

Linear Regression#
Michael J. Pyrcz, Professor, The University of Texas at Austin
Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Chapter of e-book “Applied Machine Learning in Python: a Hands-on Guide with Code”.
Cite this e-Book as:
Pyrcz, M.J., 2024, Applied Machine Learning in Python: A Hands-on Guide with Code [e-book]. Zenodo. doi:10.5281/zenodo.15169138 ![]()
The workflows in this book and more are available here:
Cite the MachineLearningDemos GitHub Repository as:
Pyrcz, M.J., 2024, MachineLearningDemos: Python Machine Learning Demonstration Workflows Repository (0.0.3) [Software]. Zenodo. DOI: 10.5281/zenodo.13835312. GitHub repository: GeostatsGuy/MachineLearningDemos ![]()
By Michael J. Pyrcz
© Copyright 2024.
This chapter is a tutorial for / demonstration of Linear Regression.
YouTube Lecture: check out my lectures on:
These lectures are all part of my Machine Learning Course on YouTube with linked well-documented Python workflows and interactive dashboards. My goal is to share accessible, actionable, and repeatable educational content. If you want to know about my motivation, check out Michael’s Story.
Motivations for Linear Regression#
Here’s a simple workflow, demonstration of linear regression for machine learning-based predictions. Why start with linear regression?
Linear regression is the simplest parametric predictive machine learning model
We learn about training machine learning models with an analytical solution calculated from the derivative of training MSE
Get’s us started with the concepts of loss functions and norms
We have access to analytics expressions for confidence intervals for model uncertainty, and hypothesis tests for parameter significance
Here’s some basic details about linear regression.
Linear Regression#
Linear regression for prediction, let’s start by looking at a linear model fit to a set of data.
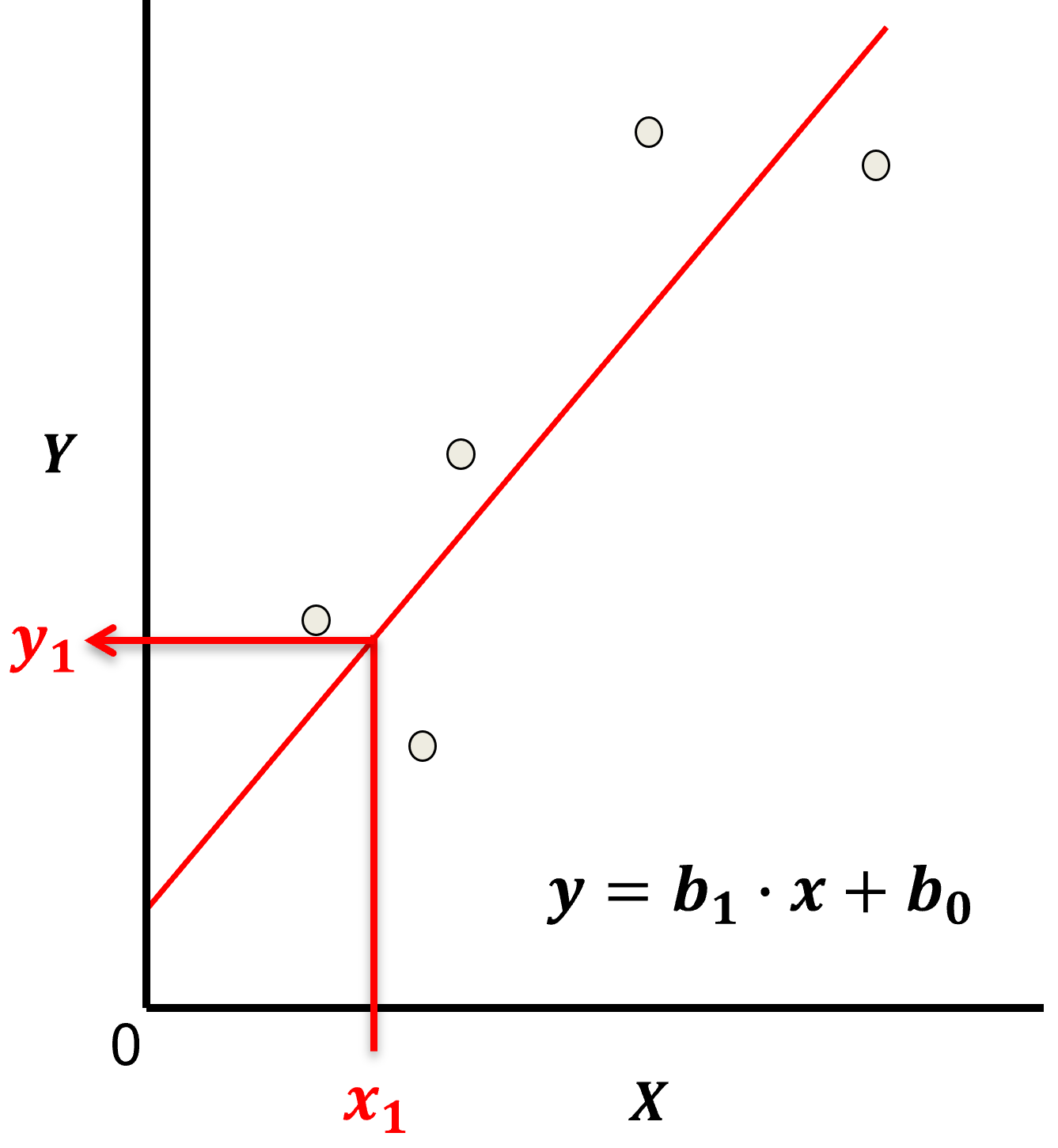
Let’s start by defining some terms,
predictor feature - an input feature for the prediction model, given we are only discussing linear regression and not multilinear regression we have only one predictor feature, \(x\). On out plots (including above) the predictor feature is on the x-axis.
response feature - the output feature for the prediction model, in this case, \(y\). On our plots (including above) the response feature is on the y-axis.
Now, here are some key aspects of linear regression:
Parametric Model
This is a parametric predictive machine learning model, we accept an a prior assumption of linearity and then gain a very low parametric representation that is easy to train without a onerous amount of data.
the fit model is a simple weighted linear additive model based on all the available features, \(x_1,\ldots,x_m\).
the parametric model takes the form of:
Here’s the visualization of the linear model parameters,
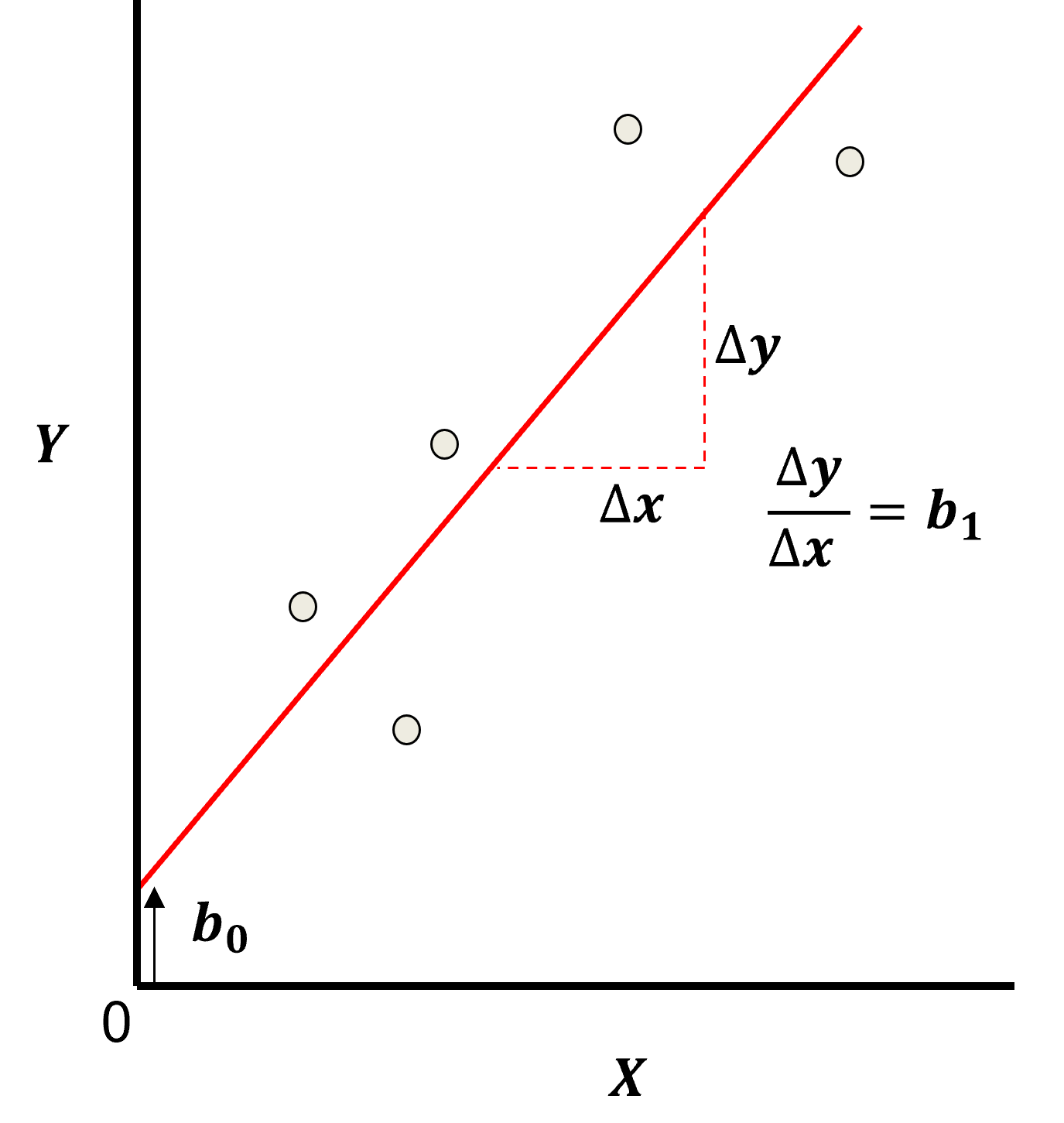
Least Squares
The analytical solution for the model parameters, \(b_1,\ldots,b_m,b_0\), is available for the L2 norm loss function, the errors are summed and squared known a least squares.
we minimize the error, residual sum of squares (RSS) over the training data:
where \(y_i\) is the actual response feature values and \(\sum_{\alpha = 1}^m b_{\alpha} x_{\alpha} + b_0\) are the model predictions, over the \(\alpha = 1,\ldots,n\) training data.
Here’s a visualization of the L2 norm loss function, MSE,
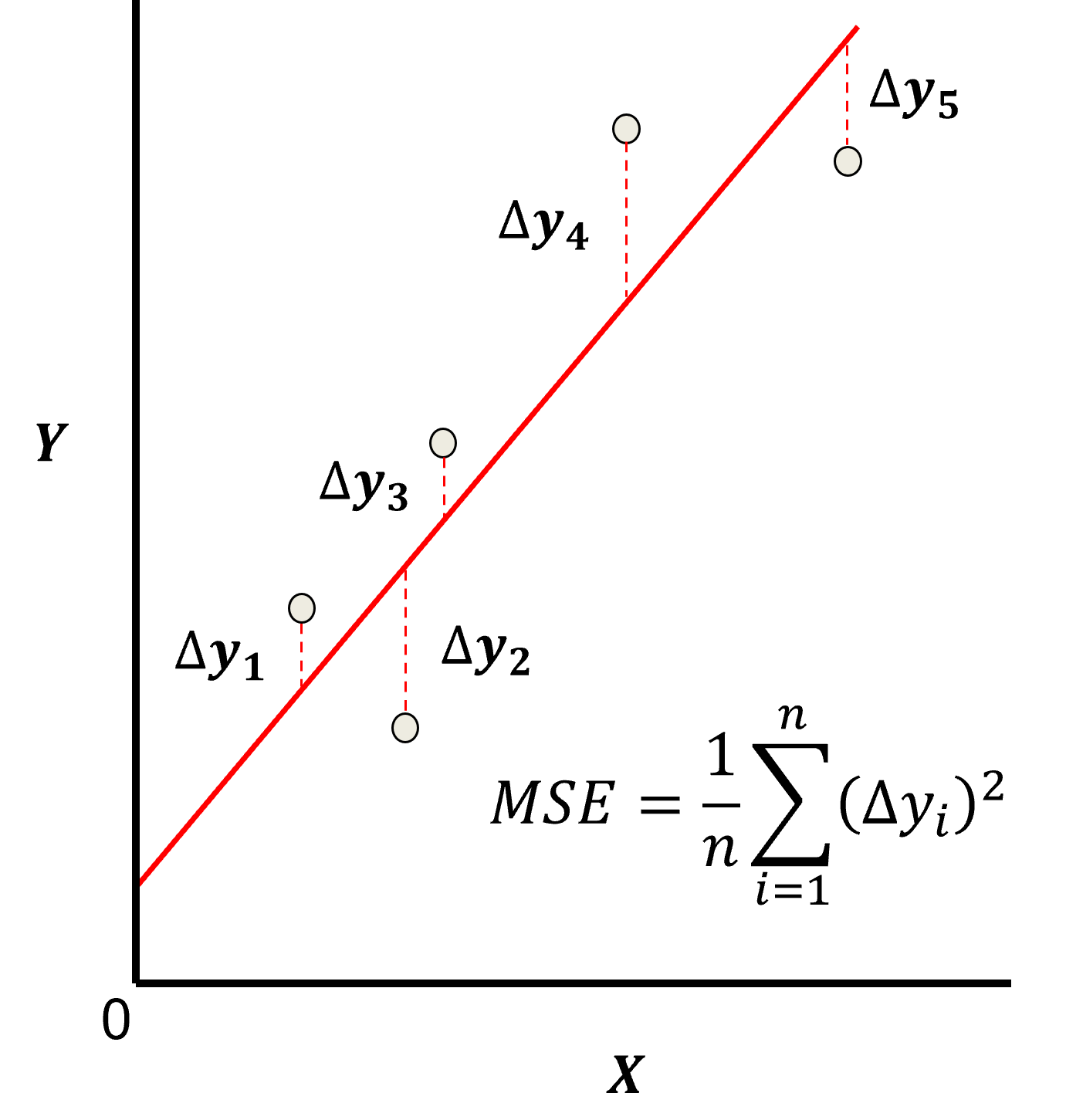
this may be simplified as the sum of square error over the training data,
\begin{equation} \sum_{i=1}^n (\Delta y_i)^2 \end{equation}
where \(\Delta y_i\) is actual response feature observation \(y_i\) minus the model prediction \(\sum_{\alpha = 1}^m b_{\alpha} x_{\alpha} + b_0\), over the \(i = 1,\ldots,n\) training data.
Assumptions
There are important assumption with our linear regression model,
Error-free - predictor variables are error free, not random variables
Linearity - response is linear combination of feature(s)
Constant Variance - error in response is constant over predictor(s) value
Independence of Error - error in response are uncorrelated with each other
No multicollinearity - none of the features are redundant with other features
Analytical Solution#
Since the loss is \(L^2\) we have access to a non-iterative, analytics solution, i.e., optimization of the linear regression model parameters.
we are looking for the model parameter(s) that minimize the loss function
when we have an analytical solution, we can use the 1st and 2nd derivatives of the loss function,
A local or global loss minimum occurs where,
first derivative of the loss function is 0.0 - zero slope indicating a local minimum or maximum
second derivative of the loss function is greater than 0.0 - positive curvature indicated a local minimum instead of maximum
Now let’s use this approach to derived the solution for linear regression.
Linear Regression Training#
For the least squares (L2) norm the linear regression model parameters can be trained with training data with an analytical solution. Let’s derive it for linear regression analytical solution for the case of 1 predictor feature.
To calculated the slope coefficient, \(b_1\), we start with the loss function,
Now we take the partial derivative with respect to the model parameter, \(b_1\),
to optimize, minimize the loss, we set the partical derivative with respect to the model parameter, \(b_1\) equal to 0.0.
we can simplify (divide both sides by -2) and distribute multiply to get,
now we can substitute in \(b_0 = \overline{y} - b_1 \cdot \overline{x}\),
once again we multiply to get,
we separate the sums,
and we can pull out the \(b_1\) constant,
and reorder a little to get,
move to the other side,
and divide both sizes by \(\sum_{i=1}^n x_i^2 - \overline{x} \cdot x_i\),
we now have an analytical solution for the \(b_1\) slope term for linear regression. It can be shown that this is equivalent to another form,
I prefer this form because it is easily interpreted as the covariance of \(X\) and \(Y\), \(C_{x,y}\) divided by the variance of \(X\), \(sigma_{x}^2\).
Now for the calculation of the intercept term, \(b_0\), we return to the loss function,
and this time we take the partial derivative with respect to \(b_0\),
to optimize, minimize the loss, we set the partical derivative with respect to the model parameter, \(b_0\) equal to 0.0.
we divide both sides by -2,
and break up the sum,
simplify the simple term as it is a constant, \(\sum_{i=1}^n b_0 = n \cdot b_0\),
now move the \(b_0\) term to the left-hand side,
pull out the constant \(b_1\) from the sum,
divide both sides by \(n\),
this is very interesting, we now see 2 arithmetic means!
so our solution is simply,
Checking the Model#
For linear regression models we have access to a powerful metric to check our model, the coefficient of determination, also known as “r-squared”, \(r^2\).
the proportion of variance explained by the model
calculated as the explained variance, \(SS_{reg}\) divided by the total variance, \(SS_{tot}\),
where \(\hat{y}_i\) is the model prediction at the \(i\) training data, and $\overline{y} is the average of the sample data.
the \(r^2\) can be calculated from the correlation coefficient, so you can know the goodness of a linear regression model, before you train it!
note, \(r^2\) can only be used for linear models where,
where \(\sigma^2_{tot}\) is total variance of the response feature, \(\sigma^2_{reg}\) is the variance of the model predictions, and \(\sigma^2_{res}\) is the variance of the error, i.e., the residuals, \(\Delta y_i = y_i - \hat{y}_i\).
How to interpret \(r^2\)? It would be dangerous to hard thresholds, but I can give some soft guidance,
\(r^2 \ge 0.98\) - the model is cheating or the problem is very easy, linear, noise-free and well sampled
\(0.0 \le r^2 \le 0.6\) - the model is not working well, check the data and model choice
\(r^2 \lt 0.0\) - the model is going the wrong way! You are better off with estimating by the global mean, \(\overline{y}\)
Model Uncertainty#
To communicate model uncertainty we rely on confidence intervals for the model parameters, \(b_1\) and \(b_0\). Let’s define confidence interval here for convenience,
Confidence Interval - the uncertainty in a summary statistic / model / model parameter represented as a range, lower and upper bound, based on a specified probability interval known as the confidence level.
We communicate confidence intervals like this:
there is a 95% probability (or 19 times out of 20) that model slope is between 0.5 and 0.7.
We cover analytical methods here, but we could also use the more flexible Bootstrap approach.
That’s enough here, let’s load data and explain more as we demonstrate linear regression.
Load the Required Libraries#
We will also need some standard packages. These should have been installed with Anaconda 3.
suppress_warnings = False # select to suppress warnings
import os # to set current working directory
import math # square root
import numpy as np # arrays and matrix math
import scipy.stats as st # statistical methods
import pandas as pd # DataFrames
import matplotlib.pyplot as plt # for plotting
from matplotlib.ticker import (MultipleLocator, AutoMinorLocator) # control of axes ticks
from sklearn.preprocessing import MinMaxScaler # min/max normalization
from sklearn.linear_model import LinearRegression # linear regression
from sklearn.model_selection import train_test_split # train and test split
cmap = plt.cm.inferno # default color bar, no bias and friendly for color vision defeciency
plt.rc('axes', axisbelow=True) # grid behind plotting elements
if suppress_warnings == True:
import warnings # suppress any warnings for this demonstration
warnings.filterwarnings('ignore')
If you get a package import error, you may have to first install some of these packages. This can usually be accomplished by opening up a command window on Windows and then typing ‘python -m pip install [package-name]’. More assistance is available with the respective package docs.
Declare Functions#
Let’s define a function to streamline the addition specified percentiles and major and minor gridlines to our plots.
def weighted_percentile(data, weights, perc): # calculate weighted percentile, iambr on StackOverflow
ix = np.argsort(data) # https://stackoverflow.com/questions/21844024/weighted-percentile-using-numpy/32216049
data = data[ix]
weights = weights[ix]
cdf = (np.cumsum(weights) - 0.5 * weights) / np.sum(weights)
return np.interp(perc, cdf, data)
def histogram_bounds(values,weights,color): # add uncertainty bounds to a histogram
p10 = weighted_percentile(values,weights,0.1); avg = np.average(values,weights=weights); p90 = weighted_percentile(values,weights,0.9)
plt.plot([p10,p10],[0.0,45],color = color,linestyle='dashed')
plt.plot([avg,avg],[0.0,45],color = color)
plt.plot([p90,p90],[0.0,45],color = color,linestyle='dashed')
def add_grid():
plt.gca().grid(True, which='major',linewidth = 1.0); plt.gca().grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
Set the Working Directory#
I always like to do this so I don’t lose files and to simplify subsequent read and writes (avoid including the full address each time). Also, in this case make sure to place the required (see below) data file in this working directory.
#os.chdir("C:\PGE337") # set the working directory
You will have to update the part in quotes with your own working directory and the format is different on a Mac (e.g. “~/PGE”).
Loading Tabular Data#
Here’s the command to load our comma delimited data file in to a Pandas’ DataFrame object.
Let’s load the provided multivariate, spatial dataset ‘unconv_MV.csv’. This dataset has variables from 1,000 unconventional wells including:
density (\(g/cm^{3}\))
porosity (volume %)
Note, the dataset is synthetic.
We load it with the pandas ‘read_csv’ function into a DataFrame we called ‘my_data’ and then preview it to make sure it loaded correctly.
add_error = False # add random error to the response feature for testing
std_error = 1.0; seed = 71071
yname = 'Porosity'; xname = 'Density' # specify the predictor features (x2) and response feature (x1)
xmin = 1.0; xmax = 2.5 # set minimums and maximums for visualization
ymin = 0.0; ymax = 25.0
yunit = '%'; xunit = '$g/cm^{3}$'
Xlabelunit = xname + ' (' + xunit + ')'
ylabelunit = yname + ' (' + yunit + ')'
#df = pd.read_csv("Density_Por_data.csv") # load the data from local current directory
df = pd.read_csv(r"https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/Density_Por_data.csv") # load the data from my github repo
df = df.sample(frac=.30, random_state = 73073); df = df.reset_index() # extract 30% random to reduce the number of data
if add_error == True: # method to add error
np.random.seed(seed=seed) # set random number seed
df[yname] = df[yname] + np.random.normal(loc = 0.0,scale=std_error,size=len(df)) # add noise
values = df._get_numeric_data(); values[values < 0] = 0 # set negative to 0 in a shallow copy ndarray
dfy = pd.DataFrame(df[yname]) # extract selected features as X and y DataFrames
dfx = pd.DataFrame(df[xname])
df = pd.concat([dfx,dfy],axis=1) # make one DataFrame with both X and y (remove all other features)
y = df[yname].values.reshape(len(df))
x = df[xname].values.reshape(len(df))
dX = np.linspace(xmin,xmax,100) # values for plotting the model
df
| Density | Porosity | |
|---|---|---|
| 0 | 1.906634 | 12.845691 |
| 1 | 1.404932 | 13.668073 |
| 2 | 1.795190 | 11.015021 |
| 3 | 1.705466 | 17.185360 |
| 4 | 1.821963 | 8.190405 |
| 5 | 1.708322 | 10.728462 |
| 6 | 1.897087 | 11.245838 |
| 7 | 1.864561 | 11.357547 |
| 8 | 2.119652 | 8.614564 |
| 9 | 1.301057 | 15.280571 |
| 10 | 1.774021 | 9.489298 |
| 11 | 1.410996 | 14.371990 |
| 12 | 1.697005 | 10.495092 |
| 13 | 0.996736 | 20.964941 |
| 14 | 1.783736 | 13.393518 |
| 15 | 1.743519 | 14.758068 |
| 16 | 1.348847 | 15.877907 |
| 17 | 2.331653 | 4.968240 |
| 18 | 1.438900 | 16.529857 |
| 19 | 1.766823 | 10.485052 |
| 20 | 1.802992 | 10.120258 |
| 21 | 1.750352 | 11.325941 |
| 22 | 1.885087 | 9.242607 |
| 23 | 2.044451 | 8.936061 |
| 24 | 1.778580 | 11.426343 |
| 25 | 1.552689 | 14.157303 |
| 26 | 2.022877 | 10.672887 |
| 27 | 1.530699 | 16.476751 |
| 28 | 1.753578 | 10.826057 |
| 29 | 1.791432 | 14.506748 |
| 30 | 1.830085 | 10.561222 |
| 31 | 1.479878 | 14.443138 |
Visualize the DataFrame#
Visualizing the DataFrame is useful first check of the data.
many things can go wrong, e.g., we loaded the wrong data, all the features did not load, etc.
We can preview by utilizing the ‘head’ DataFrame member function (with a nice and clean format, see below).
add parameter ‘n=13’ to see the first 13 rows of the dataset.
df.head(n=13) # we could also use this command for a table preview
| Density | Porosity | |
|---|---|---|
| 0 | 1.906634 | 12.845691 |
| 1 | 1.404932 | 13.668073 |
| 2 | 1.795190 | 11.015021 |
| 3 | 1.705466 | 17.185360 |
| 4 | 1.821963 | 8.190405 |
| 5 | 1.708322 | 10.728462 |
| 6 | 1.897087 | 11.245838 |
| 7 | 1.864561 | 11.357547 |
| 8 | 2.119652 | 8.614564 |
| 9 | 1.301057 | 15.280571 |
| 10 | 1.774021 | 9.489298 |
| 11 | 1.410996 | 14.371990 |
| 12 | 1.697005 | 10.495092 |
Summary Statistics for Tabular Data#
There are a lot of efficient methods to calculate summary statistics from tabular data in DataFrames. The describe command provides count, mean, minimum, maximum, and quartiles all in a nice data table.
We use transpose just to flip the table so that features are on the rows and the statistics are on the columns.
df.describe().transpose() # summary statistics
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Density | 32.0 | 1.719994 | 0.262314 | 0.996736 | 1.547192 | 1.770422 | 1.838704 | 2.331653 |
| Porosity | 32.0 | 12.317525 | 3.224611 | 4.968240 | 10.492582 | 11.341744 | 14.459041 | 20.964941 |
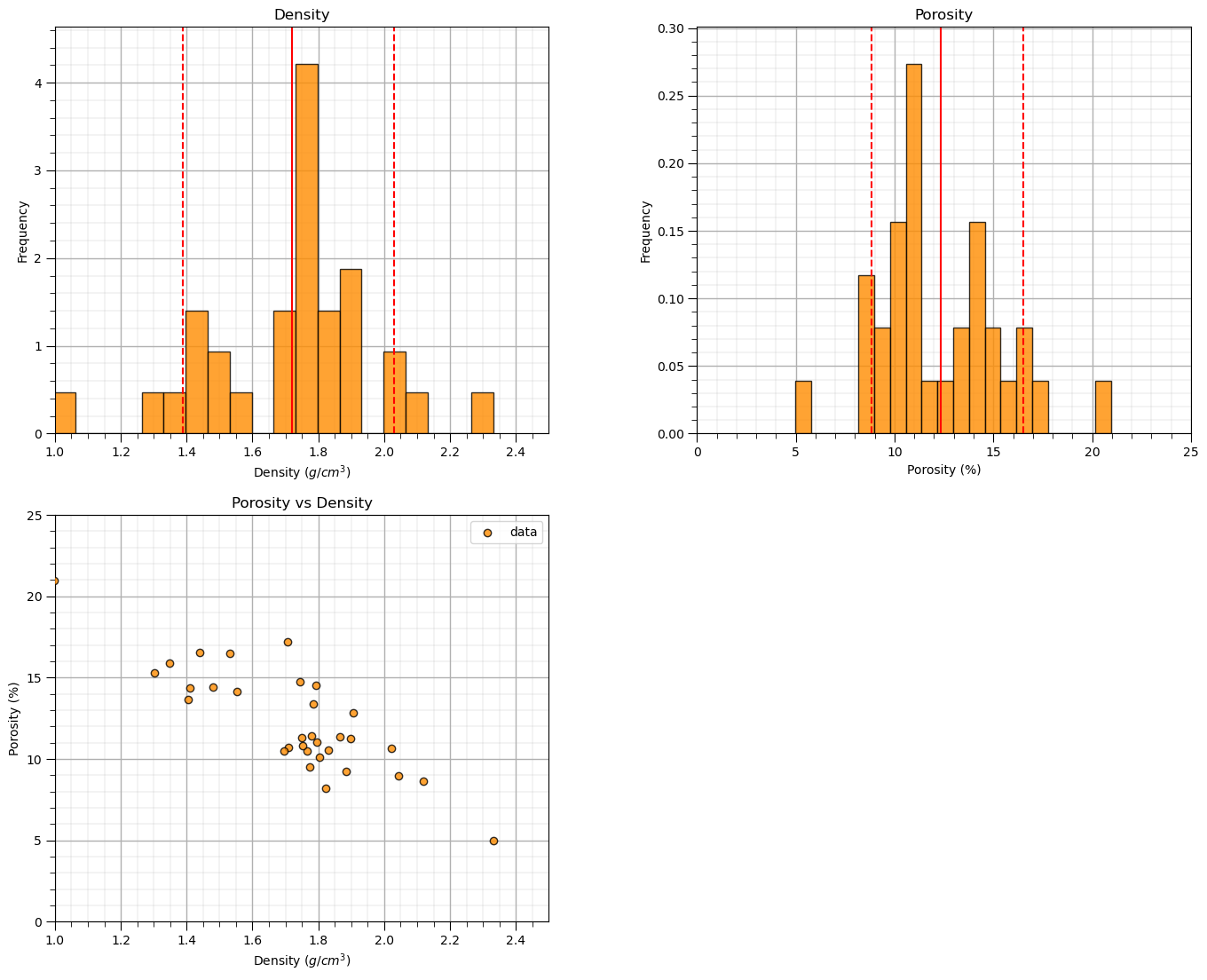
Data Visualization#
We should also take a look at the histograms.
get a sense of the range, modes, skew, outliers etc. for each feature
nbins = 20 # number of histogram bins
plt.subplot(221)
freq,_,_ = plt.hist(x=df[xname],weights=None,bins=nbins,alpha = 0.8,edgecolor='black',color='darkorange',density=True)
histogram_bounds(values=df[xname].values,weights=np.ones(len(df)),color='red')
plt.xlabel(xname + ' (' + xunit + ')'); plt.ylabel('Frequency'); plt.ylim([0.0,freq.max()*1.10]); plt.title('Density'); add_grid()
plt.xlim([xmin,xmax])
plt.subplot(222)
freq,_,_ = plt.hist(x=df[yname],weights=None,bins=nbins,alpha = 0.8,edgecolor='black',color='darkorange',density=True)
histogram_bounds(values=df[yname].values,weights=np.ones(len(df)),color='red')
plt.xlabel(yname + ' (' + yunit + ')'); plt.ylabel('Frequency'); plt.ylim([0.0,freq.max()*1.10]); plt.title('Porosity'); add_grid()
plt.xlim([ymin,ymax])
plt.subplot(223) # plot the model
plt.scatter(df[xname],df[yname],marker='o',label='data',color = 'darkorange',alpha = 0.8,edgecolor = 'black',zorder=10)
plt.title('Porosity vs Density')
plt.xlabel(xname + ' (' + xunit + ')')
plt.ylabel(yname + ' (' + yunit + ')')
plt.legend(); add_grid(); plt.xlim([xmin,xmax]); plt.ylim([ymin,ymax])
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=2.1, wspace=0.3, hspace=0.2)
#plt.savefig('Test.pdf', dpi=600, bbox_inches = 'tight',format='pdf')
plt.show()
Linear Regression Model#
Let’s first train a linear regression model to all our data with SciPy package, stats module.
we will develop more complicated cross validation training and tuning methods latter with training and testing data splits latter. For now all the data is used to train the model.
recall we imported the module as ‘st’ above
import scipy.stats as st # statistical methods
We instantiate, train the linear regression model and get model diagnostics for confidence intervals and hypothesis testing all in one line of code!
slope, intercept, r_value, p_value, std_err = st.linregress(x,y) # instantiate and fit a linear regression model
print('The model parameters are, slope (b1) = ' + str(round(slope,2)) + ', and the intercept (b0) = ' + str(round(intercept,2)))
The model parameters are, slope (b1) = -10.3, and the intercept (b0) = 30.03
Note that we have 5 outputs when we instantiate and fit our model.
slope - the slope of our linear model, the \(b_1\) in the model, \(y = b_1 x + b_0\)
intercept - the intercept of our linear model, the \(b_0\) in the model, \(y = b_1 x + b_0\)
r_value - the Pearson correlation, the square is the \(r^2\), the variance explained
p_value - the p-value for the hypothesis test for the slope of the model of zero
stderr - the standard error of the slope parameter, \(SE_{b_1}\)
Let’s plot the data and the model, to get out estimates we substitute our predictor feature values into our model.
x_values = np.linspace(xmin,xmax,100) # return an array of density values
y_model = slope * x_values + intercept # apply our linear regression model to estimate at the training data values
plt.subplot(111) # plot the model
plt.plot(x, y, 'o', label='data', color = 'darkorange', alpha = 0.8, markeredgecolor = 'black',zorder=10)
plt.plot(x_values, y_model, label='model', color = 'black',zorder=1)
plt.title('Linear Regression Model, Regression of ' + yname + ' on ' + xname)
plt.xlabel(xname + ' (' + xunit + ')')
plt.ylabel(yname + ' (' + yunit + ')')
plt.legend(); add_grid(); plt.xlim([xmin,xmax]); plt.ylim([ymin,ymax])
plt.annotate('Linear Regression Model',[1.25,5.7])
plt.annotate(r' $\beta_1$ :' + str(round(slope,2)),[1.6,4.1])
plt.annotate(r' $\beta_0$ :' + str(round(intercept,2)),[1.6,2.5])
plt.annotate(r'$N[\phi] = \beta_1 \times z + \beta_0$',[1.1,4.1])
plt.annotate(r'$N[\phi] = $' + str(round(slope,2)) + r' $\times$ $z$ + (' + str(round(intercept,2)) + ')',[1.1,2.5])
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.0, wspace=0.2, hspace=0.2); plt.show()
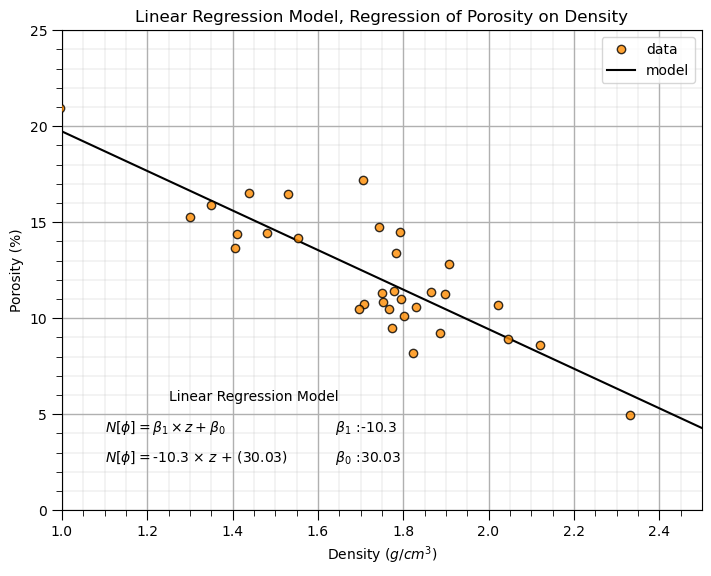
The model looks reasonable. Let’s go beyond occular inspection.
Model Checking with \(r^2\) Values#
Let’s first explain \(r^2\), proportion of variance explained. Here’s the variance explained by the model:
\begin{equation} 𝑠𝑠𝑟𝑒𝑔 = \sum_{𝑖=1}^{𝑛}\left(\hat{y}_i - \overline{y}\right)^2 \end{equation}
and the variance not explained by the model,
\begin{equation} 𝑠𝑠𝑟𝑒sid = \sum_{𝑖=1}^{𝑛}\left(y_i - \hat{y}\right)^2 \end{equation}
Now we can calculate the variance explained as,
\begin{equation} 𝑟^2 = \frac{𝑠𝑠_{𝑟𝑒𝑔}}{𝑠𝑠_{𝑟𝑒𝑔}+𝑠𝑠_{𝑟𝑒𝑠𝑖𝑑}} = \frac{\text{variance explained}}{\text{total variance}} \end{equation}
which is a common and intuitive metric for the goodness of a linear regression model.
Model Checking with Hypothesis Testing#
Let’s test the slope, \(b_1\), with the following hypothesis test,
\begin{equation} H_0: b_{1} = 0.0 \end{equation}
\begin{equation} H_1: b_{1} \ne 0.0 \end{equation}
and see if we can reject this hypothesis, \(H_{0}\) , that the slope parameter is equal to 0.0. If we reject this null hypothesis, we show that the slope is meaningful, there is a linear relationship between density and porosity that we can use.
Fortunately, the \(linregress\) function from the \(stats\) package provides us with the two sided p-value for this test.
print('Two-sided p-value for a hypothesis test whose null hypothesis is that the slope is zero = ' + str(p_value) + '.')
Two-sided p-value for a hypothesis test whose null hypothesis is that the slope is zero = 2.2197132981703346e-09.
Since the p-value is less than any reasonable \(\alpha\) value, we reject the null hypothesis and adopt the alternative hypothesis, \(H_1\), that the slope is not equal to 0.0.
We can also perform the entire hypothesis test by calculating the,
First we need the \(t_{critical}\) value, given \(\alpha\) and \(df = n-2\).
alpha = 0.05
t_critical = st.t.ppf([alpha/2,1-alpha/2], df=len(x)-2)
print('The t-critical lower and upper values are ' + str(np.round(t_critical,2)))
print('and the t-statistic is ' + str(round(slope/std_err,2)))
The t-critical lower and upper values are [-2.04 2.04]
and the t-statistic is -8.4
We see a consistent result with the previous hypothesis test with the p-value, since the \(t_{statistic}\) is outside the \(t_{critical}\) lower and upper interval, we reject the null hypothesis, \(h_0\), that the slope, \(b_1\) is equal to 0.0.
We can also observe correlation coefficient, \(r\) value, and the \(r^2\) value that indicates the proportion of variance that is described for our model.
print('The correlation coefficient is = ' + str(round(r_value,2)) + ' and the r-squared value = ', str(round(r_value**2,2)))
The correlation coefficient is = -0.84 and the r-squared value = 0.7
Confidence Intervals for Model Uncertainty#
Let’s calculate the 95% confidence interval for the slope parameter, \(b_1\) of our model. We just need our \(t_{critical}\) and the standard error in the slope, \(SE_{b_1}\).
print('The slope confidence interval is ' + str(round(slope,2)) + ' +/- ' + str(round(t_critical[1] * std_err,2)))
CI_slope = slope + t_critical*std_err
print('The slope P02.5 and P97.5 are ' + str(np.round(CI_slope,2)))
The slope confidence interval is -10.3 +/- 2.5
The slope P02.5 and P97.5 are [-12.8 -7.8]
Let’s visualize the model uncertainty through confidence intervals in the slope.
alpha = 0.05
tstat = st.t.ppf([alpha/2,1-alpha/2], len(x)-2) # calculate t-stat for confidence interval
slope_lower,slope_upper = slope + tstat*std_err # calculate the lower and upper confidence interval for b1
plt.scatter(x, y, color = 'darkorange',edgecolor='black',alpha=0.8,label='sample data',zorder=10)
plt.plot(dX, intercept + slope*dX, 'black', label='linear regression model')
plt.plot(dX, intercept + slope_upper*dX, 'black',ls='--',lw=1,label=r'alpha = ' + str(alpha) + ' confidence interval')
plt.plot(dX, intercept + slope_lower*dX, 'black',ls='--',lw=1)
plt.annotate('The model parameters confidence intervals at ' + str(1-alpha) + ' significance level:',[1.3,24])
plt.annotate('Slope: P' + str(alpha/2*100) + ' = '+ str(round(slope_lower,2)) + ' , P' + str((1-alpha/2)*100) + ' = ' + str(round(slope_upper,2)),[1.5,23])
plt.fill_between(dX,intercept + slope_upper*dX,intercept + slope_lower*dX,color='red',alpha=0.3,zorder=1)
plt.title('Sample Data, Linear Regression Model and Slope Confidence Intervals'); plt.xlabel(r'Density ($g/cm^3$)'); plt.ylabel('Porosity (%)')
plt.legend(loc='lower left'); add_grid(); plt.ylim([ymin,ymax]); plt.xlim([xmin,xmax])
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.1, hspace=0.2); plt.show()
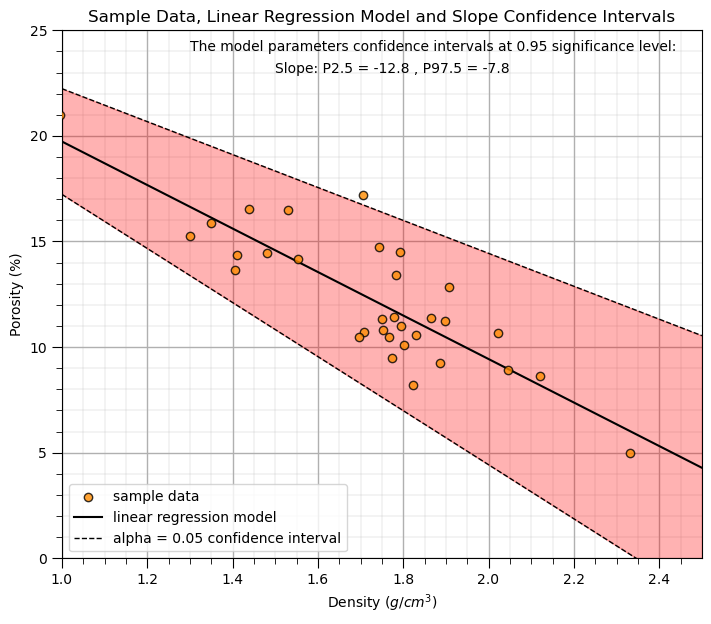
Model Prediction Intervals#
Let’s calculate the prediction intervals.
\begin{equation} \hat{y}{n+1} ± t{(\frac{\alpha}{2},n-2)} \sqrt{MSE}\ \times \sqrt{1+\frac{1}{n}+\frac{(x_{n+1}-\overline{x})^2}{\sum_{i=1}^{n}(x_{i}-\overline{x})^2} } \end{equation}
Note, this is the standard error of the prediction,
\begin{equation} SE_{\hat{y}{n+1}} = \sqrt{MSE}\ \times \sqrt{1+\frac{1}{n}+\frac{(x{n+1}-\overline{x})^2}{\sum_{i=1}^{n}(x_{i}-\overline{x})^2} } \end{equation}
where MSE, model mean square error calculated as,
\begin{equation} MSE = \sum_{i=1}^n\frac{(y_i - \hat{y}i)^2}{n-2} = \sum{i=1}^n \frac{\left(y_i - (b_1 x - b_0) \right)^2}{n-2} \end{equation}
Note, that this indicates that prediction intervals are wider the further we estimate from the mean of the predictor feature values. We can substitute model MSE, MSE, and standard error of the estimate, \(SE_{\hat{y}_{n+1}}\) for the final form is,
\begin{equation} \hat{y}{n+1} ± t{(\frac{\alpha}{2},n-2)} \sqrt{\sum_{i=1}^n \frac{\left(y_i - (b_1 x - b_0) \right)^2}{n-2}}\sqrt{1+\frac{1}{n}+\frac{(x_{n+1}-\overline{x})^2}{\sum_{i=1}^{n}(x_{i}-\overline{x})^2} } \end{equation}
Now let’s demonstrate a prediction interval.
select a X value, new_X below as the input, and the alpha level for the prediction interval, i.e., alpha = 0.05 results in the P025 and P975 results to define the interval
new_X = 2.00
alpha = 0.05
tstat = st.t.ppf([alpha/2,1-alpha/2], len(x)-2)
yhat = intercept + slope*x
MSE = np.sum(np.power(y-yhat,2))/(len(y)-2) # mean square error
est_stderr = math.sqrt(MSE) \
*math.sqrt(1 + 1/len(y) + np.power(new_X - np.average(x),2)/ \
np.sum(np.power(x-np.average(x),2)))
y_pred_lower, y_pred_upper = intercept + slope*new_X + tstat*est_stderr
plt.scatter(x, y, color = 'darkorange',edgecolor='black',alpha=0.8,label='sample data',zorder=1)
plt.plot(dX, intercept + slope*dX, 'black', label='linear regression model',zorder=1)
plt.scatter(new_X, intercept + slope*new_X,s=80,color='yellow',edgecolor='black',label=r'prediction, $\hat{y}$',zorder=2)
plt.plot([new_X,new_X],[y_pred_lower,y_pred_upper],color='black',linestyle='dashed',zorder=1,label='prediction interval')
plt.title(r'Sample Data, Linear Regression Model and Prediction Interval, $\alpha = $' + str(alpha)); plt.xlabel(r'Density ($g/cm^3$)');
plt.ylabel('Porosity (%)')
plt.legend(); add_grid(); plt.ylim([4,22]); plt.xlim([1.0,2.4])
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.4, wspace=0.1, hspace=0.2); plt.show()
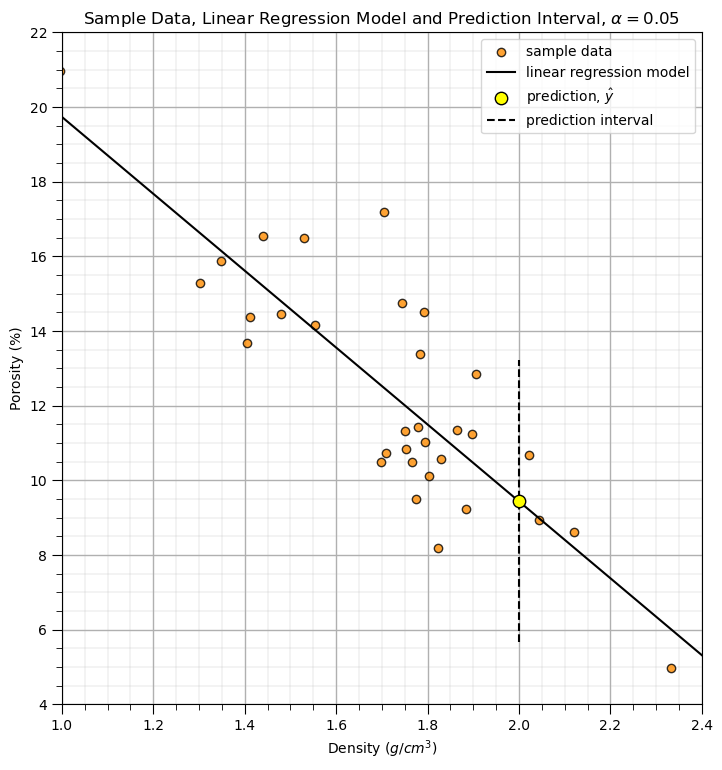
Prediction#
Now, let’s use this model to make a prediction at all the data locations.
y_hat = slope * x + intercept
plt.subplot(111)
plt.hist(y_hat, color = 'darkorange', alpha = 0.8, edgecolor = 'black', bins = np.linspace(5,20,40))
plt.xlabel(yname + ' (' + yunit + ')'); plt.ylabel('Frequency'); plt.title(yname + ' Predictions'); plt.xlim([ymin,ymax])
add_grid()
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.0, wspace=0.2, hspace=0.2); plt.show()
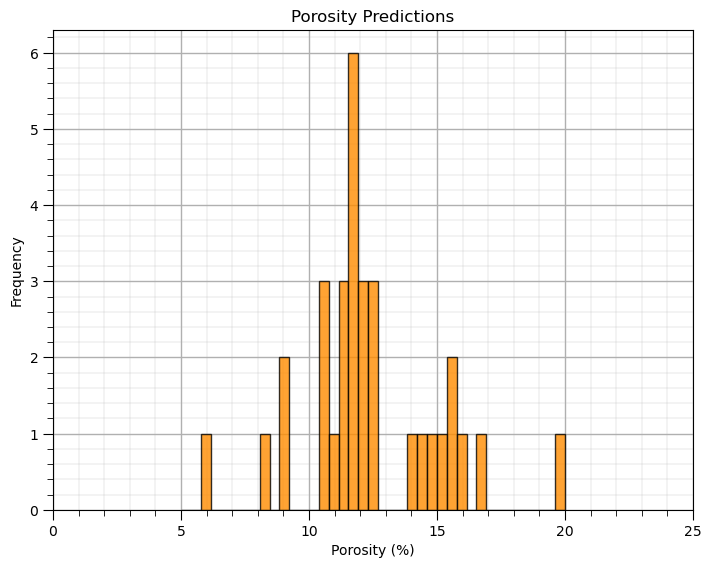
Checking Prediction Error#
It is useful to plot the predictions of porosity with the training porosity vs. density scatter plot.
From this plot we can observe the linear limitation of our model
and get a sense of the unexplained variance \(\frac{\sum_{i=1}^{n}(y_i - \hat{y}_i)^2} {n-1}\)
plt.subplot(111)
plt.plot(x, y, 'o', label='training data',color = 'darkorange', alpha = 1.0, markeredgecolor = 'black',zorder=10)
plt.scatter(x, y_hat,s=10,marker='o',label='prediction',color = 'grey',edgecolor='black',alpha=1.0,zorder=10)
plt.plot(dX,dX*slope+intercept,color='red',lw=2,zorder=2,label='model')
for idata in range(0,len(x)):
if idata == 0:
plt.plot([x[idata],x[idata]],[y[idata],y_hat[idata]],color='grey',label=r'$\Delta_{y_i}$',zorder=1)
else:
plt.plot([x[idata],x[idata]],[y[idata],y_hat[idata]],color='grey')
plt.title('Comparison of Training Data vs. Model')
plt.xlabel(xname + ' (' + xunit + ')')
plt.ylabel(yname + ' (' + yunit + ')')
plt.legend(); add_grid(); plt.xlim([xmin,xmax]); plt.ylim([ymin,ymax])
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.0, wspace=0.2, hspace=0.2); plt.show()
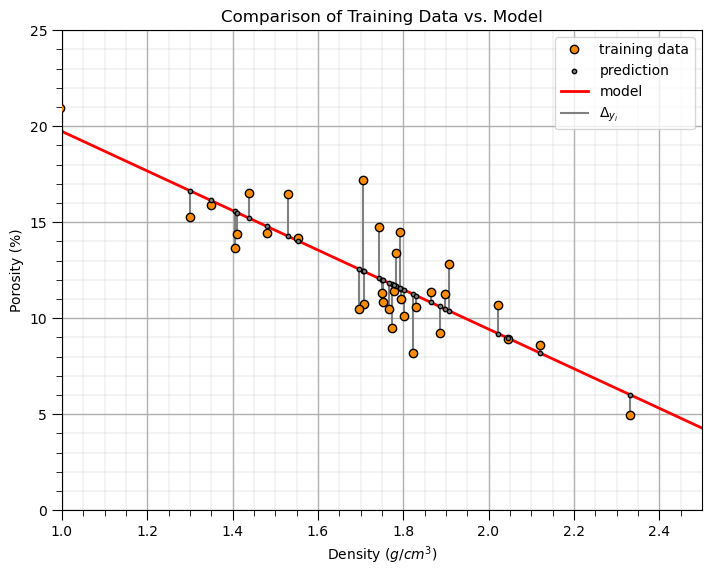
See the plotted error residuals,
where \(y_i\) are the true response values and \(\hat{y}_i\) are the estimated response values.
It is good to check the error residual distribution that,
the average is close to 0.0
the shape is not skewed
there are no outliers
Let’s look at the error residual distribution.
residual = y - y_hat
plt.subplot(111)
plt.hist(residual, color = 'darkorange', alpha = 0.8, edgecolor = 'black', bins = np.linspace(-4,4,30))
plt.title("Error Residual at Training Data"); plt.xlabel(yname + ' True - Estimate (%)');plt.ylabel('Frequency'); add_grid()
plt.vlines(0,0,4.2,color='red',lw=2,zorder=1); plt.vlines(np.average(residual),0,4.2,color='black',ls='--',zorder=10); plt.ylim([0,4.2])
plt.annotate('Residual Average = ' + str(np.round(np.average(residual),2)),[np.average(residual)-0.2,2.5],rotation=90.0)
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.0, wspace=0.2, hspace=0.2); plt.show()
print('The average of the residuals is ' + str(round(np.mean(residual),2)))
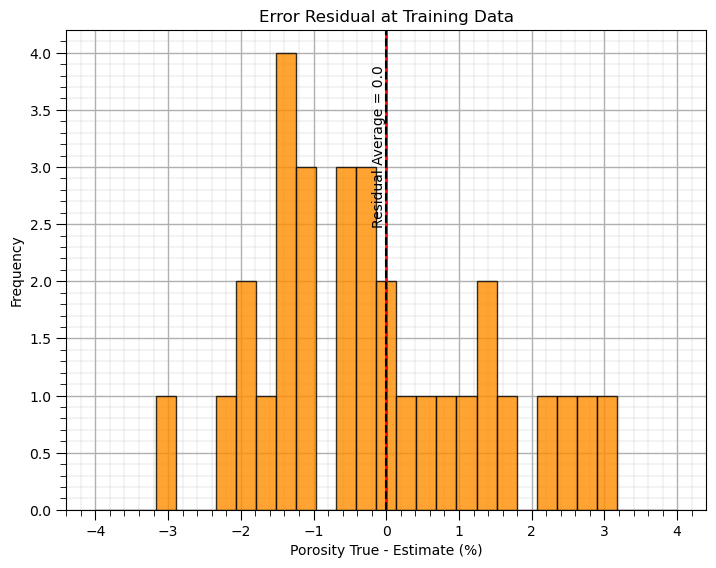
The average of the residuals is 0.0
Next we will check the truth vs. estimated scatter plot, and cross validation residual plot, residual vs. the fitted value.
with these plots we check if the errors are consistent over the range of fitted values
for example, we could use this plot to identify higher error or systematic under- or overestimation over a specific range of fitted values
slope_cross, intercept_cross, _, _, _ = st.linregress(y_hat,y) # check for conditional bias with a linear fit to the cross validation plot
plt.subplot(121)
plt.plot(y_hat, y, 'o', color = 'darkorange', alpha = 0.8, markeredgecolor = 'black')
plt.plot([ymin,ymax], [ymin,ymax], 'black',lw=2.0)
plt.plot(np.linspace(ymin,ymax,100), slope_cross*np.linspace(ymin,ymax,100)+intercept_cross,
alpha = 0.8, color = 'red',ls='--',lw=1.0)
plt.title('Cross Validation Plot: Truth vs. Estimated Value')
plt.xlabel(yname + ' Estimate (%)'); plt.ylabel(yname + ' Truth (%)'); add_grid(); plt.xlim([ymin,ymax]); plt.ylim([ymin,ymax])
plt.subplot(122)
plt.plot(y_hat, residual, 'o', color = 'darkorange', alpha = 0.8, markeredgecolor = 'black')
plt.plot([ymin,ymax], [0,0], 'black')
plt.title('Cross Validation Residual Plot: Residual vs. Estimated Value')
plt.xlabel(yname + ' Estimate (%)'); plt.ylabel(yname + ' Residual: True - Estimate (%)'); add_grid()
plt.xlim([ymin,ymax]); plt.ylim([-10,10])
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.2, wspace=0.2, hspace=0.2); plt.show()
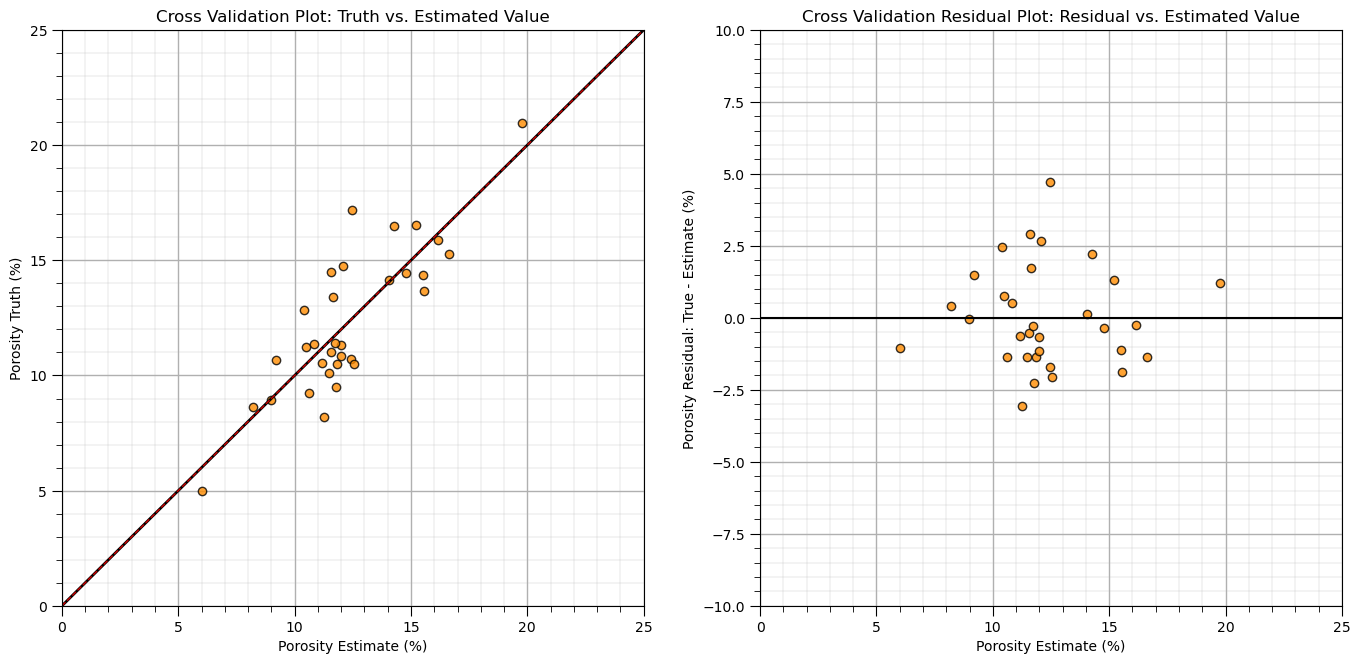
For the demonstration case, there is no apparent conditional bias in the estimates over the range of values.
Practice on a New Dataset#
Ok, time to get to work. Let’s load up a dataset and build a linear regression model with,
compact code
basic visaulizations
save the output
You can select any of these datasets or modify the code and add your own to do this.
Dataset 0, Unconventional Multivariate v4#
Let’s load the provided multivariate, dataset unconv_MV.csv. This dataset has variables from 1,000 unconventional wells including:
well average porosity
log transform of permeability (to linearize the relationships with other variables)
acoustic impedance (kg/m^3 x m/s x 10^6)
brittleness ratio (%)
total organic carbon (%)
vitrinite reflectance (%)
initial production 90 day average (MCFPD).
Dataset 1, Twelve, 12#
Let’s load the provided multivariate, 2D spatial dataset 12_sample_data.csv. This dataset has variables from 480 unconventional wells including:
X (m), Y (m) location coordinates
facies (0 - shale, 1 - sand)
porosity (%) after units conversion
permeability (mD)
acoustic impedance (kg/m^3 x m/s x 10^6)
Dataset 2, Reservoir 21#
Let’s load the provided multivariate, 3D spatial dataset res21_wells.csv. This dataset has variables from 73 vertical wells over a 10,000m x 10,000m x 50 m reservoir unit:
well (ID)
X (m), Y (m), Depth (m) location coordinates
Porosity (%) after units conversion
Permeability (mD)
Acoustic Impedance (kg/m2s*10^6) after units conversion
Facies (categorical) - ordinal with ordering from Shale, Sandy Shale, Shaley Sand, to Sandstone.
Density (g/cm^3)
Compressible velocity (m/s)
Youngs modulus (GPa)
Shear velocity (m/s)
Shear modulus (GPa)
3 year cumulative oil production (Mbbl)
We load the tabular data with the pandas ‘read_csv’ function into a DataFrame we called ‘my_data’ and then preview it to make sure it loaded correctly.
we also populate lists with data ranges and labels for ease of plotting
Load and format the data,
drop the response feature
reformate the features as needed
also, I like to store the metadata in lists
idata = 0 # select the dataset
if idata == 0:
df_new = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/unconv_MV_v4.csv') # load data from Dr. Pyrcz's GitHub repository
df_new.drop(['Well'],axis=1,inplace=True) # remove well index and response feature
features = df_new.columns.values.tolist() # store the names of the features
xname = features[:-1]
yname = [features[-1]]
xmin_new = [6.0,0.0,1.0,10.0,0.0,0.9]; xmax_new = [24.0,10.0,5.0,85.0,2.2,2.9] # set the minimum and maximum values for plotting
ymin_new = 0.0; ymax_new = 10000.0
xlabel_new = ['Porosity (%)','Permeability (mD)','Acoustic Impedance (kg/m2s*10^6)','Brittleness Ratio (%)', # set the names for plotting
'Total Organic Carbon (%)','Vitrinite Reflectance (%)']
ylabel_new = 'Production (MCFPD)'
xtitle_new = ['Porosity','Permeability','Acoustic Impedance','Brittleness Ratio', # set the units for plotting
'Total Organic Carbon','Vitrinite Reflectance']
ytitle_new = 'Production'
y = pd.DataFrame(df_new[yname]) # extract selected features as X and y DataFrames
X = df_new[xname]
elif idata == 1:
names = {'Porosity':'Por'}
df_new = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/12_sample_data.csv') # load data from Dr. Pyrcz's GitHub repository
df_new.drop(['X','Y','Unnamed: 0','Facies'],axis=1,inplace=True) # remove response feature
df_new = df_new.rename(columns=names)
df_new['Por'] = df_new['Por'] * 100.0; df_new['AI'] = df_new['AI'] / 1000.0
features = df_new.columns.values.tolist() # store the names of the features
xname = features[:-1]
yname = [features[-1]]
xmin_new = [4.0,0.0]; xmax_new = [19.0,500.0] # set the minimum and maximum values for plotting
ymin_new = 1.60; ymax_new = 6.20
xlabel_new = ['Porosity (fraction)','Permeability (mD)'] # set the names for plotting
ylabel_new = 'Acoustic Impedance (kg/m2s*10^6)'
xtitle_new = ['Porosity','Permeability']
ytitle_new = 'Acoustic Impedance (kg/m2s*10^6)'
y = pd.DataFrame(df_new[yname]) # extract selected features as X and y DataFrames
X = df_new[xname]
elif idata == 2:
df_new = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/res21_2D_wells.csv') # load data from Dr. Pyrcz's GitHub repository
df_new.drop(['Well_ID','X','Y'],axis=1,inplace=True) # remove Well Index, X and Y coordinates, and response feature
df_new = df_new.dropna(how='any',inplace=False)
features = df_new.columns.values.tolist() # store the names of the features
xname = features[:-1]
yname = [features[-1]]
xmin_new = [1,0.0,0.0,4.0,0.0,6.5,1.4,1600.0,10.0,1300.0,1.6]; xmax_new = [73,10000.0,10000.0,19.0,500.0,8.3,3.6,6200.0,50.0,2000.0,12.0] # set the minimum and maximum values for plotting
ymin_new = 0.0; ymax_new = 1600.0
xlabel_new = ['Well (ID)','X (m)','Y (m)','Depth (m)','Porosity (fraction)','Permeability (mD)','Acoustic Impedance (kg/m2s*10^6)','Facies (categorical)',
'Density (g/cm^3)','Compressible velocity (m/s)','Youngs modulus (GPa)', 'Shear velocity (m/s)', 'Shear modulus (GPa)'] # set the names for plotting
ylabel_new = 'Production (Mbbl)'
xtitle_new = ['Well','X','Y','Depth','Porosity','Permeability','Acoustic Impedance','Facies',
'Density','Compressible velocity','Youngs modulus', 'Shear velocity', 'Shear modulus']
ytitle_new = 'Production'
y = pd.DataFrame(df_new[yname]) # extract selected features as X and y DataFrames
X = df_new[xname]
df_new.head(n=13)
| Por | Perm | AI | Brittle | TOC | VR | Prod | |
|---|---|---|---|---|---|---|---|
| 0 | 12.08 | 2.92 | 2.80 | 81.40 | 1.16 | 2.31 | 1695.360819 |
| 1 | 12.38 | 3.53 | 3.22 | 46.17 | 0.89 | 1.88 | 3007.096063 |
| 2 | 14.02 | 2.59 | 4.01 | 72.80 | 0.89 | 2.72 | 2531.938259 |
| 3 | 17.67 | 6.75 | 2.63 | 39.81 | 1.08 | 1.88 | 5288.514854 |
| 4 | 17.52 | 4.57 | 3.18 | 10.94 | 1.51 | 1.90 | 2859.469624 |
| 5 | 14.53 | 4.81 | 2.69 | 53.60 | 0.94 | 1.67 | 4017.374438 |
| 6 | 13.49 | 3.60 | 2.93 | 63.71 | 0.80 | 1.85 | 2952.812773 |
| 7 | 11.58 | 3.03 | 3.25 | 53.00 | 0.69 | 1.93 | 2670.933846 |
| 8 | 12.52 | 2.72 | 2.43 | 65.77 | 0.95 | 1.98 | 2474.048178 |
| 9 | 13.25 | 3.94 | 3.71 | 66.20 | 1.14 | 2.65 | 2722.893266 |
| 10 | 15.04 | 4.39 | 2.22 | 61.11 | 1.08 | 1.77 | 3828.247174 |
| 11 | 16.19 | 6.30 | 2.29 | 49.10 | 1.53 | 1.86 | 5095.810104 |
| 12 | 16.82 | 5.42 | 2.80 | 66.65 | 1.17 | 1.98 | 4091.637316 |
df_select = df_new.loc[:,['Por','Perm','AI']]
df_select
| Por | Perm | AI | |
|---|---|---|---|
| 0 | 12.08 | 2.92 | 2.80 |
| 1 | 12.38 | 3.53 | 3.22 |
| 2 | 14.02 | 2.59 | 4.01 |
| 3 | 17.67 | 6.75 | 2.63 |
| 4 | 17.52 | 4.57 | 3.18 |
| ... | ... | ... | ... |
| 195 | 11.95 | 3.13 | 2.97 |
| 196 | 17.99 | 9.87 | 3.38 |
| 197 | 12.12 | 2.27 | 3.52 |
| 198 | 15.55 | 4.48 | 2.48 |
| 199 | 20.89 | 7.54 | 3.23 |
200 rows × 3 columns
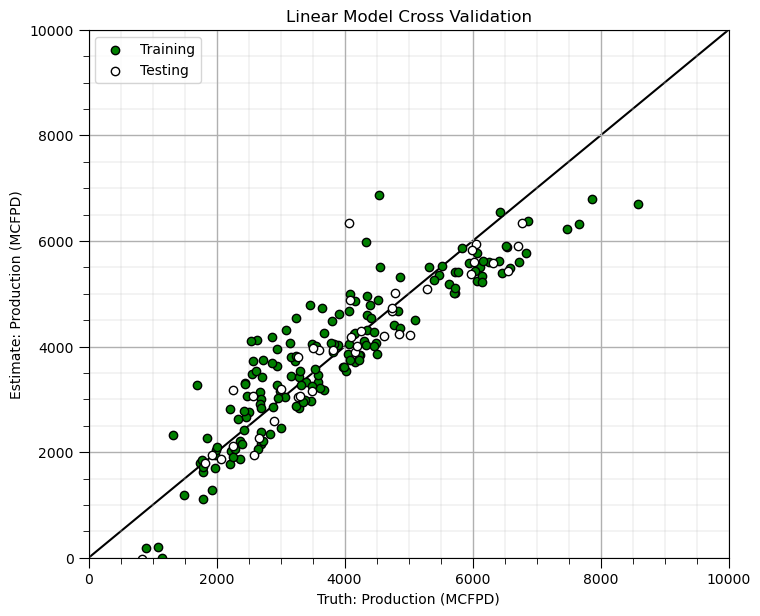
Build and Check Model#
test_prop = 0.2
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_prop, random_state=seed) # train and test split
linear_model_new = LinearRegression().fit(X_train,y_train) # instantiate and train linear regression model, no hyperparmeters
train_pred = linear_model_new.predict(X_train); test_pred = linear_model_new.predict(X_test) # predict at train and test samples
plt.scatter(y_train,train_pred,color='green',edgecolor='black',label='Training') # cross validation plot
plt.scatter(y_test,test_pred,color='white',edgecolor='black',label='Testing')
plt.plot([ymin_new,ymax_new],[ymin_new,ymax_new],color='black',zorder=-1)
plt.xlim(ymin_new,ymax_new); plt.ylim(ymin_new,ymax_new); add_grid()
plt.xlabel('Truth: ' + ylabel_new); plt.ylabel('Estimate: ' + ylabel_new)
plt.title('Linear Model Cross Validation'); plt.legend(loc='upper left')
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.2, hspace=0.2); plt.show()
X_train
| Por | Perm | AI | Brittle | TOC | VR | |
|---|---|---|---|---|---|---|
| 16 | 19.55 | 8.41 | 3.08 | 35.49 | 1.34 | 1.95 |
| 15 | 11.34 | 2.72 | 3.43 | 58.03 | 0.57 | 2.15 |
| 179 | 7.22 | 1.42 | 3.60 | 63.09 | -0.03 | 1.67 |
| 109 | 15.19 | 5.05 | 3.11 | 57.97 | 1.15 | 2.16 |
| 134 | 12.83 | 2.69 | 3.67 | 17.20 | 0.61 | 2.01 |
| ... | ... | ... | ... | ... | ... | ... |
| 32 | 12.55 | 3.22 | 3.43 | 56.93 | 0.79 | 2.27 |
| 182 | 9.88 | 2.72 | 3.64 | 55.19 | 0.52 | 2.16 |
| 71 | 14.17 | 3.94 | 2.92 | 59.30 | 0.91 | 1.91 |
| 112 | 18.24 | 4.31 | 2.85 | 44.53 | 1.39 | 2.06 |
| 163 | 11.60 | 1.73 | 2.18 | 53.54 | 0.60 | 1.50 |
160 rows × 6 columns
About the Author#

Michael Pyrcz is a professor in the Cockrell School of Engineering, and the Jackson School of Geosciences, at The University of Texas at Austin, where he researches and teaches subsurface, spatial data analytics, geostatistics, and machine learning. Michael is also,
the principal investigator of the Energy Analytics freshmen research initiative and a core faculty in the Machine Learn Laboratory in the College of Natural Sciences, The University of Texas at Austin
an associate editor for Computers and Geosciences, and a board member for Mathematical Geosciences, the International Association for Mathematical Geosciences.
Michael has written over 70 peer-reviewed publications, a Python package for spatial data analytics, co-authored a textbook on spatial data analytics, Geostatistical Reservoir Modeling and author of two recently released e-books, Applied Geostatistics in Python: a Hands-on Guide with GeostatsPy and Applied Machine Learning in Python: a Hands-on Guide with Code.
All of Michael’s university lectures are available on his YouTube Channel with links to 100s of Python interactive dashboards and well-documented workflows in over 40 repositories on his GitHub account, to support any interested students and working professionals with evergreen content. To find out more about Michael’s work and shared educational resources visit his Website.
Want to Work Together?#
I hope this content is helpful to those that want to learn more about subsurface modeling, data analytics and machine learning. Students and working professionals are welcome to participate.
Want to invite me to visit your company for training, mentoring, project review, workflow design and / or consulting? I’d be happy to drop by and work with you!
Interested in partnering, supporting my graduate student research or my Subsurface Data Analytics and Machine Learning consortium (co-PI is Professor John Foster)? My research combines data analytics, stochastic modeling and machine learning theory with practice to develop novel methods and workflows to add value. We are solving challenging subsurface problems!
I can be reached at mpyrcz@austin.utexas.edu.
I’m always happy to discuss,
Michael
Michael Pyrcz, Ph.D., P.Eng. Professor, Cockrell School of Engineering and The Jackson School of Geosciences, The University of Texas at Austin
More Resources Available at: Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Comments#
This was a basic treatment of linear regression. Much more could be done and discussed, I have many more resources. Check out my shared resource inventory and the YouTube lecture links at the start of this chapter with resource links in the videos’ descriptions.
I hope this is helpful,
Michael