color='white')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.2, wspace=0.2, hspace=0.2); plt.show()
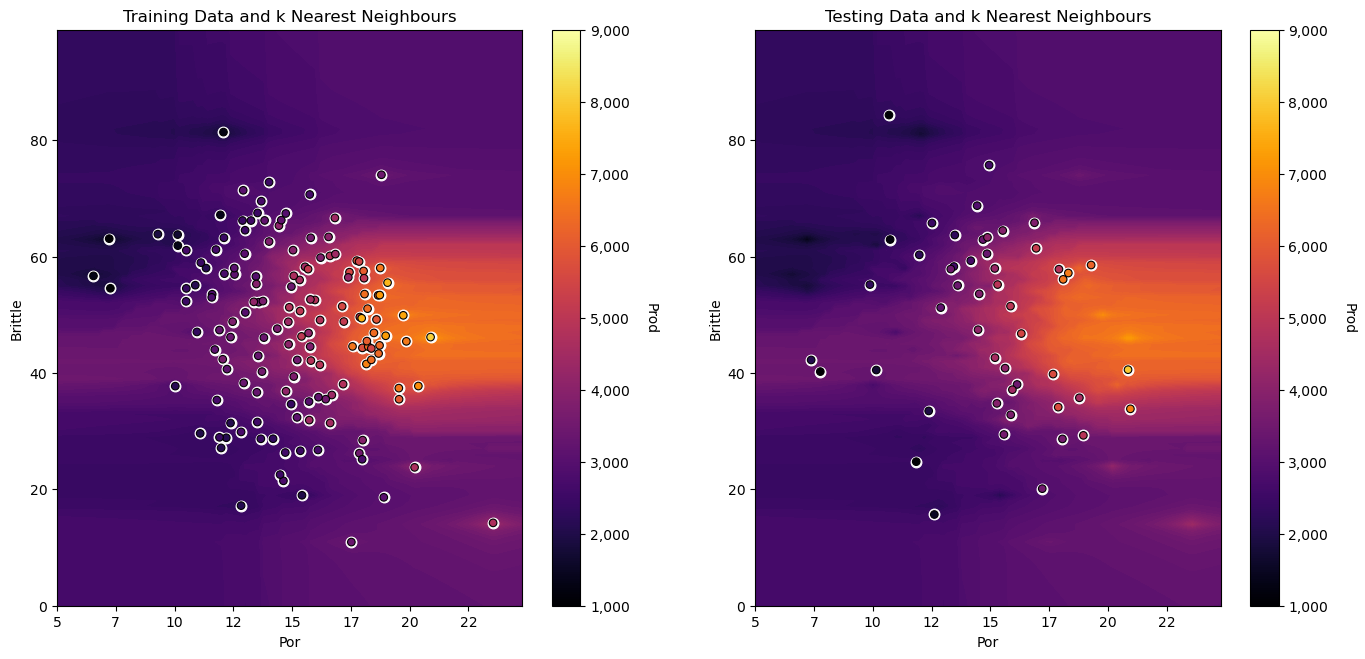
Do you see the horizontal banding? The larger range of magnitudes of brittleness vs. porosity results in this banding.
distances in the feature space are more sensitive to the relative changes in brittleness than porosity
Let’s convert porosity to a fraction and observe the change in our predictor due to the arbitrary decision to work with porosity as a fraction vs. a percentage.
by applying a \(\frac{1}{100}\) factor to all the porosity values.
X_train_mod = X_train.copy(deep = True); X_test_mod = X_test.copy(deep = True)
X_train_mod['Por'] = X_train_mod['Por']/100.0
X_test_mod['Por'] = X_test_mod['Por']/100.0
neigh = KNeighborsRegressor(weights = 'distance', n_neighbors=15, p = 1)
neigh_fit = neigh.fit(X_train[[sel_pred[0],sel_pred[1]]],y_train) # train the model with the training data
plt.subplot(121) # training data vs. the model predictions
Z = visualize_model(neigh_fit,X_train_mod[sel_pred[0]],Xmin[0]/100,Xmax[0]/100,X_train[sel_pred[1]],Xmin[1],Xmax[1],y_train[resp[0]],ymin,ymax,
'Training Data and k Nearest Neighbours',False)
plt.annotate('Hyperparameters',[1.5,3.2],color='white'); plt.annotate('weights: ' + weights,[1.5,2.9],color='white')
plt.annotate('n neighbours: ' + str(n_neighbours),[1.5,2.6],color='white'); plt.annotate('distance norm: ' + str(p),[1.5,2.3],color='white')
plt.subplot(122) # testing data vs. the model predictions
visualize_model(neigh_fit,X_test_mod[sel_pred[0]],Xmin[0]/100,Xmax[0]/100,X_test[sel_pred[1]],Xmin[1],Xmax[1],y_test[resp[0]],ymin,ymax,
'Testing Data and k Nearest Neighbours',False)
plt.annotate('Hyperparameters',[1.5,3.2],color='white'); plt.annotate('weights: ' + weights,[1.5,2.9],color='white')
plt.annotate('n neighbours: ' + str(n_neighbours),[1.5,2.6],color='white'); plt.annotate('distance norm: ' + str(p),[1.5,2.3],color='white')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.2, wspace=0.2, hspace=0.2); plt.show()
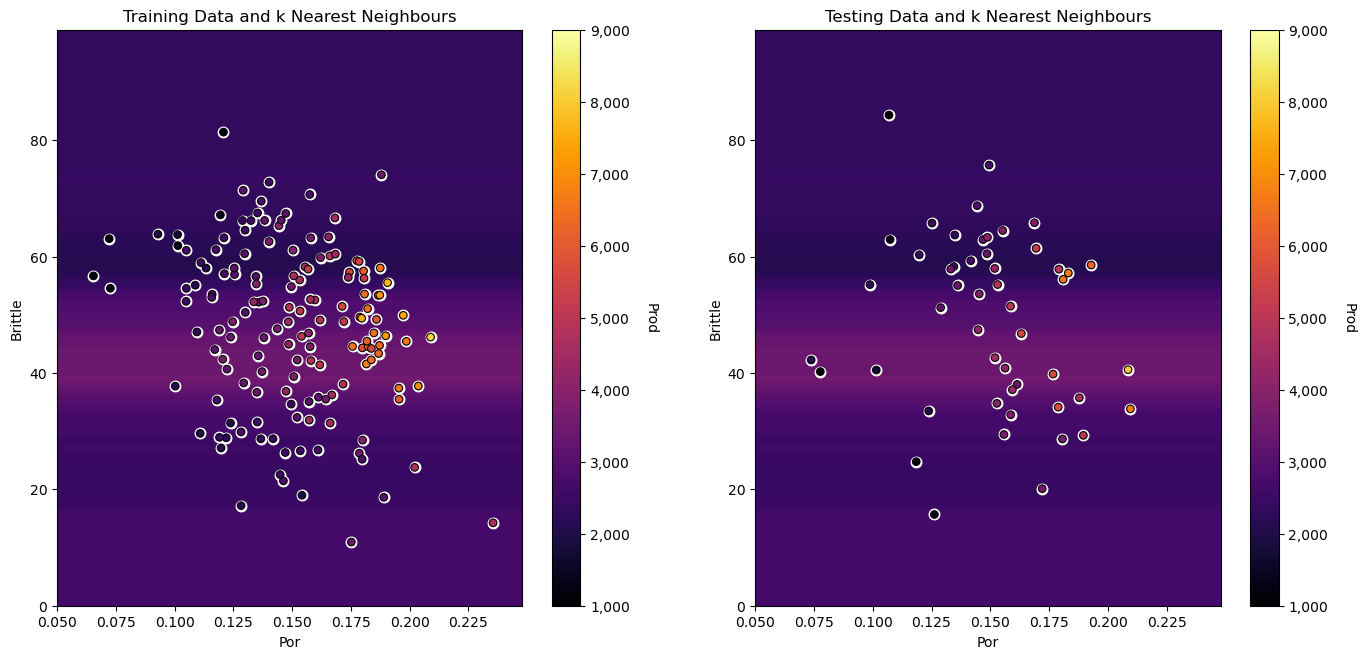
this banding effect gets even more severe as we convert from percentage to fractional porosity, because distances in porosity appear so much closer than in brittleness, just because of the difference in feature ranges.
Our distance metric for assigning nearest neighbours is quite sensitive to the feature units. We should always standardize all predictor features (put them on equal footing) before we use them to build our \(k\)-nearest neighbour regression model!
k Nearest Neighbour Regression in scikit-learn with Pipelines#
The need to standardize features, train, tune and retrain the tuned model with all the data may seem to be a lot of work!
one solution is to use the Pipeline object from scikit-learn.
Here’s some highlights on Pipelines.
Machine Learning Modeling Pipelines Basics#
Machine learning workflows can be complicated, with various steps:
data preparation, feature engineering transformations
model parameter fitting
model hyperparameter tuning
modeling method selection
searching over a large combinatorial of hyperparameters
training and testing model runs
Pipelines are a scikit-learn class that allows for the encapsulation of a sequence of data preparation and modeling steps
then we can treat the pipeline as an object in our much condensed workflow
The pipeline class allows us to:
improve code readability and to keep everything straight
avoid common workflow problems like data leakage, testing data informing model parameter training
abstract common machine learning modeling and focus on building the best model possible
The fundamental philosophy is to treat machine learning as a combinatorial search to automate the determination of the best model (AutoML)
k-Nearest Neighbours with Pipelines#
Here’s compact, safe code for the entire model training and tuning process with scikit-learn pipelines
the GridSearchCV object actually becomes the prediction model, with tuned hyperparameters retrained on all of the data!
import os # to set current working directory
folds = 4 # number of k folds
k_min = 1; k_max = 150 # range of k hyperparameter to consider
X_pipe = df.loc[:,sel_pred] # all the samples for the original features
y_pipe = df.loc[:,resp[0]] # warning this becomes a series, 1D ndarray with label
pipe = Pipeline([ # the machine learning workflow as a pipeline object
('scaler', StandardScaler()),
('knear', KNeighborsRegressor())
])
params = { # the machine learning workflow method's parameters
'scaler': [StandardScaler()],
'knear__n_neighbors': np.arange(k_min,k_max,1,dtype = int),
'knear__metric': ['euclidean'],
'knear__p': [2],
'knear__weights': ['distance']
}
grid_cv_tuned = GridSearchCV(pipe, params, scoring = 'neg_mean_squared_error', # grid search cross validation
cv=KFold(n_splits=folds,shuffle=False),
refit = True)
grid_cv_tuned.fit(X_pipe,y_pipe) # fit model with tuned hyperparameters
plt.subplot(121)
visualize_tuned_model(grid_cv_tuned.best_params_['knear__n_neighbors'], # visualize the error vs. k
grid_cv_tuned.cv_results_['param_knear__n_neighbors'],
abs(grid_cv_tuned.cv_results_['mean_test_score']))
plt.subplot(122) # visualize the tuned model
visualize_model(grid_cv_tuned,X[sel_pred[0]],Xmin[0],Xmax[0],X[sel_pred[1]],Xmin[1],Xmax[1],df[resp[0]],ymin,ymax,
'All Data and Tuned and Retrained k-Nearest Neighbours')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.2, wspace=0.2, hspace=0.2); plt.show()
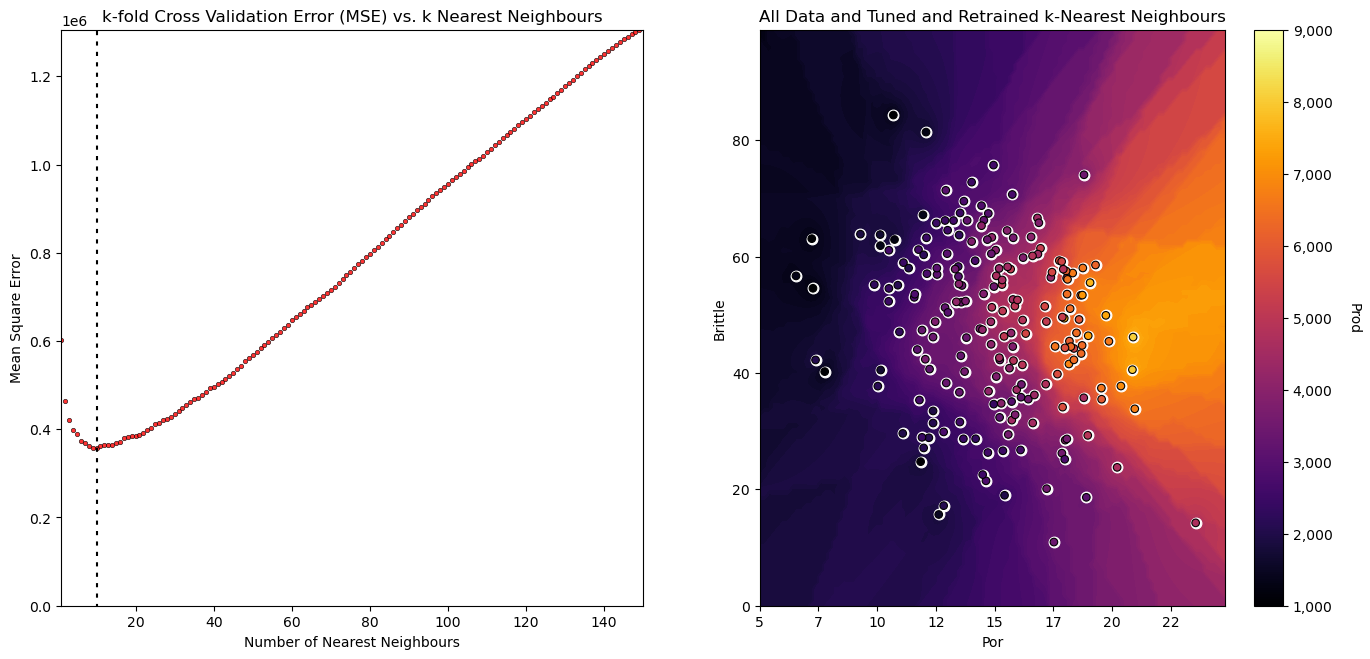
Check the Tuned Hyperparameters#
In the GridSearchCV model object, there is a built in dictionary called best_params_ that includes all the tuned hyperparameters.
note, over the range of k’s the selected k, n_neighbors
also, the other hyperparameters were specified, but we could have provided a range and scenarios for each to explore with the grid search method
When tuning more than 1 hyperparameter, the runtime will increase with the combinatorial of hyperparameters and the resulting model loss function, e.g., cv_results_[‘mean_test_score’], is sorted over all the hyperparameter cases
grid_cv_tuned.best_params_
{'knear__metric': 'euclidean',
'knear__n_neighbors': 10,
'knear__p': 2,
'knear__weights': 'distance',
'scaler': StandardScaler()}
It is also useful to look at the entire model object for more information. Including:
the pipeline and all cases considered for the hyperparameter tuning.
grid_cv_tuned
GridSearchCV(cv=KFold(n_splits=4, random_state=None, shuffle=False),
estimator=Pipeline(steps=[('scaler', StandardScaler()),
('knear', KNeighborsRegressor())]),
param_grid={'knear__metric': ['euclidean'],
'knear__n_neighbors': array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13,
14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26,
27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39,
40, 41, 42, 43, 44, 45,...
79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91,
92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104,
105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117,
118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130,
131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143,
144, 145, 146, 147, 148, 149]),
'knear__p': [2], 'knear__weights': ['distance'],
'scaler': [StandardScaler()]},
scoring='neg_mean_squared_error')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(cv=KFold(n_splits=4, random_state=None, shuffle=False),
estimator=Pipeline(steps=[('scaler', StandardScaler()),
('knear', KNeighborsRegressor())]),
param_grid={'knear__metric': ['euclidean'],
'knear__n_neighbors': array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13,
14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26,
27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39,
40, 41, 42, 43, 44, 45,...
79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91,
92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104,
105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117,
118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130,
131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143,
144, 145, 146, 147, 148, 149]),
'knear__p': [2], 'knear__weights': ['distance'],
'scaler': [StandardScaler()]},
scoring='neg_mean_squared_error')Pipeline(steps=[('scaler', StandardScaler()), ('knear', KNeighborsRegressor())])StandardScaler()
KNeighborsRegressor()
About the Author#

Michael Pyrcz is a professor in the Cockrell School of Engineering, and the Jackson School of Geosciences, at The University of Texas at Austin, where he researches and teaches subsurface, spatial data analytics, geostatistics, and machine learning. Michael is also,
the principal investigator of the Energy Analytics freshmen research initiative and a core faculty in the Machine Learn Laboratory in the College of Natural Sciences, The University of Texas at Austin
an associate editor for Computers and Geosciences, and a board member for Mathematical Geosciences, the International Association for Mathematical Geosciences.
Michael has written over 70 peer-reviewed publications, a Python package for spatial data analytics, co-authored a textbook on spatial data analytics, Geostatistical Reservoir Modeling and author of two recently released e-books, Applied Geostatistics in Python: a Hands-on Guide with GeostatsPy and Applied Machine Learning in Python: a Hands-on Guide with Code.
All of Michael’s university lectures are available on his YouTube Channel with links to 100s of Python interactive dashboards and well-documented workflows in over 40 repositories on his GitHub account, to support any interested students and working professionals with evergreen content. To find out more about Michael’s work and shared educational resources visit his Website.
Want to Work Together?#
I hope this content is helpful to those that want to learn more about subsurface modeling, data analytics and machine learning. Students and working professionals are welcome to participate.
Want to invite me to visit your company for training, mentoring, project review, workflow design and / or consulting? I’d be happy to drop by and work with you!
Interested in partnering, supporting my graduate student research or my Subsurface Data Analytics and Machine Learning consortium (co-PI is Professor John Foster)? My research combines data analytics, stochastic modeling and machine learning theory with practice to develop novel methods and workflows to add value. We are solving challenging subsurface problems!
I can be reached at mpyrcz@austin.utexas.edu.
I’m always happy to discuss,
Michael
Michael Pyrcz, Ph.D., P.Eng. Professor, Cockrell School of Engineering and The Jackson School of Geosciences, The University of Texas at Austin
Comments#
This was a basic treatment of k-nearest neighbours. Much more could be done and discussed, I have many more resources. Check out my shared resource inventory and the YouTube lecture links at the start of this chapter with resource links in the videos’ descriptions.
I hope this is helpful,
Michael