

Feature Ranking#
Michael J. Pyrcz, Professor, The University of Texas at Austin
Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Chapter of e-book “Applied Machine Learning in Python: a Hands-on Guide with Code”.
Cite this e-Book as:
Pyrcz, M.J., 2024, Applied Machine Learning in Python: A Hands-on Guide with Code [e-book]. Zenodo. doi:10.5281/zenodo.15169138 ![]()
The workflows in this book and more are available here:
Cite the MachineLearningDemos GitHub Repository as:
Pyrcz, M.J., 2024, MachineLearningDemos: Python Machine Learning Demonstration Workflows Repository (0.0.3) [Software]. Zenodo. DOI: 10.5281/zenodo.13835312. GitHub repository: GeostatsGuy/MachineLearningDemos ![]()
By Michael J. Pyrcz
© Copyright 2024.
This chapter is a tutorial for / demonstration of Feature Ranking.
YouTube Lecture: check out my lectures on:
These lectures are all part of my Machine Learning Course on YouTube with linked well-documented Python workflows and interactive dashboards. My goal is to share accessible, actionable, and repeatable educational content. If you want to know about my motivation, check out Michael’s Story.
Motivation for Feature Ranking#
There are often many predictor features (input variables), available for us to work with for building our prediction models.
there are good reasons to be selective, throwing in every possible feature is not a good idea!
In general, for the best prediction model, careful selection of the fewest features that provide the most amount of information is the best practice.
Here’s why:
blunders - more predictor features result in more complicated workflows that require more professional time and have increased opportunity for mistakes in the workflow
difficult to visualize - higher dimensional models, i.e., larger number of predictor features, are more difficult to visualize
model checking - more complicated models may be more difficult to interrogate, interpret and QC
predictor feature redundancy - more likely to have redundant predictor features. The inclusion of highly redundant and collinear or multicollinear features increases model variance, increase model instability and decreases prediction accuracy for testing
computational time - more predictor features generally increase the computational time required to train the model and the computational storage, i.e., the model may be less compact and portable
model overfit - the risk of overfit increases with the more features, due to increase in model complexity
model extrapolation - many predictor features results in high dimensional model space with less data coverage and more likelihood for model extrapolation that may be inaccurate
The primary concern with many predictor features is the curse of dimensionality. Let’s summarize the curse!
Curse of Dimensionality#
Data and Model Visualization - we cannot visualize beyond 3D, i.e., access the model fit to data, evaluate interpolation vs. extrapolation.
consider a 5D example shown as a matrix scatter plot, even in this case there is an extreme marginalization to 2D for each plot,
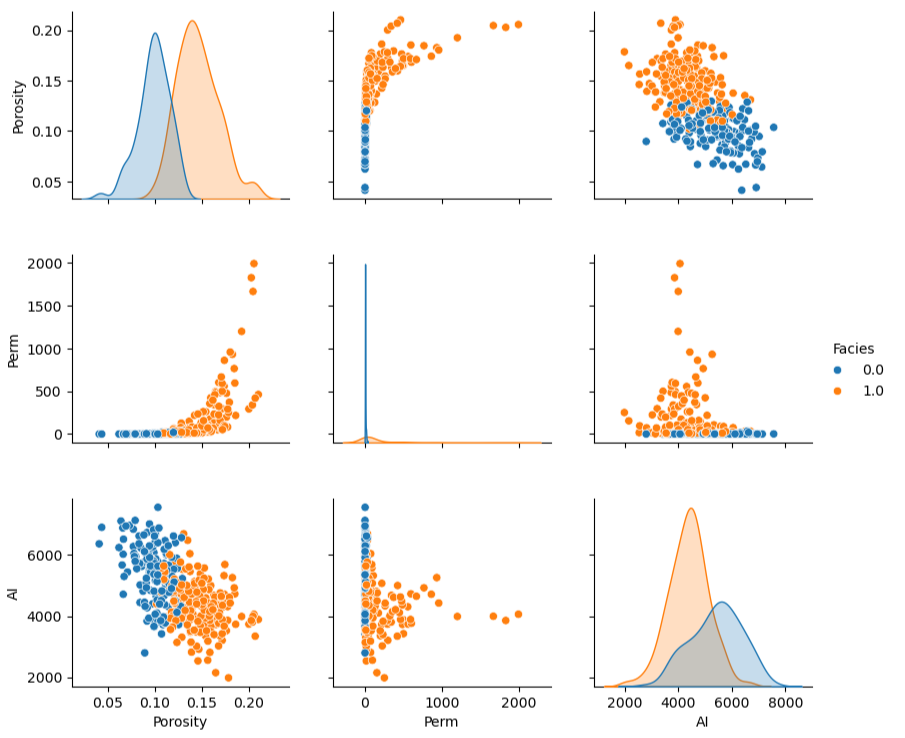
Sampling - the number of samples sufficient to infer statistics like the joint probability, \(P(x_1,\ldots,x_m)\).
recall the calculation of a histogram or normalized histogram: we establish bins and calculate frequencies or probabilities in each bin.
we require a nominal number of data samples for each bin, so we require \(𝑛=𝑛_{𝑠/𝑏𝑖𝑛} \cdot 𝑛_{𝑏𝑖𝑛𝑠}\) samples in 1D
but in mD we required \(n\) samples to calculate the discretized joint probability,
for example, 10 samples per bin with 35 bins requires 12,250 samples in 2D, and 428,750 samples in 3D
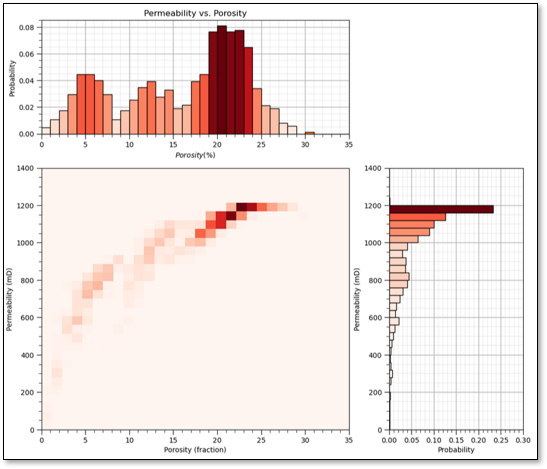
Sample Coverage - the range of the sample values cover the predictor feature space.
fraction of the possible solution space that is sampled, for 1 feature we assume 80% coverage
remember, we usually, directly sample only \(\frac{1}{10^7}\) of the volume of the subsurface
yes, the concept of coverage is subjective, how much data to cover? What about gaps? etc.
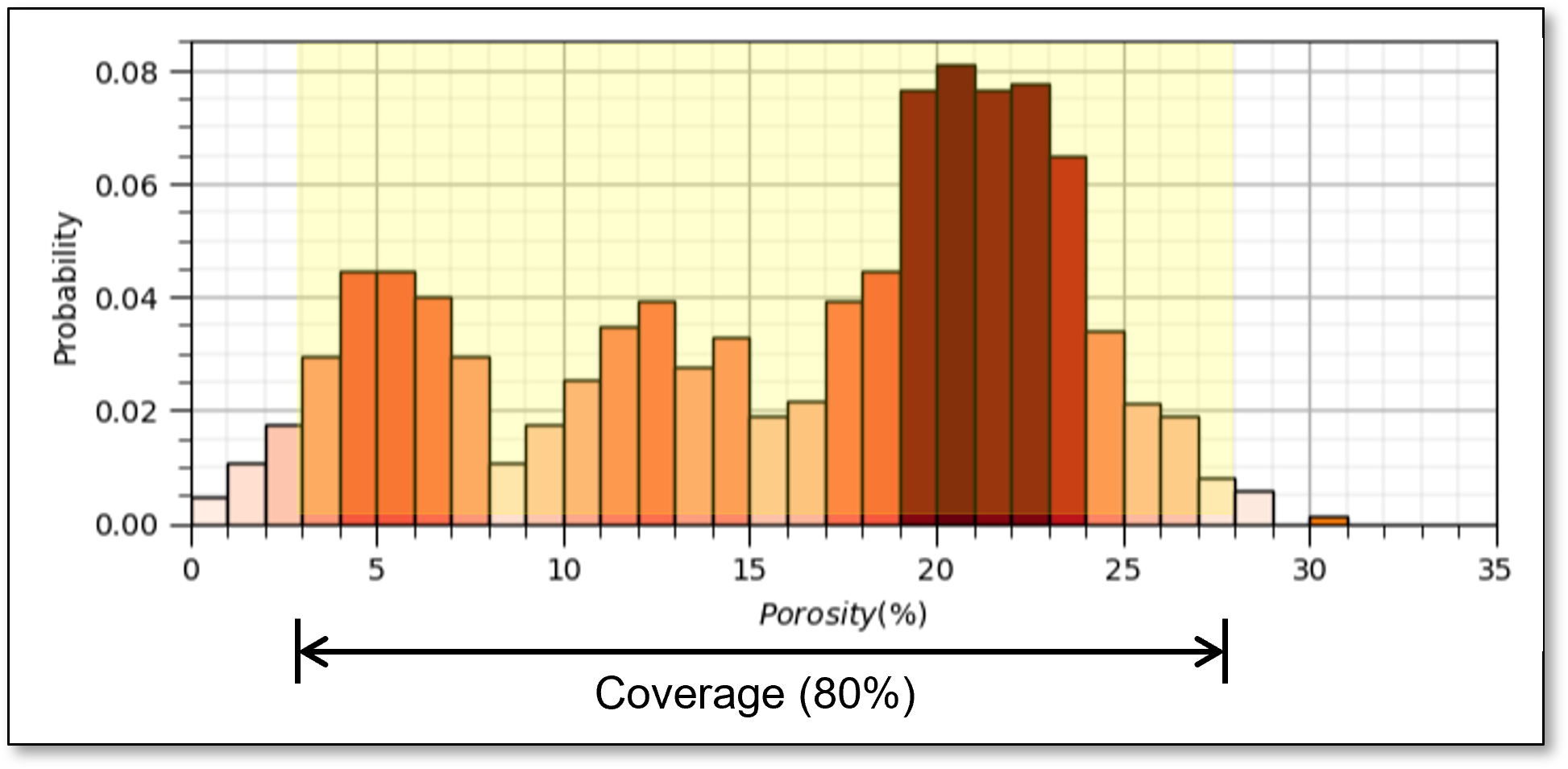
now if there is 80% coverage for 2 features the 2D coverage is 64%
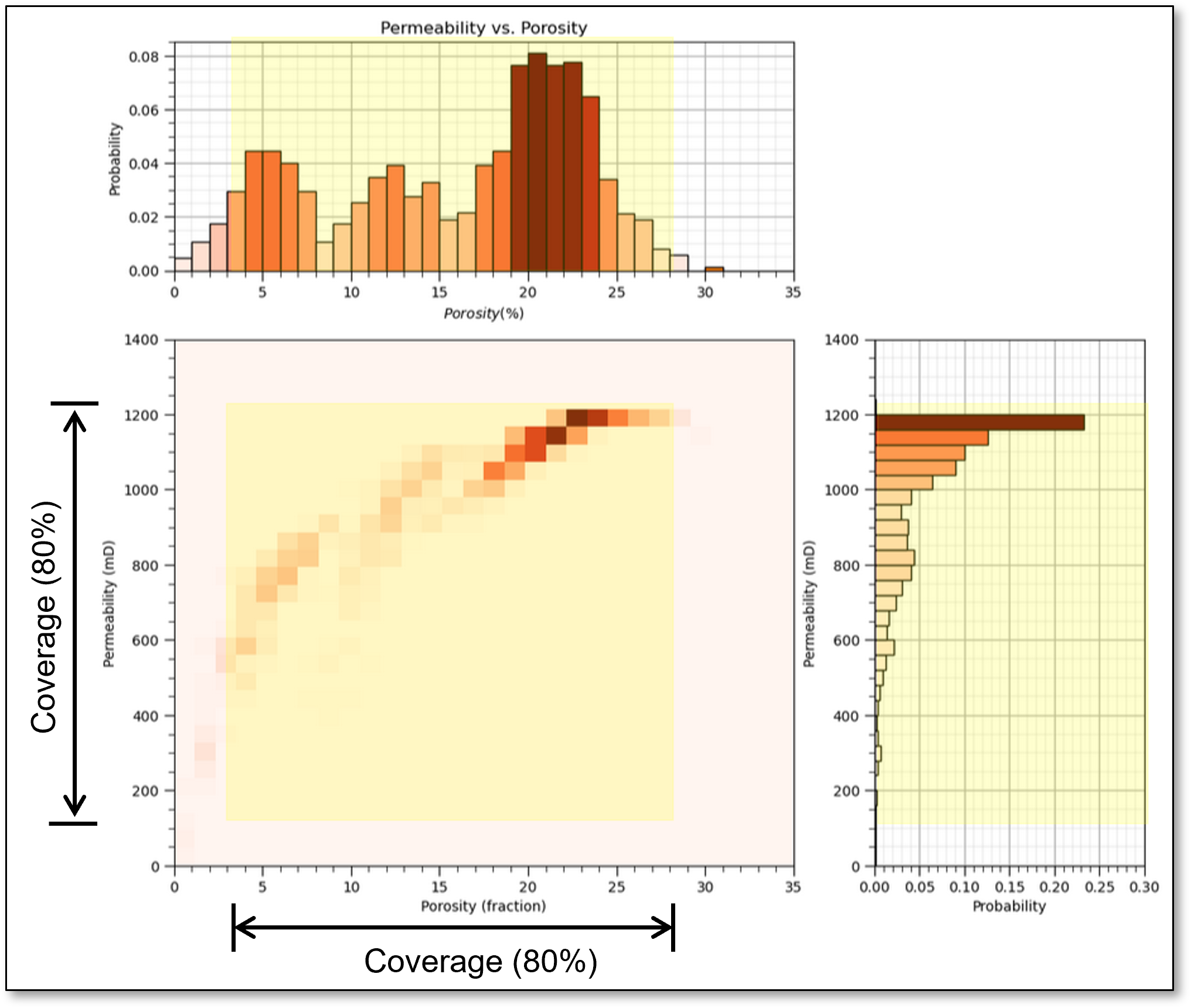
coverage is,
Distorted Space - high dimensional space is distorted.
take the ratio of the volume of an inscribed hypersphere in a hypercube,
recall, \(\Gamma(𝑛)=(𝑛−1)!\).
high dimensional space is all corners and no middle and most of high dimensional space is far from the middle (all corners!).
as a result distances in high dimensional space lose sensitivity, i.e., for any random points in the space the expected pairwise distances all become the same,
the limit of the expectation of the range of pairwise distances over random points in hyper-dimensional space tends to zero. If distances are almost all the same, Euclidian distance is no longer meaningful!
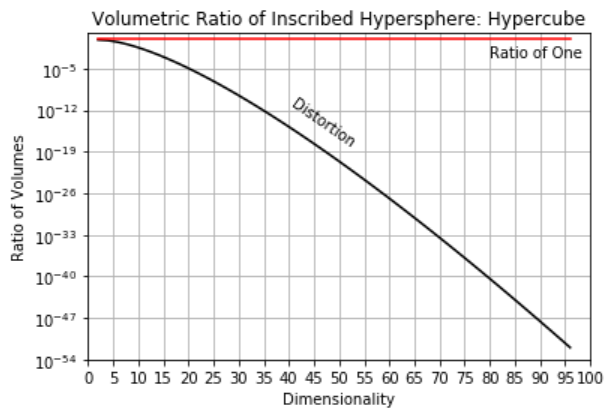
here’s the severity of the distortion for various dimensionalities,
m |
nD / 2D |
|---|---|
2 |
1.0 |
5 |
0.28 |
10 |
0.003 |
20 |
0.00000003 |
Multicollinearity - higher dimensional datasets are more likely to have collinearity or multicollinearity.
Feature linearly described by other features resulting in high model variance.
What is Feature Ranking?#
Feature ranking is a set of metrics that assign relative importance or value to each predictor feature with respect to information contained for inference and importance in predicting a response feature. There are a wide variety of possible methods to accomplish this. My recommendation is a ‘wide-array’ approach with multiple analyses and metrics, while understanding the assumptions and limitations of each method.
Here’s the general types of metrics that we consider for feature ranking.
Visual Inspection of Data Distributions and Scatter Plots
Statistical Summaries
Model-based
Recursive Feature Elimination
Also, we should not neglect expert knowledge. If additional information is known about physical processes, causation, reliability and availability of predictor features this should be integrated into assigning feature ranking.
Load the Required Libraries#
The following code loads the required libraries.
import geostatspy.GSLIB as GSLIB # GSLIB utilities, visualization and wrapper
import geostatspy.geostats as geostats # GSLIB methods convert to Python
import geostatspy
print('GeostatsPy version: ' + str(geostatspy.__version__))
GeostatsPy version: 0.0.71
We will also need some standard packages. These should have been installed with Anaconda 3.
ignore_warnings = True # ignore warnings?
import numpy as np # ndarrays for gridded data
import pandas as pd # DataFrames for tabular data
from sklearn import preprocessing # remove encoding error
from sklearn.feature_selection import RFE # for recursive feature selection
from sklearn.feature_selection import mutual_info_regression # mutual information
from sklearn.linear_model import LinearRegression # linear regression model
from sklearn.ensemble import RandomForestRegressor # model-based feature importance
from sklearn import metrics # measures to check our models
from statsmodels.stats.outliers_influence import variance_inflation_factor # variance inflation factor
import os # set working directory, run executables
import math # basic math operations
import random # for random numbers
import matplotlib.pyplot as plt # for plotting
from matplotlib.ticker import (MultipleLocator, AutoMinorLocator) # control of axes ticks
from matplotlib.colors import ListedColormap # custom color maps
import matplotlib.ticker as mtick # control tick label formatting
import seaborn as sns # for matrix scatter plots
from scipy import stats # summary statistics
import numpy.linalg as linalg # for linear algebra
import scipy.spatial as sp # for fast nearest neighbor search
import scipy.signal as signal # kernel for moving window calculation
from numba import jit # for numerical speed up
from statsmodels.stats.weightstats import DescrStatsW
plt.rc('axes', axisbelow=True) # plot all grids below the plot elements
if ignore_warnings == True:
import warnings
warnings.filterwarnings('ignore')
cmap = plt.cm.inferno # color map
For the Shapley value approach for feature ranking we need an additional package and to start up javascript support.
after running this block you should see a hexagon with the text ‘js’ to indicate that javascript is ready
import sys
#!{sys.executable} -m pip install shap
import shap
shap.initjs()

If you get a package import error, you may have to first install some of these packages. This can usually be accomplished by opening up a command window on Windows and then typing ‘python -m pip install [package-name]’. More assistance is available with the respective package docs.
Design Custom Color Map#
Accounting for significance by masking nonsignificant values
for demonstration only currently, could be updated for each plot based on results confidence and uncertainty
my_colormap = plt.cm.get_cmap('RdBu_r', 256) # make a custom colormap
newcolors = my_colormap(np.linspace(0, 1, 256)) # define colormap space
white = np.array([250/256, 250/256, 250/256, 1]) # define white color (4 channel)
#newcolors[26:230, :] = white # mask all correlations less than abs(0.8)
#newcolors[56:200, :] = white # mask all correlations less than abs(0.6)
newcolors[76:180, :] = white # mask all correlations less than abs(0.4)
signif = ListedColormap(newcolors) # assign as listed colormap
my_colormap = plt.cm.get_cmap('inferno', 256) # make a custom colormap
newcolors = my_colormap(np.linspace(0, 1, 256)) # define colormap space
white = np.array([250/256, 250/256, 250/256, 1]) # define white color (4 channel)
#newcolors[26:230, :] = white # mask all correlations less than abs(0.8)
newcolors[0:12, :] = white # mask all correlations less than abs(0.6)
#newcolors[86:170, :] = white # mask all correlations less than abs(0.4)
sign1 = ListedColormap(newcolors) # assign as listed colormap
Declare Functions#
Here’s a couple of functions to assist with calculating metrics for ranking and other plots:
plot_corr - plot a correlation matrix
partial_corr - partial correlation coefficient
semipar_corr - semipartial correlation coefficient
mutual_matrix - mutual information matrix, matrix of all pairwise mutual information
mutual_information_objective - my modified version of the MRMR loss function (Ixy - average(Ixx)) for feature ranking (uses all other predictor features)
delta_mutual_information_quotient - change in mutual information quotient by adding and removing a specific feature (uses all other predictor features for the comparison)
weighted_avg_and_std - average and standard deviation account for data weights
weighted_percentile - percentile accounting for data weights
histogram_bounds - add confidence intervals to histograms
add_grid - convenience function to add major and minor gridlines to improve plot interpretability
Here are the functions:
def feature_rank_plot(pred,metric,mmin,mmax,nominal,title,ylabel,mask): # feature ranking plot
mpred = len(pred); mask_low = nominal-mask*(nominal-mmin); mask_high = nominal+mask*(mmax-nominal)
plt.plot(pred,metric,color='black',zorder=20)
plt.scatter(pred,metric,marker='o',s=10,color='black',zorder=100)
plt.plot([-0.5,mpred-0.5],[0.0,0.0],'r--',linewidth = 1.0,zorder=1)
plt.fill_between(np.arange(0,mpred,1),np.zeros(mpred),metric,where=(metric < nominal),interpolate=True,color='dodgerblue',alpha=0.3)
plt.fill_between(np.arange(0,mpred,1),np.zeros(mpred),metric,where=(metric > nominal),interpolate=True,color='lightcoral',alpha=0.3)
plt.fill_between(np.arange(0,mpred,1),np.full(mpred,mask_low),metric,where=(metric < mask_low),interpolate=True,color='blue',alpha=0.8,zorder=10)
plt.fill_between(np.arange(0,mpred,1),np.full(mpred,mask_high),metric,where=(metric > mask_high),interpolate=True,color='red',alpha=0.8,zorder=10)
plt.xlabel('Predictor Features'); plt.ylabel(ylabel); plt.title(title)
plt.ylim(mmin,mmax); plt.xlim([-0.5,mpred-0.5]); add_grid();
plt.xticks(rotation=270.0)
return
def plot_corr(corr_matrix,title,limits,mask): # plots a graphical correlation matrix
my_colormap = plt.cm.get_cmap('RdBu_r', 256)
newcolors = my_colormap(np.linspace(0, 1, 256))
white = np.array([256/256, 256/256, 256/256, 1])
white_low = int(128 - mask*128); white_high = int(128+mask*128)
newcolors[white_low:white_high, :] = white # mask all correlations less than abs(0.8)
newcmp = ListedColormap(newcolors)
m = corr_matrix.shape[0]
im = plt.matshow(corr_matrix,fignum=0,vmin = -1.0*limits, vmax = limits,cmap = newcmp)
plt.xticks(range(len(corr_matrix.columns)), corr_matrix.columns); ax = plt.gca()
ax.xaxis.set_label_position('bottom'); ax.xaxis.tick_bottom()
plt.yticks(range(len(corr_matrix.columns)), corr_matrix.columns)
plt.colorbar(im, orientation = 'vertical')
plt.title(title)
for i in range(0,m):
plt.plot([i-0.5,i-0.5],[-0.5,m-0.5],color='black')
plt.plot([-0.5,m-0.5],[i-0.5,i-0.5],color='black')
plt.ylim([-0.5,m-0.5]); plt.xlim([-0.5,m-0.5])
plt.xticks(rotation=270.0)
def partial_corr(C): # partial correlation by Fabian Pedregosa-Izquierdo, f@bianp.net
C = np.asarray(C)
p = C.shape[1]
P_corr = np.zeros((p, p), dtype=float)
for i in range(p):
P_corr[i, i] = 1
for j in range(i+1, p):
idx = np.ones(p, dtype=bool)
idx[i] = False
idx[j] = False
beta_i = linalg.lstsq(C[:, idx], C[:, j])[0]
beta_j = linalg.lstsq(C[:, idx], C[:, i])[0]
res_j = C[:, j] - C[:, idx].dot( beta_i)
res_i = C[:, i] - C[:, idx].dot(beta_j)
corr = stats.pearsonr(res_i, res_j)[0]
P_corr[i, j] = corr
P_corr[j, i] = corr
return P_corr
def semipartial_corr(C): # Michael Pyrcz modified the function above by Fabian Pedregosa-Izquierdo, f@bianp.net for semipartial correlation
C = np.asarray(C)
p = C.shape[1]
P_corr = np.zeros((p, p), dtype=float)
for i in range(p):
P_corr[i, i] = 1
for j in range(i+1, p):
idx = np.ones(p, dtype=bool)
idx[i] = False
idx[j] = False
beta_i = linalg.lstsq(C[:, idx], C[:, j])[0]
res_j = C[:, j] - C[:, idx].dot( beta_i)
res_i = C[:, i]
corr = stats.pearsonr(res_i, res_j)[0]
P_corr[i, j] = corr
P_corr[j, i] = corr
return P_corr
def mutual_matrix(df,features): # calculate mutual information matrix
mutual = np.zeros([len(features),len(features)])
for i, ifeature in enumerate(features):
for j, jfeature in enumerate(features):
if i != j:
mutual[i,j] = mutual_info_regression(df.iloc[:,i].values.reshape(-1, 1),np.ravel(df.iloc[:,j].values))[0]
mutual /= np.max(mutual)
for i, ifeature in enumerate(features):
mutual[i,i] = 1.0
return mutual
def mutual_information_objective(x,y): # modified from MRMR loss function, Ixy - average(Ixx)
mutual_information_quotient = []
for i, icol in enumerate(x.columns):
Vx = mutual_info_regression(x.iloc[:,i].values.reshape(-1, 1),np.ravel(y.values.reshape(-1, 1)))
Ixx_mat = []
for m, mcol in enumerate(x.columns):
if i != m:
Ixx_mat.append(mutual_info_regression(x.iloc[:,m].values.reshape(-1, 1),np.ravel(x.iloc[:,i].values.reshape(-1, 1))))
Wx = np.average(Ixx_mat)
mutual_information_quotient.append(Vx/Wx)
mutual_information_quotient = np.asarray(mutual_information_quotient).reshape(-1)
return mutual_information_quotient
def delta_mutual_information_quotient(x,y): # standard mutual information quotient
delta_mutual_information_quotient = []
Ixy = []
for m, mcol in enumerate(x.columns):
Ixy.append(mutual_info_regression(x.iloc[:,m].values.reshape(-1, 1),np.ravel(y.values.reshape(-1, 1))))
Vs = np.average(Ixy)
Ixx = []
for m, mcol in enumerate(x.columns):
for n, ncol in enumerate(x.columns):
Ixx.append(mutual_info_regression(x.iloc[:,m].values.reshape(-1, 1),np.ravel(x.iloc[:,n].values.reshape(-1, 1))))
Ws = np.average(Ixx)
for i, icol in enumerate(x.columns):
Ixy_s = []
for m, mcol in enumerate(x.columns):
if m != i:
Ixy_s.append(mutual_info_regression(x.iloc[:,m].values.reshape(-1, 1),np.ravel(y.values.reshape(-1, 1))))
Vs_s = np.average(Ixy_s)
Ixx_s = []
for m, mcol in enumerate(x.columns):
if m != i:
for n, ncol in enumerate(x.columns):
if n != i:
Ixx_s.append(mutual_info_regression(x.iloc[:,m].values.reshape(-1, 1),np.ravel(x.iloc[:,n].values.reshape(-1, 1))))
Ws_s = np.average(Ixx_s)
delta_mutual_information_quotient.append((Vs/Ws)-(Vs_s/Ws_s))
delta_mutual_information_quotient = np.asarray(delta_mutual_information_quotient).reshape(-1)
return delta_mutual_information_quotient
def weighted_avg_and_std(values, weights): # calculate weighted statistics (Eric O Lebigot, stack overflow)
average = np.average(values, weights=weights)
variance = np.average((values-average)**2, weights=weights)
return (average, math.sqrt(variance))
def weighted_percentile(data, weights, perc): # calculate weighted percentile (iambr on StackOverflow @ https://stackoverflow.com/questions/21844024/weighted-percentile-using-numpy/32216049)
ix = np.argsort(data)
data = data[ix]
weights = weights[ix]
cdf = (np.cumsum(weights) - 0.5 * weights) / np.sum(weights)
return np.interp(perc, cdf, data)
def histogram_bounds(values,weights,color): # add uncertainty bounds to a histogram
p10 = weighted_percentile(values,weights,0.1); avg = np.average(values,weights=weights); p90 = weighted_percentile(values,weights,0.9)
plt.plot([p10,p10],[0.0,45],color = color,linestyle='dashed')
plt.plot([avg,avg],[0.0,45],color = color)
plt.plot([p90,p90],[0.0,45],color = color,linestyle='dashed')
def add_grid(): # add major and minor gridlines
plt.gca().grid(True, which='major',linewidth = 1.0); plt.gca().grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
Set the Working Directory#
I always like to do this so I don’t lose files and to simplify subsequent read and writes (avoid including the full address each time).
#os.chdir("d:/PGE383") # set the working directory
You will have to update the part in quotes with your own working directory and the format is different on a Mac (e.g. “~/PGE”).
Loading Tabular Data#
Here’s the command to load our comma delimited data file in to a Pandas’ DataFrame object.
Let’s load the provided multivariate, spatial dataset ‘unconv_MV.csv’. This dataset has variables from 1,000 unconventional wells including:
well average porosity
log transform of permeability (to linearize the relationships with other variables)
acoustic impedance (kg/m^3 x m/s x 10^6)
brittleness ratio (%)
total organic carbon (%)
vitrinite reflectance (%)
initial production 90 day average (MCFPD).
Note, the dataset is synthetic.
We load it with the pandas ‘read_csv’ function into a DataFrame we called ‘my_data’ and then preview it to make sure it loaded correctly.
idata = 0
if idata == 0:
df = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/unconv_MV_v4.csv') # load data from Dr. Pyrcz's GitHub repository
response = 'Prod' # specify the response feature
x = df.copy(deep = True); x = x.drop(['Well',response],axis='columns') # make predictor and response DataFrames
Y = df.loc[:,response]
features = x.columns.values.tolist() + [Y.name] # store the names of the features
pred = x.columns.values.tolist()
resp = Y.name
xmin = [6.0,0.0,1.0,10.0,0.0,0.9]; xmax = [24.0,10.0,5.0,85.0,2.2,2.9] # set the minimum and maximum values for plotting
Ymin = 500.0; Ymax = 9000.0
predlabel = ['Porosity (%)','Permeability (mD)','Acoustic Impedance (kg/m2s*10^6)','Brittleness Ratio (%)', # set the names for plotting
'Total Organic Carbon (%)','Vitrinite Reflectance (%)']
resplabel = 'Normalized Initial Production (MCFPD)'
predtitle = ['Porosity','Permeability','Acoustic Impedance','Brittleness Ratio', # set the units for plotting
'Total Organic Carbon','Vitrinite Reflectance']
resptitle = 'Normalized Initial Production'
featurelabel = predlabel + [resplabel] # make feature labels and titles for concise code
featuretitle = predtitle + [resptitle]
m = len(pred) + 1
mpred = len(pred)
# elif idata == 1:
# names = {'Porosity':'Por'}
# df = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/12_sample_data.csv') # load data from Dr. Pyrcz's GitHub repository
# df = df.rename(columns=names)
# df['Por'] = df['Por'] * 100.0; df['AI'] = df['AI'] / 1000.0;
# df.drop('Unnamed: 0',axis=1,inplace=True)
# features = df.columns.values.tolist() # store the names of the features
# xmin = [0.0,0.0,0.0,4.0,0.0,6.5,1.4,1600.0,10.0,1300.0,1.6]; xmax = [10000.0,10000.0,1.0,19.0,500.0,8.3,3.6,6200.0,50.0,2000.0,12.0] # set the minimum and maximum values for plotting
# flabel = ['Well (ID)','X (m)','Y (m)','Depth (m)','Porosity (fraction)','Permeability (mD)','Acoustic Impedance (kg/m2s*10^6)','Facies (categorical)',
# 'Density (g/cm^3)','Compressible velocity (m/s)','Youngs modulus (GPa)', 'Shear velocity (m/s)', 'Shear modulus (GPa)'] # set the names for plotting
# ftitle = ['Well','X','Y','Depth','Porosity','Permeability','Acoustic Impedance','Facies',
# 'Density','Compressible velocity','Youngs modulus', 'Shear velocity', 'Shear modulus']
elif idata == 2:
df = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/res21_2D_wells.csv') # load data from Dr. Pyrcz's GitHub repository
response = 'CumulativeOil' # specify the response feature
x = df.copy(deep = True); x = x.drop(['Well_ID','X','Y',response],axis='columns') # make predictor and response DataFrames
Y = df.loc[:,response]
features = x.columns.values.tolist() + [Y.name] # store the names of the features
pred = x.columns.values.tolist()
resp = Y.name
xmin = [1.0,0.0,0.0,4.0,0.0,6.5,1.4,1600.0,10.0,1300.0,1.6]; xmax = [75.0,10000.0,10000.0,19.0,500.0,8.3,3.6,6200.0,50.0,2000.0,12.0] # set the minimum and maximum values for plotting
Ymin = 0.0; Ymax = 3000.0
predlabel = ['Well (ID)','X (m)','Y (m)','Porosity (fraction)','Permeability (mD)','Acoustic Impedance (kg/m2s*10^6)',
'Density (g/cm^3)','Compressible velocity (m/s)','Youngs modulus (GPa)', 'Shear velocity (m/s)', 'Shear modulus (GPa)']
resplabel = 'Cumulative Production (MSTB)'
predtitle = ['Well','X','Y','Porosity','Permeability','Acoustic Impedance',
'Density (g/cm^3)','Compressible velocity','Youngs modulus', 'Shear velocity', 'Shear modulus']
resptitle = 'Cumulative Production'
featurelabel = predlabel + [resplabel] # make feature labels and titles for concise code
featuretitle = predtitle + [resptitle]
m = len(pred) + 1
mpred = len(pred)
---------------------------------------------------------------------------
SSLCertVerificationError Traceback (most recent call last)
File ~\AppData\Local\anaconda3\envs\book\lib\urllib\request.py:1317, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1316 try:
-> 1317 h.request(req.get_method(), req.selector, req.data, headers,
1318 encode_chunked=req.has_header('Transfer-encoding'))
1319 except OSError as err: # timeout error
File ~\AppData\Local\anaconda3\envs\book\lib\http\client.py:1230, in HTTPConnection.request(self, method, url, body, headers, encode_chunked)
1229 """Send a complete request to the server."""
-> 1230 self._send_request(method, url, body, headers, encode_chunked)
File ~\AppData\Local\anaconda3\envs\book\lib\http\client.py:1276, in HTTPConnection._send_request(self, method, url, body, headers, encode_chunked)
1275 body = _encode(body, 'body')
-> 1276 self.endheaders(body, encode_chunked=encode_chunked)
File ~\AppData\Local\anaconda3\envs\book\lib\http\client.py:1225, in HTTPConnection.endheaders(self, message_body, encode_chunked)
1224 raise CannotSendHeader()
-> 1225 self._send_output(message_body, encode_chunked=encode_chunked)
File ~\AppData\Local\anaconda3\envs\book\lib\http\client.py:1004, in HTTPConnection._send_output(self, message_body, encode_chunked)
1003 del self._buffer[:]
-> 1004 self.send(msg)
1006 if message_body is not None:
1007
1008 # create a consistent interface to message_body
File ~\AppData\Local\anaconda3\envs\book\lib\http\client.py:944, in HTTPConnection.send(self, data)
943 if self.auto_open:
--> 944 self.connect()
945 else:
File ~\AppData\Local\anaconda3\envs\book\lib\http\client.py:1399, in HTTPSConnection.connect(self)
1397 server_hostname = self.host
-> 1399 self.sock = self._context.wrap_socket(self.sock,
1400 server_hostname=server_hostname)
File ~\AppData\Local\anaconda3\envs\book\lib\ssl.py:500, in SSLContext.wrap_socket(self, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, session)
494 def wrap_socket(self, sock, server_side=False,
495 do_handshake_on_connect=True,
496 suppress_ragged_eofs=True,
497 server_hostname=None, session=None):
498 # SSLSocket class handles server_hostname encoding before it calls
499 # ctx._wrap_socket()
--> 500 return self.sslsocket_class._create(
501 sock=sock,
502 server_side=server_side,
503 do_handshake_on_connect=do_handshake_on_connect,
504 suppress_ragged_eofs=suppress_ragged_eofs,
505 server_hostname=server_hostname,
506 context=self,
507 session=session
508 )
File ~\AppData\Local\anaconda3\envs\book\lib\ssl.py:1040, in SSLSocket._create(cls, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, context, session)
1039 raise ValueError("do_handshake_on_connect should not be specified for non-blocking sockets")
-> 1040 self.do_handshake()
1041 except (OSError, ValueError):
File ~\AppData\Local\anaconda3\envs\book\lib\ssl.py:1309, in SSLSocket.do_handshake(self, block)
1308 self.settimeout(None)
-> 1309 self._sslobj.do_handshake()
1310 finally:
SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1108)
During handling of the above exception, another exception occurred:
URLError Traceback (most recent call last)
Cell In[7], line 3
1 idata = 0
2 if idata == 0:
----> 3 df = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/unconv_MV_v4.csv') # load data from Dr. Pyrcz's GitHub repository
5 response = 'Prod' # specify the response feature
6 x = df.copy(deep = True); x = x.drop(['Well',response],axis='columns') # make predictor and response DataFrames
File ~\AppData\Local\anaconda3\envs\book\lib\site-packages\pandas\io\parsers\readers.py:912, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend)
899 kwds_defaults = _refine_defaults_read(
900 dialect,
901 delimiter,
(...)
908 dtype_backend=dtype_backend,
909 )
910 kwds.update(kwds_defaults)
--> 912 return _read(filepath_or_buffer, kwds)
File ~\AppData\Local\anaconda3\envs\book\lib\site-packages\pandas\io\parsers\readers.py:577, in _read(filepath_or_buffer, kwds)
574 _validate_names(kwds.get("names", None))
576 # Create the parser.
--> 577 parser = TextFileReader(filepath_or_buffer, **kwds)
579 if chunksize or iterator:
580 return parser
File ~\AppData\Local\anaconda3\envs\book\lib\site-packages\pandas\io\parsers\readers.py:1407, in TextFileReader.__init__(self, f, engine, **kwds)
1404 self.options["has_index_names"] = kwds["has_index_names"]
1406 self.handles: IOHandles | None = None
-> 1407 self._engine = self._make_engine(f, self.engine)
File ~\AppData\Local\anaconda3\envs\book\lib\site-packages\pandas\io\parsers\readers.py:1661, in TextFileReader._make_engine(self, f, engine)
1659 if "b" not in mode:
1660 mode += "b"
-> 1661 self.handles = get_handle(
1662 f,
1663 mode,
1664 encoding=self.options.get("encoding", None),
1665 compression=self.options.get("compression", None),
1666 memory_map=self.options.get("memory_map", False),
1667 is_text=is_text,
1668 errors=self.options.get("encoding_errors", "strict"),
1669 storage_options=self.options.get("storage_options", None),
1670 )
1671 assert self.handles is not None
1672 f = self.handles.handle
File ~\AppData\Local\anaconda3\envs\book\lib\site-packages\pandas\io\common.py:716, in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
713 codecs.lookup_error(errors)
715 # open URLs
--> 716 ioargs = _get_filepath_or_buffer(
717 path_or_buf,
718 encoding=encoding,
719 compression=compression,
720 mode=mode,
721 storage_options=storage_options,
722 )
724 handle = ioargs.filepath_or_buffer
725 handles: list[BaseBuffer]
File ~\AppData\Local\anaconda3\envs\book\lib\site-packages\pandas\io\common.py:368, in _get_filepath_or_buffer(filepath_or_buffer, encoding, compression, mode, storage_options)
366 # assuming storage_options is to be interpreted as headers
367 req_info = urllib.request.Request(filepath_or_buffer, headers=storage_options)
--> 368 with urlopen(req_info) as req:
369 content_encoding = req.headers.get("Content-Encoding", None)
370 if content_encoding == "gzip":
371 # Override compression based on Content-Encoding header
File ~\AppData\Local\anaconda3\envs\book\lib\site-packages\pandas\io\common.py:270, in urlopen(*args, **kwargs)
264 """
265 Lazy-import wrapper for stdlib urlopen, as that imports a big chunk of
266 the stdlib.
267 """
268 import urllib.request
--> 270 return urllib.request.urlopen(*args, **kwargs)
File ~\AppData\Local\anaconda3\envs\book\lib\urllib\request.py:222, in urlopen(url, data, timeout, cafile, capath, cadefault, context)
220 else:
221 opener = _opener
--> 222 return opener.open(url, data, timeout)
File ~\AppData\Local\anaconda3\envs\book\lib\urllib\request.py:525, in OpenerDirector.open(self, fullurl, data, timeout)
522 req = meth(req)
524 sys.audit('urllib.Request', req.full_url, req.data, req.headers, req.get_method())
--> 525 response = self._open(req, data)
527 # post-process response
528 meth_name = protocol+"_response"
File ~\AppData\Local\anaconda3\envs\book\lib\urllib\request.py:542, in OpenerDirector._open(self, req, data)
539 return result
541 protocol = req.type
--> 542 result = self._call_chain(self.handle_open, protocol, protocol +
543 '_open', req)
544 if result:
545 return result
File ~\AppData\Local\anaconda3\envs\book\lib\urllib\request.py:502, in OpenerDirector._call_chain(self, chain, kind, meth_name, *args)
500 for handler in handlers:
501 func = getattr(handler, meth_name)
--> 502 result = func(*args)
503 if result is not None:
504 return result
File ~\AppData\Local\anaconda3\envs\book\lib\urllib\request.py:1360, in HTTPSHandler.https_open(self, req)
1359 def https_open(self, req):
-> 1360 return self.do_open(http.client.HTTPSConnection, req,
1361 context=self._context, check_hostname=self._check_hostname)
File ~\AppData\Local\anaconda3\envs\book\lib\urllib\request.py:1320, in AbstractHTTPHandler.do_open(self, http_class, req, **http_conn_args)
1317 h.request(req.get_method(), req.selector, req.data, headers,
1318 encode_chunked=req.has_header('Transfer-encoding'))
1319 except OSError as err: # timeout error
-> 1320 raise URLError(err)
1321 r = h.getresponse()
1322 except:
URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1108)>
We can also establish the feature ranges for plotting. We could calculate the feature range directly from the data with code like this:
Pormin = np.min(df['Por'].values) # extract ndarray of data table column
Pormax = np.max(df['Por'].values) # and calculate min and max
but, this would not result in easy to understand color bars and axis scales, let’s pick convenient round numbers. We will also declare feature labels for ease of plotting.
Visualize the DataFrame#
Visualizing the DataFrame is useful first check of the data.
many things can go wrong, e.g., we loaded the wrong data, all the features did not load, etc.
We can preview by utilizing the ‘head’ DataFrame member function (with a nice and clean format, see below).
add parameter ‘n=13’ to see the first 13 rows of the dataset.
df.head(n=13) # we could also use this command for a table preview
| Well | Por | Perm | AI | Brittle | TOC | VR | Prod | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 12.08 | 2.92 | 2.80 | 81.40 | 1.16 | 2.31 | 1695.360819 |
| 1 | 2 | 12.38 | 3.53 | 3.22 | 46.17 | 0.89 | 1.88 | 3007.096063 |
| 2 | 3 | 14.02 | 2.59 | 4.01 | 72.80 | 0.89 | 2.72 | 2531.938259 |
| 3 | 4 | 17.67 | 6.75 | 2.63 | 39.81 | 1.08 | 1.88 | 5288.514854 |
| 4 | 5 | 17.52 | 4.57 | 3.18 | 10.94 | 1.51 | 1.90 | 2859.469624 |
| 5 | 6 | 14.53 | 4.81 | 2.69 | 53.60 | 0.94 | 1.67 | 4017.374438 |
| 6 | 7 | 13.49 | 3.60 | 2.93 | 63.71 | 0.80 | 1.85 | 2952.812773 |
| 7 | 8 | 11.58 | 3.03 | 3.25 | 53.00 | 0.69 | 1.93 | 2670.933846 |
| 8 | 9 | 12.52 | 2.72 | 2.43 | 65.77 | 0.95 | 1.98 | 2474.048178 |
| 9 | 10 | 13.25 | 3.94 | 3.71 | 66.20 | 1.14 | 2.65 | 2722.893266 |
| 10 | 11 | 15.04 | 4.39 | 2.22 | 61.11 | 1.08 | 1.77 | 3828.247174 |
| 11 | 12 | 16.19 | 6.30 | 2.29 | 49.10 | 1.53 | 1.86 | 5095.810104 |
| 12 | 13 | 16.82 | 5.42 | 2.80 | 66.65 | 1.17 | 1.98 | 4091.637316 |
Summary Statistics for Tabular Data#
There are a lot of efficient methods to calculate summary statistics from tabular data in DataFrames. The describe command provides count, mean, minimum, maximum, and quartiles all in a nice data table.
We use transpose just to flip the table so that features are on the rows and the statistics are on the columns.
df.describe().transpose() # calculate summary statistics for the data
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Well | 200.0 | 100.500000 | 57.879185 | 1.000000 | 50.750000 | 100.500000 | 150.250000 | 200.000000 |
| Por | 200.0 | 14.991150 | 2.971176 | 6.550000 | 12.912500 | 15.070000 | 17.402500 | 23.550000 |
| Perm | 200.0 | 4.330750 | 1.731014 | 1.130000 | 3.122500 | 4.035000 | 5.287500 | 9.870000 |
| AI | 200.0 | 2.968850 | 0.566885 | 1.280000 | 2.547500 | 2.955000 | 3.345000 | 4.630000 |
| Brittle | 200.0 | 48.161950 | 14.129455 | 10.940000 | 37.755000 | 49.510000 | 58.262500 | 84.330000 |
| TOC | 200.0 | 0.990450 | 0.481588 | -0.190000 | 0.617500 | 1.030000 | 1.350000 | 2.180000 |
| VR | 200.0 | 1.964300 | 0.300827 | 0.930000 | 1.770000 | 1.960000 | 2.142500 | 2.870000 |
| Prod | 200.0 | 3864.407081 | 1553.277558 | 839.822063 | 2686.227611 | 3604.303506 | 4752.637555 | 8590.384044 |
Ranking features is really an effort to understand the features and their relationships with each other. We will start with basic data visualization and move to more complicated methods such are partial correlation and recursive feature elimination.
Coverage#
Let’s start with the concept of feature coverage.
If a feature is available over a small proportion of the samples then we may not want to include it as it will result in issues with feature imputation, estimation of missing data.
By removing a couple features with poor coverage we may improve our model because there are limitations with feature imputation, feature imputation can actually impose bias in statistics and additional error in our prediction models
if likewise deletion is applied to deal with missing values, features with low coverage result in a lot of removed data!
Let’s start with a bar chart with the proportion of missing records:
plt.subplot(111)
(df.isnull().sum()/len(df)).plot(kind = 'bar') # calculate DataFrame with percentage missing by feature
plt.xlabel('Feature'); plt.ylabel('Percentage of Missing Values'); plt.title('Data Completeness'); plt.ylim([0.0,1.0])
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=0.8, wspace=0.2, hspace=0.2); add_grid(); plt.show()

For the provided example dataset the plot should be empty. There are no missing data so the ‘Proportion of Missing Records’ is 0.0 for all features.
If you wanted to test this plot with some missing data, run this code first:
proportion_NaN = 0.1 # proportion of values in DataFrame to remove
remove = np.random.random(df.shape) < proportion_NaN # make the boolean array for removal
print('Fraction of removed values in mask ndarray = ' + str(round(remove.sum()/remove.size,3)) + '.')
df_mask = df.mask(remove) # make a new DataFrame with specified proportion removed
Remove this code and reload the data to continue to get consistent results with the discussions below.
This does not tell the whole story. For example, if 20% of feature A is missing and 20% of feature B is missing are those the same and different samples. This has a huge impact if you perform likewise deletion.
If there is not too much data then we can actually visualize data coverage over all samples and features in a boolean table like this.
This method may identify specific samples with many missing features that may be removed to improve overall coverage or other trends or structures in the missing data that may result in sampling bias.
df_temp = df.copy(deep=True) # make a deep copy of the DataFrame
df_bool = df_temp.isnull() # true is value, false if NaN
#df_bool = df_bool.set_index(df_temp.pop('UWI')) # set the index / feature for the heat map y column
heat = sns.heatmap(df_bool, cmap=['r','w'], annot=False, fmt='.0f',cbar=False,linecolor='black',linewidth=0.1) # make the binary heat map, no bins
heat.set_xticklabels(heat.get_xticklabels(), rotation=90, fontsize=8)
heat.set_yticklabels(heat.get_yticklabels(), rotation=0, fontsize=8)
heat.set_title('Data Completeness Heatmap',fontsize=16); heat.set_xlabel('Feature',fontsize=12); heat.set_ylabel('Sample (Index)',fontsize=12)
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.8, top=1.6, wspace=0.2, hspace=0.2); plt.show()
Once again this plot should be quite boring for the provided dataset with perfect coverage, every cell should be filled in red.
add the code to remove some records to test this plot. White cells are missing records.
Feature Imputation#
See the chapter on feature imputation to learn what to do about missing data.
For now a concise treatment here, we will just apply likewise deletion and move on.
we remove all samples with any missing feature values. While this is quite simple, it is a sledge hammer approach to ensure perfect coverage required by feature ranking methods that we are about to demonstrate. Please check out the other methods in the linked workflow above.
df.dropna(axis=0,how='any',inplace=True) # likewise deletion
Summary Statistics#
In any multivariate work we should start with the univariate analysis, summary statistics of one variable at a time. The summary statistic ranking method is qualitative, we are asking:
Are there data issues?
Do we trust the features? Do we trust the features all equally?
Are there issues that need to be taken care of before we develop any multivariate workflows?
There are a lot of efficient methods to calculate summary statistics from tabular data in DataFrames. The describe command provides count, mean, minimum, maximum, and quartiles all in a compact data table. We use transpose() command to flip the table so that features are on the rows and the statistics are on the columns.
df.describe().transpose() # DataFrame summary statistics
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Well | 200.0 | 100.500000 | 57.879185 | 1.000000 | 50.750000 | 100.500000 | 150.250000 | 200.000000 |
| Por | 200.0 | 14.991150 | 2.971176 | 6.550000 | 12.912500 | 15.070000 | 17.402500 | 23.550000 |
| Perm | 200.0 | 4.330750 | 1.731014 | 1.130000 | 3.122500 | 4.035000 | 5.287500 | 9.870000 |
| AI | 200.0 | 2.968850 | 0.566885 | 1.280000 | 2.547500 | 2.955000 | 3.345000 | 4.630000 |
| Brittle | 200.0 | 48.161950 | 14.129455 | 10.940000 | 37.755000 | 49.510000 | 58.262500 | 84.330000 |
| TOC | 200.0 | 0.990450 | 0.481588 | -0.190000 | 0.617500 | 1.030000 | 1.350000 | 2.180000 |
| VR | 200.0 | 1.964300 | 0.300827 | 0.930000 | 1.770000 | 1.960000 | 2.142500 | 2.870000 |
| Prod | 200.0 | 3864.407081 | 1553.277558 | 839.822063 | 2686.227611 | 3604.303506 | 4752.637555 | 8590.384044 |
Summary statistics are a critical first step in data checking.
this includes the number of valid (non-null) values for each feature (count removes all np.NaN from the totals for each variable).
we can see the general behaviors such as central tendency, mean, and dispersion, variance.
we can identify issue with negative values, extreme values, and values that are outside the range of plausible values for each property.
The data looks to be in pretty good shape and for brevity we skip outlier detection. Let’s look at the univariate distributions.
Univariate Distributions#
As with summary statistics, this ranking method is a qualitative check for issues with the data and to assess our confidence with each feature. It is better to not include a feature with low confidence of quality as it may be misleading (while adding to model complexity as discussed previously).
nbins = 20 # number of histogram bins
for i, feature in enumerate(features): # plot histograms with central tendency and P10 and P90 labeled
plt.subplot(4,3,i+1)
y,_,_ = plt.hist(x=df[feature],weights=None,bins=nbins,alpha = 0.8,edgecolor='black',color='darkorange',density=True)
# histogram_bounds(values=df[feature].values,weights=np.ones(len(df)),color='red')
plt.xlabel(feature); plt.ylabel('Frequency'); plt.ylim([0.0,y.max()*1.10]); plt.title(featuretitle[i]); add_grid()
# if feature == resp:
# plt.xlim([Ymin,Ymax])
# else:
# plt.xlim([xmin[i],xmax[i]])
plt.subplots_adjust(left=0.0, bottom=0.0, right=3., top=4.1, wspace=0.2, hspace=0.3); plt.show()
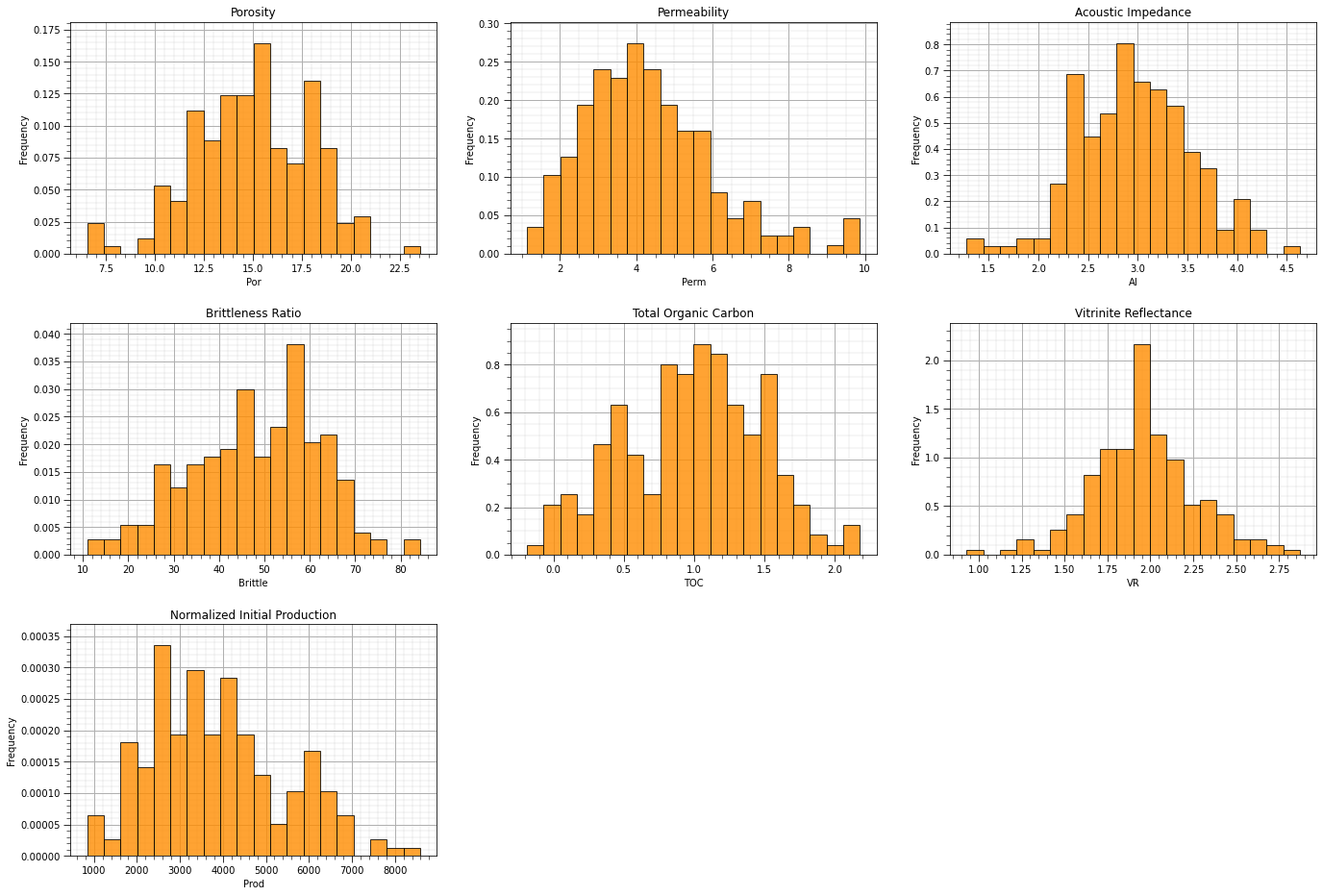
The univariate distributions look good:
there are no obvious outliers
the permeability is positively skewed, as is often observed
the corrected TOC has a small spike, but it’s reasonable
Bivariate Distributions#
Matrix scatter plots are a very efficient method to observe the bivariate relationships between the variables.
this is another opportunity through data visualization to identify data issues
we can assess if we have collinearity, specifically simpler form between two features at a time.
pairgrid = sns.PairGrid(df) # matrix scatter plots
pairgrid = pairgrid.map_upper(plt.scatter, color = 'darkorange', edgecolor = 'black', alpha = 0.8, s = 10)
pairgrid = pairgrid.map_diag(plt.hist, bins = 20, color = 'darkorange',alpha = 0.8, edgecolor = 'k')# Map a density plot to the lower triangle
pairgrid = pairgrid.map_lower(sns.kdeplot, cmap = plt.cm.inferno,
shade = False, shade_lowest = False, alpha = 1.0, n_levels = 10)
pairgrid.add_legend()
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.9, top=0.9, wspace=0.2, hspace=0.2); plt.show()

This plot communicates a lot of information. How could we use this plot for variable ranking?
we can identify features that are closely related to each other, e.g., if two features have almost a perfect monotonic linear or near linear relationship we should remove one immediately. This is a simple case of collinearity that will likely result in model instability as discussed above.
we can check for linear vs. non-linear relationships. If we observe nonlinear bivariate relationships this will impact the choice of methods, and the quality of results from methods that assume linear relationships for variable ranking.
we can identify constraint relationships and heteroscedasticity between variables. Once again these may restrict our ranking methods and also encourage us to retains specific features to retain these features in the resulting model.
Yet, we must remember that bivariate visualization and analysis is not sufficient to understand all the multivariate relationships in the data, e.g., multicollinearity includes strong linear relationships between 2 or more features. These may be hard to see with only bivariate plots.
Pairwise Covariance#
Pairwise covariance provides a measure of the strength of the linear relationship between each predictor feature and the response feature. At this point, we specify that the goal of this study is to predict production, our response variable, from the other available predictor features. We are thinking predictively now, not inferentially, we want to estimate the function, \(\hat{f}\), to accomplish this:
where \(Y\) is our response feature and \(X_1,\ldots,X_n\) are our predictor features. If we retained all of our predictor features to predict the response we would have:
Now back to the covariance, the covariance is defined as:
Covariance:
measures the linear relationship
sensitive to the dispersion / variance of both the predictor and response
We can use the follow command to build a covariance matrix:
df.iloc[:,1:8].cov() # covariance matrix sliced predictors vs. response
the output is a new Pandas DataFrame, so we can slice the last column to get a Pandas series (ndarray with names) with the covariances between all predictors features and the response.
covariance = df.iloc[:,df.columns.get_indexer(features)].cov().iloc[len(features)-1,:len(features)] # calculate covariance matrix and slice for only pred - resp
cov_matrix = df.iloc[:,df.columns.get_indexer(features)].cov()
plt.subplot(121)
plot_corr(cov_matrix,'Covariance Matrix',4000.0,0.1) # using our correlation matrix visualization function
plt.xlabel('Features'); plt.ylabel('Features')
plt.subplot(122)
feature_rank_plot(features,covariance,-20000.0,20000.0,0.0,'Feature Ranking, Covariance with ' + resp,'Covariance',0.1)
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.6, top=0.8, wspace=0.2, hspace=0.3); plt.show()
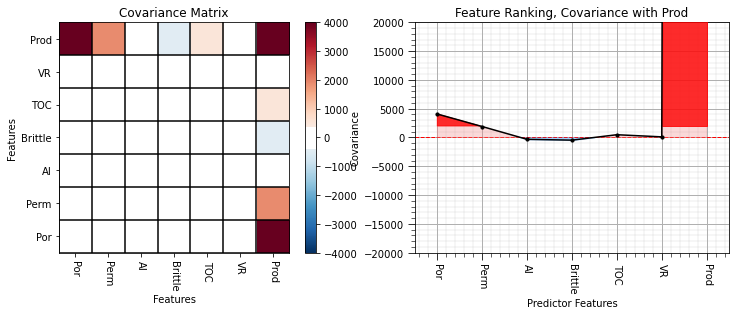
The covariance is useful, but as you can see the magnitude is quite variable.
the covarince magnitudes are a function of each feature’s feature and feature variance is somewhat arbitrary.
for example, what is the variance of porosity in fraction vs. percentage or permeability in Darcy vs. milliDarcy. We can show that if we apply a constant multiplier, \(c\), to a feature, \(X\), that the variance will change according to this relationship (the proof is based on expectation formulation of variance):
By moving from percentage to fraction we decrease the variance of porosity by a factor of 10,000! The variance of each feature is potentially arbitrary, with the exception when all the features are in the same units.
Pairwise correlations are standardized covariances; therefore, avoids this arbitrary magnitude issue.
Pairwise Correlation Coefficient#
Pairwise correlation coefficient provides a measure of the strength of the linear relationship between each predictor feature and the response feature.
The correlation coefficient:
measures the linear relationship
removes the sensitivity to the dispersion / variance of both the predictor and response features, by normalizing by the product of the standard deviation of each feature
We can use the follow command to build a correlation matrix:
df.iloc[:,1:8].corr()
the output is a new Pandas DataFrame, so we can slice the last column to get a Pandas series (ndarray with names) with the correlations between all predictors features and the response.
correlation = df.iloc[:,df.columns.get_indexer(features)].corr().iloc[len(features)-1,:len(features)] # calculate covariance matrix and slice for only pred - resp
corr_matrix = df.iloc[:,df.columns.get_indexer(features)].corr()
plt.subplot(121)
plot_corr(corr_matrix,'Correlation Matrix',1.0,0.5) # using our correlation matrix visualization function
plt.xlabel('Features'); plt.ylabel('Features')
plt.subplot(122)
feature_rank_plot(features,correlation,-1.0,1.0,0.0,'Feature Ranking, Correlation with ' + resp,'Correlation',0.5)
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=0.8, wspace=0.2, hspace=0.3); plt.show()
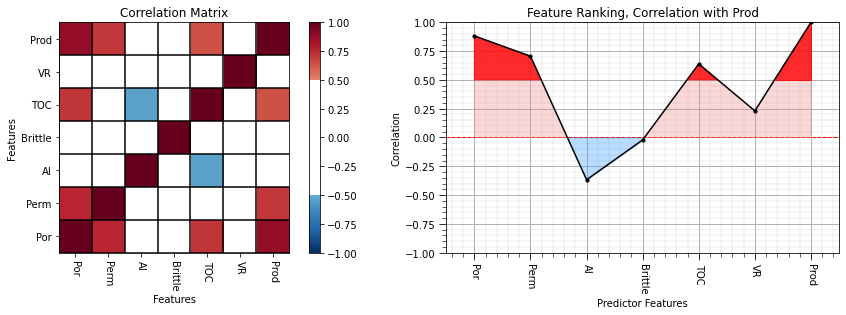
From the correlation matrix we can observe:
We see that porosity, permeability and total organic carbon have the strongest linear relationships with production.
Acoustic impedance has weak negative relationships with production.
Brittleness is very close to 0.0. If you review the brittleness vs. production scatterplot, you’ll observe a complicated non-linear relationship. There is a brittleness ratio sweet spot for production (rock that is not too soft nor too hard)!
We could also look at the full correlation matrix to evaluate the potential for redundancy between predictor features.
strong degree of correlation between porosity and permeability and porosity and TOC
strong degree of negative correlation between TOC and acoustic impedance
We are still limited to a strict linear relationship. The rank correlation allows us to relax this assumption.
Pairwise Spearman Rank Correlation Coefficient#
The rank correlation coefficient applies the rank transform to the data prior to calculating the correlation coefficient. To calculate the rank transform simply replace the data values with the rank \(R_x = 1,\dots,n\), where \(n\) is the maximum value and \(1\) is the minimum value.
The rank correlation:
measures the monotonic relationship, relaxes the linear assumption
removes the sensitivity to the dispersion / variance of both the predictor and response, by normalizing by the product of the standard deviation of each.
We can use the follow command to build a rank correlation matrix and calculate the p-value:
stats.spearmanr(df.iloc[:,1:8])
the output is a new Pandas DataFrame, so we can slice the last column to get a Pandas series (ndarray with names) with the correlations between all predictors features and the response.
Also, we get a very convenient pval 2D ndarray with the two-sided (two-tail summing symmetric over both tails) p-value for a hypothesis test with:
Let’s keep the p-values between all the predictor features and our response feature.
rank_correlation, rank_correlation_pval = stats.spearmanr(df.iloc[:,df.columns.get_indexer(features)]) # calculate the rank correlation coefficient
rank_matrix = pd.DataFrame(rank_correlation,columns=corr_matrix.columns)
rank_correlation = rank_correlation[:,len(features)-1][:len(features)]
rank_correlation_pval = rank_correlation_pval[:,len(pred)-1][:len(features)]
print("\nRank Correlation p-value:\n"); print(rank_correlation_pval)
plt.subplot(121)
plot_corr(rank_matrix,'Rank Correlation Matrix',1.0,0.5) # using our correlation matrix visualization function
plt.xlabel('Features'); plt.ylabel('Features')
plt.subplot(122)
feature_rank_plot(features,rank_correlation,-1.0,1.0,0.0,'Feature Ranking, Rank Correlation with ' + resp,'Rank Correlation',0.5)
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=0.8, wspace=0.2, hspace=0.3); plt.show()
Rank Correlation p-value:
[2.43279911e-02 1.34135205e-01 1.18844068e-10 2.71646948e-04
2.11367755e-06 0.00000000e+00 3.29170847e-04]
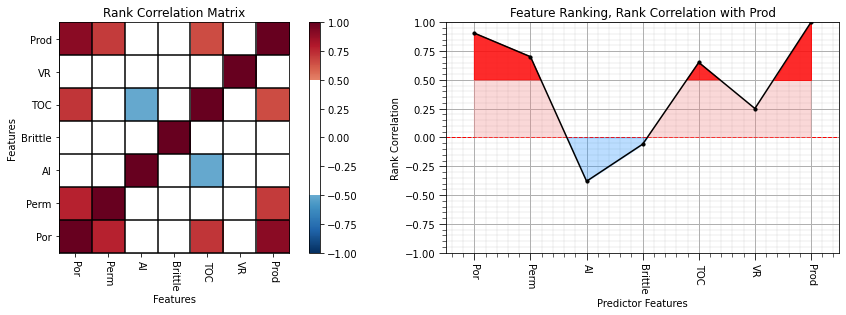
There matrix and line plots indicate that the rank correlation coefficients are similar to the correlation coefficients indicating that nonlinearity and outliers are not likely impacting the correlation-based feature ranking.
With regard to rank correlation p-values,
at a typical alpha value of 0.05, only the rank correlation between brittleness and production does not fail the hypothesis test; therefore, is not significantly different than 0.0.
It is useful to look at the difference between the correlation coefficient and rank correlation coefficient.
plt.subplot(121) # plot correlation matrix with significance colormap
diff = corr_matrix.values - rank_matrix.values
diff_matrix = pd.DataFrame(diff,columns=corr_matrix.columns)
plot_corr(diff_matrix,'Correlation - Rank Correlation',0.1,0.1) # using our correlation matrix visualization function
plt.xlabel('Features'); plt.ylabel('Features')
corr_diff = correlation - rank_correlation
plt.subplot(122)
feature_rank_plot(features,corr_diff,-0.20,0.20,0.0,'Correlation Coefficient - Rank Correlation Coefficient','Correlation Diffference',0.1)
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=0.8, wspace=0.2, hspace=0.3); plt.show()
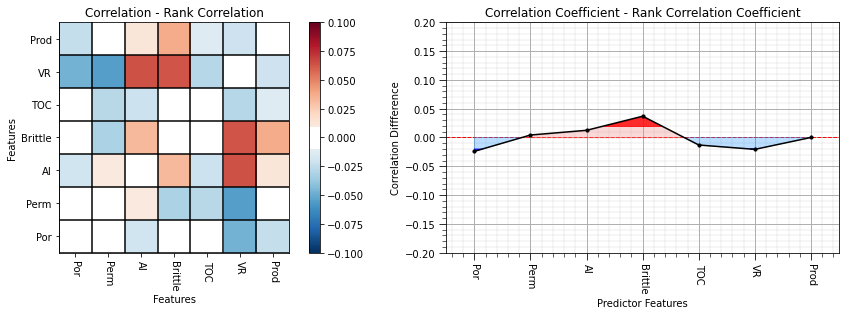
Here are some interesting observations:
correlation of porosity and vitrinite reflectance with production improve when we reduce the impact of linearity and outliers
correlation of brittleness with production worsen when we reduce the impact of linearity and outliers
All of these methods up to now have considered one feature at a time. We can also consider methods that consider all features jointly to ‘isolate’ the influence of each feature.
Partial Correlation Coefficient#
This is a linear correlation coefficient that controls for the effects all the remaining variables, \(\rho_{XY.Z}\) and \(\rho_{YX.Z}\) is the partial correlation between \(X\) and \(Y\), \(Y\) and \(X\), after controlling for \(Z\).
To calculate the partial correlation coefficient between \(X\) and \(Y\) given \(Z_i, \forall \quad i = 1,\ldots, m-1\) remaining features we use the following steps:
perform linear, least-squares regression to predict \(X\) from \(Z_i, \forall \quad i = 1,\ldots, m-1\). \(X\) is regressed on the predictors to calculate the estimate, \(X^*\)
calculate the residuals in Step #1, \(X-X^*\), where \(X^* = f(Z_{1,\ldots,m-1})\), linear regression model
perform linear, least-squares regression to predict \(Y\) from \(Z_i, \forall \quad i = 1,\ldots, m-1\). \(Y\) is regressed on the predictors to calculate the estimate, \(Y^*\)
calculate the residuals in Step #3, \(Y-Y^*\), where \(Y^* = f(Z_{1,\ldots,m-1})\), linear regression model
calculate the correlation coefficient between the residuals from Steps #2 and #4, \(\rho_{X-X^*,Y-Y^*}\)
The partial correlation, provides a measure of the linear relationship between \(X\) and \(Y\) while controlling for the effect of \(Z\) other features on both, \(X\) and \(Y\). We use the function declared previously taken from Fabian Pedregosa-Izquierdo, f@bianp.net. The original code is on GitHub at https://git.io/fhyHB.
To use this method we must assume:
two variables to compare, \(X\) and \(Y\)
other variables to control, \(Z_{1,\ldots,m-2}\)
linear relationships between all variables
no significant outliers
approximately bivariate normality between the variables
We are in pretty good shape, but we have some departures from bivariate normality. We could consider Gaussian univariate transforms to improve this. This option is provided later.
partial_correlation = partial_corr(df.iloc[:,df.columns.get_indexer(features)]) # calculate the partial correlation coefficients
partial_matrix = pd.DataFrame(partial_correlation,columns=corr_matrix.columns)
partial_correlation = partial_correlation[:,len(features)-1][:len(features)] # extract a single row and remove production with itself
plt.subplot(121)
plot_corr(partial_matrix,'Partial Correlation Matrix',1.0,0.5) # using our correlation matrix visualization function
plt.xlabel('Features'); plt.ylabel('Features')
plt.subplot(122)
feature_rank_plot(features,partial_correlation,-1.0,1.0,0.0,'Feature Ranking, Partial Correlation with ' + resp,'Partial Correlation',0.5)
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=0.8, wspace=0.2, hspace=0.3); plt.show()
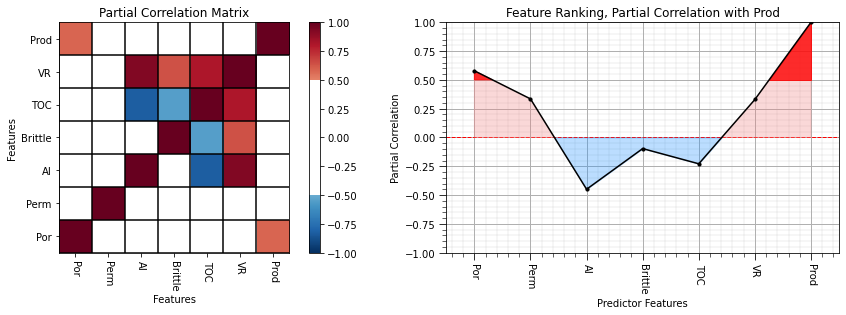
Now we see a lot of new things about the unique contributions of each predictor feature!
porosity and permeability are strongly correlated with each other so they are penalized severely
acoustic impedance’s and vitrinite reflectance’s absolute correlation are increased reflecting their unique contributions
total organic carbon flipped signs! When we control for all other variables, it has a negative relationship with production.
With the partial correlation coefficients we have controlled for the influence of all other predictor features on both the specific predictor and the response features. The semipartial correlation filters out the influence of all other predictor features on the raw response variable.
Semipartial Correlation Coefficient#
This is a linear correlation coefficient that controls for the effects all the remaining features, \(Z\) on \(X\), and then calculates the correlation between the residual \(X^*-X\) and \(Y\). Note: we do not control for influence of \(Z\) features on the response feature, \(Y\).
To calculate the semipartial correlation coefficient between \(X\) and \(Y\) given \(Z_i, \forall \quad i = 1,\ldots, m-1\) remaining features we use the following steps:
perform linear, least-squares regression to predict \(X\) from \(Z_i, \forall \quad i = 1,\ldots, m-1\). \(X\) is regressed on the remaining predictor features to calculate the estimate, \(X^*\)
calculate the residuals in Step #1, \(X-X^*\), where \(X^* = f(Z_{1,\ldots,m-1})\), linear regression model
calculate the correlation coefficient between the residuals from Steps #2 and \(Y\) response feature, \(\rho_{X-X^*,Y}\)
The semipartial correlation coefficient, provides a measure of the linear relationship between \(X\) and \(Y\) while controlling for the effect of \(Z\) other predictor features on the predictor feature, \(X\), to get the unique contribution of \(X\) with respect to \(Y\). We use a modified version of the partial correlation function that we declared previously. The original code is on GitHub at https://git.io/fhyHB.
semipartial_correlation = semipartial_corr(df.iloc[:,df.columns.get_indexer(features)]) # calculate the semi-partial correlation coefficients
semipartial_matrix = pd.DataFrame(semipartial_correlation,columns=corr_matrix.columns)
semipartial_correlation = semipartial_correlation[:,len(features)-1][:len(features)] # extract a single row and remove production with itself
plt.subplot(121)
plot_corr(semipartial_matrix,'Semi-partial Correlation Matrix',1.0,0.5) # using our correlation matrix visualization function
plt.xlabel('Features'); plt.ylabel('Features')
plt.subplot(122)
feature_rank_plot(features,semipartial_correlation,-1.0,1.0,0.0,'Feature Ranking, Semipartial Correlation with ' + resp,'Semipartial Correlation',0.5)
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=0.8, wspace=0.2, hspace=0.3); plt.show()
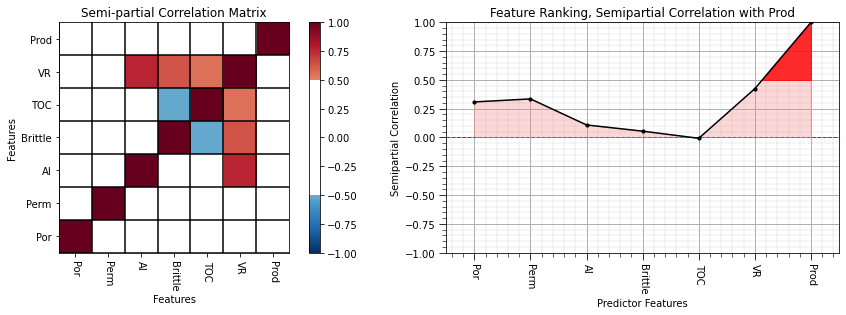
More information to consider:
porosity, permeability and vitrinite reflectance are the most important by this feature ranking method
all other predictor features have quite low correlations
This is a good moment to stop and take stock of all the results from the quantitative methods. We will plot them all together.
# plt.subplot(151)
# feature_rank_plot(features,covariance,-5000.0,5000.0,0.0,'Feature Ranking, Covariance with ' + resp,'Covariance',0.1)
plt.subplot(131)
feature_rank_plot(features,correlation,-1.0,1.0,0.0,'Feature Ranking, Correlation with ' + resp,'Correlation',0.5)
plt.subplot(132)
feature_rank_plot(features,rank_correlation,-1.0,1.0,0.0,'Feature Ranking, Rank Correlation with ' + resp,'Rank Correlation',0.5)
plt.subplot(133)
feature_rank_plot(features,partial_correlation,-1.0,1.0,0.0,'Feature Ranking, Partial Correlation with ' + resp,'Partial Correlation',0.5)
# plt.subplot(155)
# feature_rank_plot(features,semipartial_correlation,-1.0,1.0,0.0,'Feature Ranking, Semipartial Correlation with ' + resp,'Semipartial Correlation',0.5)
plt.subplots_adjust(left=0.0, bottom=0.0, right=3.2, top=1.2, wspace=0.3, hspace=0.2); plt.show()
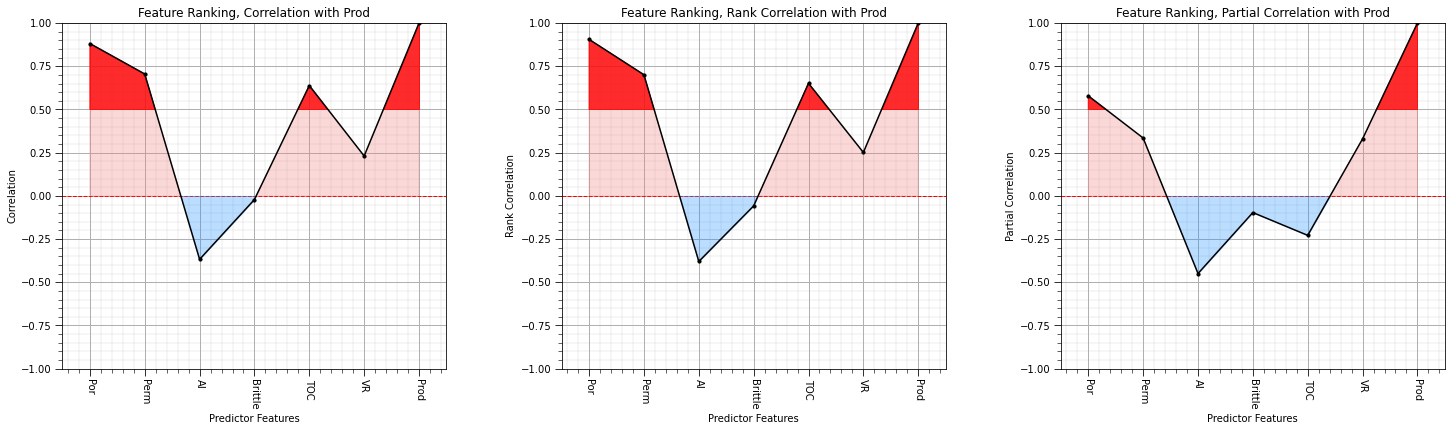
I think we are converging on porosity, permeability and vitrinite reflectance as the most important variables with respect to linear relationships with the production.
Feature Ranking with Feature Transformations#
There are many reasons to perform feature transformations (see the associated chapter) and as mentioned above for partial and semipartial correlation a distribution transformation may assist with compliance to metric assumptions.
As an exercise and check, let’s standardize all the features and repeat the previously calculated quantitative methods. We know this will have an impact on covariance, what about the other metrics?
There is a bunch of code to get this done, but it isn’t too complicated. First, lets make a new DataFrame with all variables standardized. Then we can make a minor edit (change the DataFrame name) and reuse the code from above. You can choose between:
Standardization - affine correction to scale the distributions to have \(\overline{x} = 0\) and \(\sigma_x = 1.0\).
Normal Score Transform - distribution transform of each feature to standard normal, Gaussian shape with \(\overline{x} = 0\) and \(\sigma_x = 1.0\).
Use this block to perform affine correction of the features:
# dfS = pd.DataFrame() # affine correction, standardization to a mean of 0 and variance of 1
# dfS['Well'] = df['Well'].values
# dfS['Por'] = GSLIB.affine(df['Por'].values,0.0,1.0)
# dfS['Perm'] = GSLIB.affine(df['Perm'].values,0.0,1.0)
# dfS['AI'] = GSLIB.affine(df['AI'].values,0.0,1.0)
# dfS['Brittle'] = GSLIB.affine(df['Brittle'].values,0.0,1.0)
# dfS['TOC'] = GSLIB.affine(df['TOC'].values,0.0,1.0)
# dfS['VR'] = GSLIB.affine(df['VR'].values,0.0,1.0)
# dfS['Prod'] = GSLIB.affine(df['Prod'].values,0.0,1.0)
# dfS.head()
Use this block to perform normal score transform of the features:
dfS = pd.DataFrame() # Gaussian transform, standardization to a mean of 0 and variance of 1
for feature in features:
dfS[feature],d1,d2 = geostats.nscore(df,feature)
dfS.head()
| Por | Perm | AI | Brittle | TOC | VR | Prod | |
|---|---|---|---|---|---|---|---|
| 0 | -0.964092 | -0.780664 | -0.285841 | 2.432379 | 0.312053 | 1.114651 | -1.780464 |
| 1 | -0.832725 | -0.378580 | 0.446827 | -0.195502 | -0.272809 | -0.325239 | -0.392079 |
| 2 | -0.312053 | -1.069155 | 1.722384 | 2.004654 | -0.272809 | 2.241403 | -0.832725 |
| 3 | 0.730638 | 1.325516 | -0.531604 | -0.590284 | 0.131980 | -0.325239 | 0.815126 |
| 4 | 0.698283 | 0.298921 | 0.365149 | -2.870033 | 1.047216 | -0.259823 | -0.531604 |
Regardless of the transformation that you chose it is best practice to check the summary statistics.
dfS.describe() # check the summary statistics
| Por | Perm | AI | Brittle | TOC | VR | Prod | |
|---|---|---|---|---|---|---|---|
| count | 200.000000 | 200.000000 | 2.000000e+02 | 2.000000e+02 | 200.000000 | 200.000000 | 2.000000e+02 |
| mean | -0.009700 | 0.010306 | 9.732356e-03 | 8.028717e-05 | 0.014152 | 0.017360 | 1.617223e-03 |
| std | 1.040456 | 1.005488 | 1.000221e+00 | 1.000278e+00 | 0.989223 | 1.000401 | 9.949811e-01 |
| min | -4.991462 | -3.355431 | -2.782502e+00 | -2.870033e+00 | -2.336891 | -2.899210 | -2.483589e+00 |
| 25% | -0.670577 | -0.647337 | -6.588985e-01 | -6.705770e-01 | -0.670577 | -0.651072 | -6.705770e-01 |
| 50% | 0.006267 | 0.006267 | 8.881784e-16 | 8.881784e-16 | 0.018807 | 0.006267 | 8.881784e-16 |
| 75% | 0.670577 | 0.678574 | 6.705770e-01 | 6.705770e-01 | 0.682378 | 0.682642 | 6.705770e-01 |
| max | 2.807034 | 2.807034 | 2.807034e+00 | 2.807034e+00 | 2.807034 | 2.807034 | 2.807034e+00 |
We should also check the matrix scatter plot again.
If you performed normal score transform, you have standardized the mean and variance and correct the univariate shape of the distribution, but the bivariate relationships still depart from Gaussian.
pairgrid = sns.PairGrid(dfS) # matrix scatter plots
pairgrid = pairgrid.map_upper(plt.scatter, color = 'darkorange', edgecolor = 'black', alpha = 0.8, s = 10)
pairgrid = pairgrid.map_diag(plt.hist, bins = 20, color = 'darkorange',alpha = 0.8, edgecolor = 'k')# Map a density plot to the lower triangle
pairgrid = pairgrid.map_lower(sns.kdeplot, cmap = plt.cm.inferno,
shade = False, shade_lowest = False, alpha = 1.0, n_levels = 10)
pairgrid.add_legend()
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.9, top=0.9, wspace=0.2, hspace=0.2); plt.show()
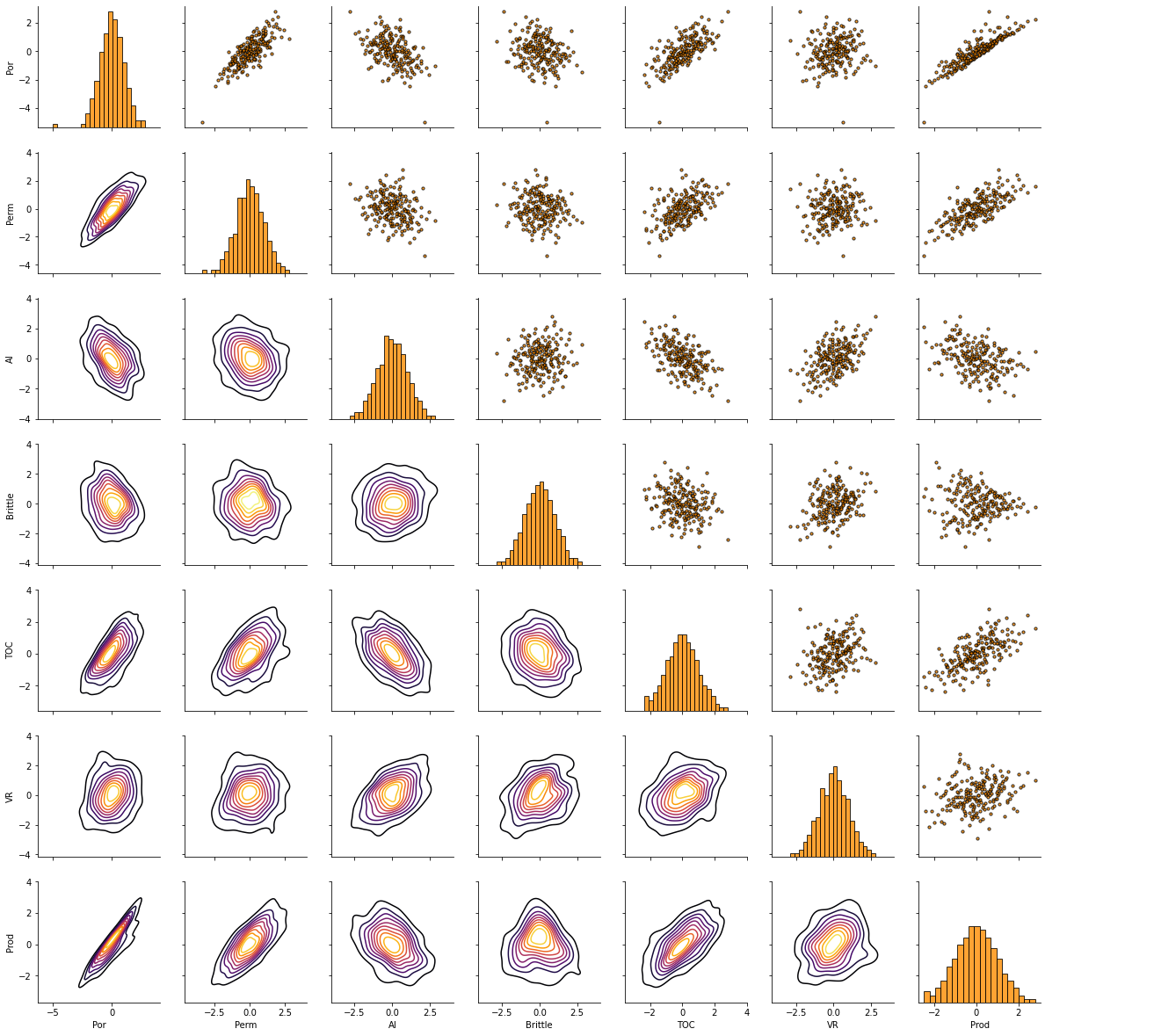
This is the new DataFrame with standardized variables. Now we repeat the previous calculations.
We will be more efficient this time and use quite compact code.
stand_covariance = dfS.iloc[:,dfS.columns.get_indexer(features)].cov().iloc[len(features)-1,:len(features)]
stand_correlation = dfS.iloc[:,dfS.columns.get_indexer(features)].corr().iloc[len(features)-1,:len(features)]
stand_rank_correlation, stand_rank_correlation_pval = stats.spearmanr(dfS.iloc[:,dfS.columns.get_indexer(features)])
stand_rank_correlation = stand_rank_correlation[:,len(features)-1][:len(features)]
stand_partial_correlation = partial_corr(dfS.iloc[:,dfS.columns.get_indexer(features)]) # calculate the partial correlation coefficients
stand_partial_correlation = stand_partial_correlation[:,len(features)-1][:len(features)]
stand_semipartial_correlation = semipartial_corr(dfS.iloc[:,dfS.columns.get_indexer(features)]) # calculate the semi-partial correlation coefficients
stand_semipartial_correlation = stand_semipartial_correlation[:,len(features)-1][:len(features)]
and repeat the previous summary plot.
# plt.subplot(2,5,1)
# feature_rank_plot(features,covariance,-5000.0,5000.0,0.0,'Feature Ranking, Covariance with ' + resp,'Covariance',0.5)
plt.subplot(2,3,1)
feature_rank_plot(features,correlation,-1.0,1.0,0.0,'Feature Ranking, Correlation with ' + resp,'Correlation',0.5)
plt.subplot(2,3,2)
feature_rank_plot(features,rank_correlation,-1.0,1.0,0.0,'Feature Ranking, Rank Correlation with ' + resp,'Rank Correlation',0.5)
plt.subplot(2,3,3)
feature_rank_plot(features,partial_correlation,-1.0,1.0,0.0,'Feature Ranking, Partial Correlation with ' + resp,'Partial Correlation',0.5)
# plt.subplot(2,5,5)
# feature_rank_plot(features,semipartial_correlation,-1.0,1.0,0.0,'Feature Ranking, Semipartial Correlation with ' + resp,'Semipartial Correlation',0.5)
# plt.subplot(2,5,6)
# feature_rank_plot(features,stand_covariance,-1.0,1.0,0.0,'Feature Ranking, Covariance with ' + resp,'Covariance of Standardized',0.5)
plt.subplot(2,3,4)
feature_rank_plot(features,stand_correlation,-1.0,1.0,0.0,'Feature Ranking, Correlation with ' + resp,'Correlation of Standardized',0.5)
plt.subplot(2,3,5)
feature_rank_plot(features,stand_rank_correlation,-1.0,1.0,0.0,'Feature Ranking, Rank Correlation with ' + resp,'Rank Correlation of Standardized',0.5)
plt.subplot(2,3,6)
feature_rank_plot(features,stand_partial_correlation,-1.0,1.0,0.0,'Feature Ranking, Partial Correlation with ' + resp,'Partial Correlation of Standardized',0.5)
# plt.subplot(2,5,10)
# feature_rank_plot(features,stand_semipartial_correlation,-1.0,1.0,0.0,'Feature Ranking, Semipartial Correlation with ' + resp,'Semipartial Correlation of Standardized',0.5)
plt.subplots_adjust(left=0.0, bottom=0.0, right=3.2, top=2.2, wspace=0.3, hspace=0.3); plt.show()
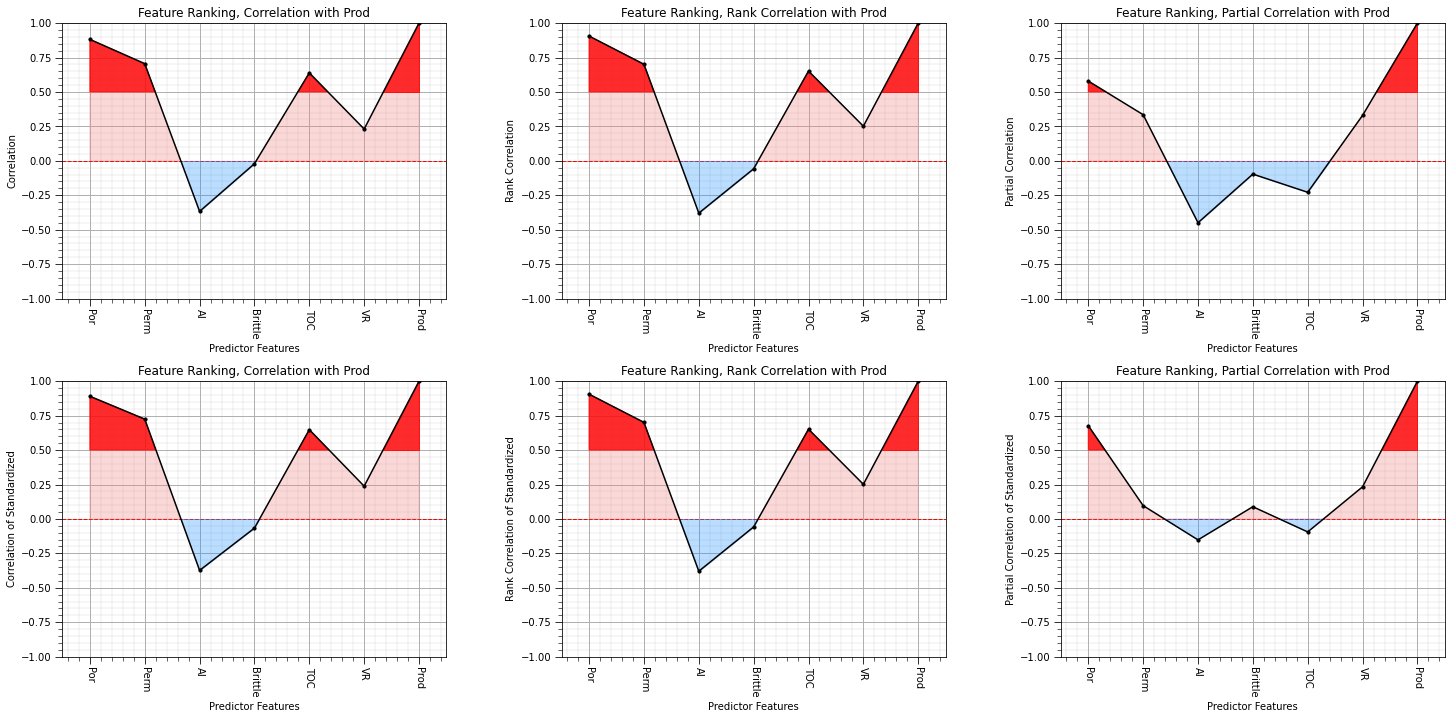
What can you observe:
covariance is now equal to correlation coefficient
the semipartial correlations are sensitive to the feature standardization (affine correlation or normal score transform).
Conditional Statistics#
We will separate the wells into low, mid and high production and access the difference in the conditional statistics.
This will provide a more flexible method to compare the relationship between each feature and production
If the conditional statistics change significantly then that feature is informative
We are going to make a single violin plot over all of our features
We need a categorical feature for production, so we truncate production to High or Low with this code,
df['tProd'] = np.where(df['Prod']>=4000, 'High', 'Low')
We will need to standardize all of our features so we can observe their relative differences together
x = df[['Por','Perm','AI','Brittle','TOC','VR']]
x_stand = (x - x.mean()) / (x.std())
This code extracted the features into a new DataFrame ‘x’, then applied the standardization operation on each column (feature)
Then we add the truncated production feature into the standardized features
x = pd.concat([df['tProd'],x_stand.iloc[:,0:6]],axis=1)
We can then apply the melt command to unpivot the DataFrame
x = pd.melt(x,id_vars="tProd",var_name="Predictors",value_name='Standardized_Value')
We now have a long DataFrame (6 features x 200 samples = 12000 rows) with:
production: Low or High
features: Por, Perm, AI, Brittle, TOC or VR
standardized feature value
We can then build our violin plot
x is our predictor features
y is the standardized values for the predictor features (all now in one column)
hue is the production level High or Low
split is True so the violins are split in half
inner is quartiles for P25, P50 and P75 are plotted as dashed lines
threshold = 2000.0
df['tProd'] = np.where(df[resp]>=threshold, 'High', 'Low') # make a high and low production categorical feature
x_temp = df[pred]
x_temp_stand = (x_temp - x_temp.mean()) / (x_temp.std()) # standardization by feature
x_temp = pd.concat([df['tProd'],x_temp_stand.iloc[:,0:len(pred)]],axis=1) # add the production categorical feature to the DataFrame
x_temp = pd.melt(x_temp,id_vars="tProd",var_name="Predictor Feature",value_name='Standardized Predictor Feature') # unpivot the DataFrame
plt.subplot(111)
sns.violinplot(x="Predictor Feature", y="Standardized Predictor Feature", hue="tProd", data=x_temp,split=True, inner="quart", palette="Set2")
plt.xticks(rotation=90); plt.title('Conditional Distributions by Production')
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.5, top=1.5, wspace=0.2, hspace=0.2); plt.show()
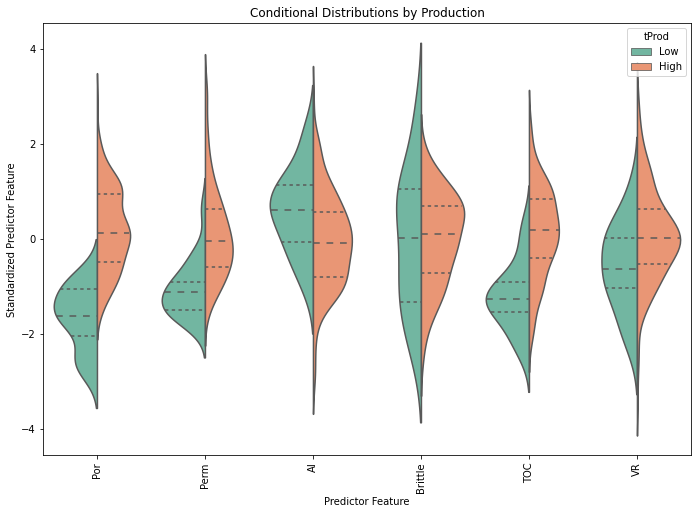
From the violin plot we can observe that the conditional distributions of porosity, permeability, TOC have the most variation between low and high production wells.
We can replace the plot with box and whisker plots of the conditional distributions.
Box and whisker plots improve our ability to observe the conditional P25, P75 and the upper and lower bounds from the Tukey outlier test.
plt.subplot(111)
sns.boxplot(x="Predictor Feature", y="Standardized Predictor Feature", hue="tProd", data=x_temp)
plt.xticks(rotation=90)
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.5, top=1.5, wspace=0.2, hspace=0.2)
plt.show()
df = df.drop(['tProd'], axis = 1)
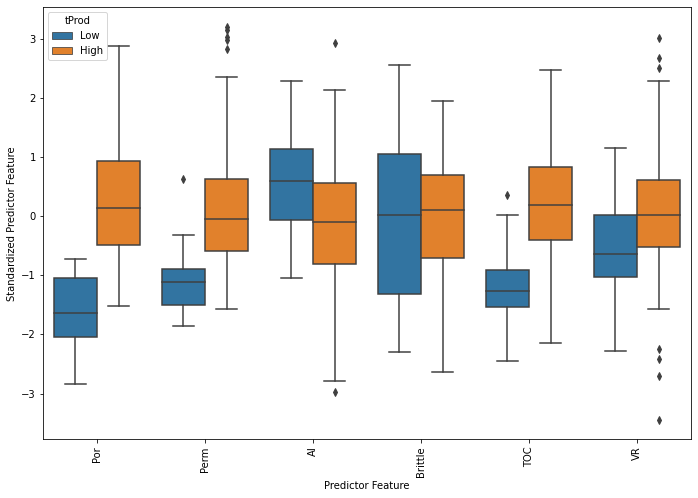
From the conditional box plot we can observe that the conditional distributions of porosity, permeability, TOC have the most variation between low and high production wells.
We can observed the outliers in porosity, permeability (upper tail), total organic carbon (lower tail) and vitrinite reflectance.
Variance Inflation Factor (VIF)#
A measure of linear multicollinearity between a predictor feature (\(X_i\)) a nd all other predictor features (\(X_j, \forall j \ne i\)).
First we calculate a linear regression for a predictor feature given all the other predictor features.
From this model we determine the coefficient of determination, \(R^2\), known as variance explained.
Then we calculate the Variance Inflation Factor as:
vif_values = []
for i in range(df[pred].values.shape[1]):
vif_values.append(variance_inflation_factor(df[pred].values, i))
vif_values = np.asarray(vif_values)
indices = np.argsort(vif_values)[::-1] # find indices for descending order
plt.subplot(111) # plot the feature importance
plt.title("Variance Inflation Factor")
plt.bar(range(df[pred].values.shape[1]), vif_values[indices],edgecolor = 'black',
color="darkorange",alpha=0.6, align="center")
plt.xticks(np.linspace(0,len(pred)-1,len(pred)), np.array(pred)[indices].tolist(),rotation=90);
plt.gca().yaxis.grid(True, which='major',linewidth = 1.0); plt.gca().yaxis.grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
plt.xlim([-0.5, x.shape[1]-0.5]); plt.yscale('log');
plt.xlabel('Predictor Feature'); plt.ylabel('Variance Inflation Factor')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2., top=1., wspace=0.2, hspace=0.5)
plt.show()
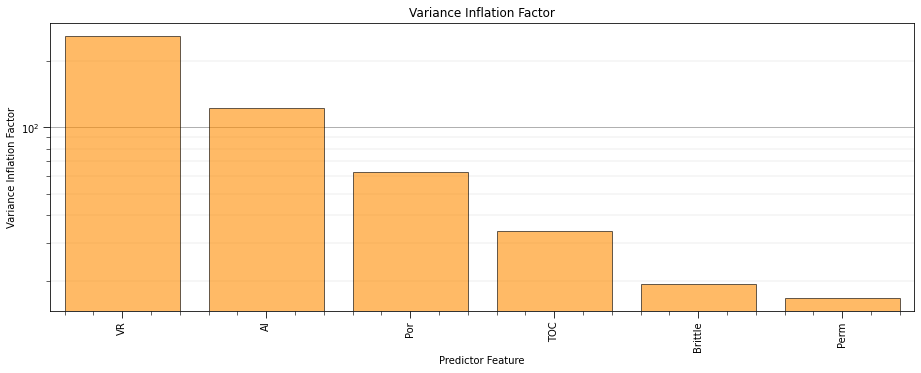
Vitrinite reflectance has the most linear redundancy while permeability has the least linear redundancy with other predictor features.
remember, high variance inflation factor is bad
recall that variance inflation factor does not integrate the relationship between each predictor feature and the response feature.
typically, variance inflation factor is used as a screening tool to remove features that have too much redundancy with other predictor features.
Now let’s cover model-based feature ranking methods.
\(B\) Coefficients / Beta Weights#
We could also consider \(B\) coefficients. These are the linear regression coefficients without standardization of the variables. Let’s use the linear regression method that is available in the SciPy package.
The estimator for \(Y\) is simply the linear equation:
\begin{equation} Y^* = \sum_{i=1}^{m} b_i X_i + c \end{equation}
The \(b_i\) coefficients are solved to minimize the squared error between the estimates, \(Y^*\) and the values in the training dataset, \(Y\).
reg = LinearRegression() # instantiate a linear regression model
reg.fit(df[pred],df[resp]) # train the model
b = reg.coef_
plt.subplot(111)
feature_rank_plot(pred,b,-1000.0,1000.0,0.0,'Feature Ranking, B Coefficients with ' + resp,r'Linear Regression Slope, $b_1$',0.5)
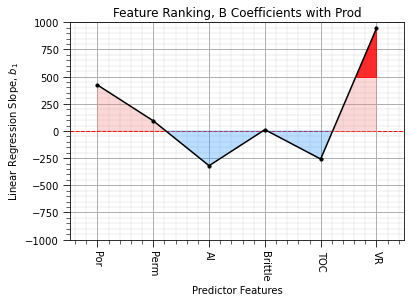
The output is the \(b\) coefficients, ordered over our features from \(b_i, i = 1,\ldots,n\) and then the intercept, \(c\), that I have removed to avoid confusion.
we see the negative contribution of AI and TOC
the results are very sensitive to the magnitudes of the variances of the predictor features.
We can remove this sensitivity by working with standardized features.
\(\beta\) Coefficients / Beta Weights#
\(\beta\) coefficients are calculated as the linear regression of the coefficients after we have standardized the predictor and response features to have a variance of one.
\begin{equation} \sigma^2_{X^s_i} = 1.0 \quad \forall \quad i = 1,\ldots,m, \quad \sigma^2_{Y^s} = 1.0 \end{equation}
The estimator for \(Y^s\) standardized is simply the linear equation:
\begin{equation} Y^{s*} = \sum_{i=1}^{m} \beta_i X^s_i + c \end{equation}
It is convenient that we have just standardized all our variables to have a variance of 1.0 just recently (see above). Let’s use the same linear regression method again on the standardized features to get \(\beta\) coefficients.
reg = LinearRegression()
reg.fit(dfS[pred],dfS[resp])
beta = reg.coef_
plt.subplot(111)
feature_rank_plot(pred,beta,-1.0,1.0,0.0,r'Feature Ranking, $\beta$ Coefficients with ' + resp,r'Standardized Linear Regression Slope, $b_1$',0.5)
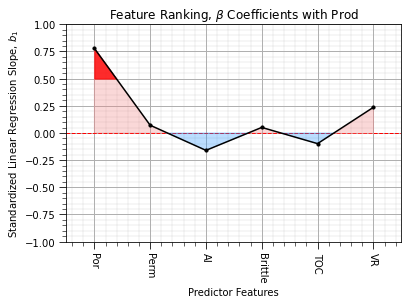
Some observations:
the change between \(b\) and \(\beta\) coefficients is not just a constant scaling on the ranking metrics, because the linear model coefficients are also sensitive to the ranges and magnitudes of the features.
with beta coefficients porosity, acoustic impedance and total organic carbon have higher rank for estimating production
Feature Importance#
A variety of machine learning methods provide measures of feature importance, for example decision trees the reduction in mean square error through inclusion of each feature and is summarized as:
where \(T_f\) are all nodes with feature \(x\) as the split, \(N_t\) is the number of training samples reaching node \(t\), \(N\) is the total number of samples in the dataset and \(\Delta_{MSE_t}\) is the reduction in MSE with the \(t\) split.
Note, feature importance can be calculated in a similar manner to MSE above for the case of classification trees with Gini Impurity.
Let’s look at the feature importance from a random forest regression model fit to our data.
We instantiate a random forest with default hyperparameters. This results in unlimited complexity, over-trained trees in our forest. The averaging of these trees takes care of the overfit issue.
Then we train our random forest and extract the feature importances, calculated as the expectated feature importance over all the trees in the forest.
we can also extract the feature importances over all the trees in the forest and summarize with the standard deviation to access the robustness, uncertainty of our feature importance measure
For more information check out my lecture on random forest predictive machine learning.
# Code modified from https://www.kaggle.com/kanncaa1/feature-selection-and-data-visualization
lab_enc = preprocessing.LabelEncoder(); Y_encoded = lab_enc.fit_transform(Y) # this removes an encoding error
random_forest = RandomForestRegressor() # instantiate the random forest
random_forest = random_forest.fit(x,np.ravel(Y_encoded)) # fit the random forest
importance_rank = random_forest.feature_importances_ # extract the expected feature importances
importance_rank_stand = importance_rank/np.max(importance_rank) # calculate relative mutual information
std = np.std([tree.feature_importances_ for tree in random_forest.estimators_],axis=0) # calculate stdev over trees
indices = np.argsort(importance_rank)[::-1] # find indices for descending order
plt.subplot(111) # plot the feature importance
plt.title("Random Forest-based Feature importances")
plt.bar(range(x.shape[1]), importance_rank[indices],edgecolor = 'black',
color="darkorange",alpha = 0.6, yerr=std[indices], align="center")
plt.xticks(range(x.shape[1]), x.columns[indices],rotation=90)
plt.xlim([-0.5, x.shape[1]-0.5]);
plt.gca().yaxis.grid(True, which='major',linewidth = 1.0); plt.gca().yaxis.grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
plt.ylim([0.,1.0])
plt.xlabel('Predictor Feature'); plt.ylabel('Feature Importance')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2., top=1., wspace=0.2, hspace=0.5)
plt.show()
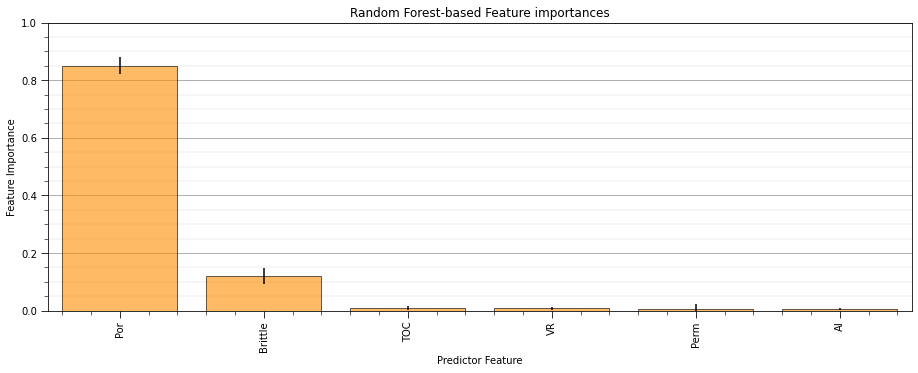
There is more we can do with model-based methods. We will actually test models to assess the incremental impact of each predictor feature! We will try this with recursive feature elimination.
Let’s plot the results from the \(B\) and \(\beta\) coefficients and compare with the previous results.
plt.subplot(231)
feature_rank_plot(features,rank_correlation,-1.0,1.0,0.0,'Feature Ranking, Rank Correlation with ' + resp,'Rank Correlation',0.5)
plt.subplot(232)
feature_rank_plot(features,partial_correlation,-1.0,1.0,0.0,'Feature Ranking, Partial Correlation with ' + resp,'Partial Correlation',0.5)
plt.subplot(234)
feature_rank_plot(pred,b[0:len(pred)],-1000.0,1000.0,0.0,'Feature Ranking, B Coefficients with ' + resp,'B Coefficients',0.5)
plt.subplot(235)
feature_rank_plot(pred,beta[0:len(pred)],-1.0,1.0,0.0,'Feature Ranking, Beta Coefficients with ' + resp,'Beta Coefficients',0.5)
plt.subplot(236)
feature_rank_plot(pred,importance_rank_stand,0.0,1.0,0.0,'Feature Ranking, Feature Importance with ' + resp,'Standardized Feature Importance',0.5)
plt.subplots_adjust(left=0.0, bottom=0.0, right=3.2, top=2.2, wspace=0.2, hspace=0.3); plt.show()
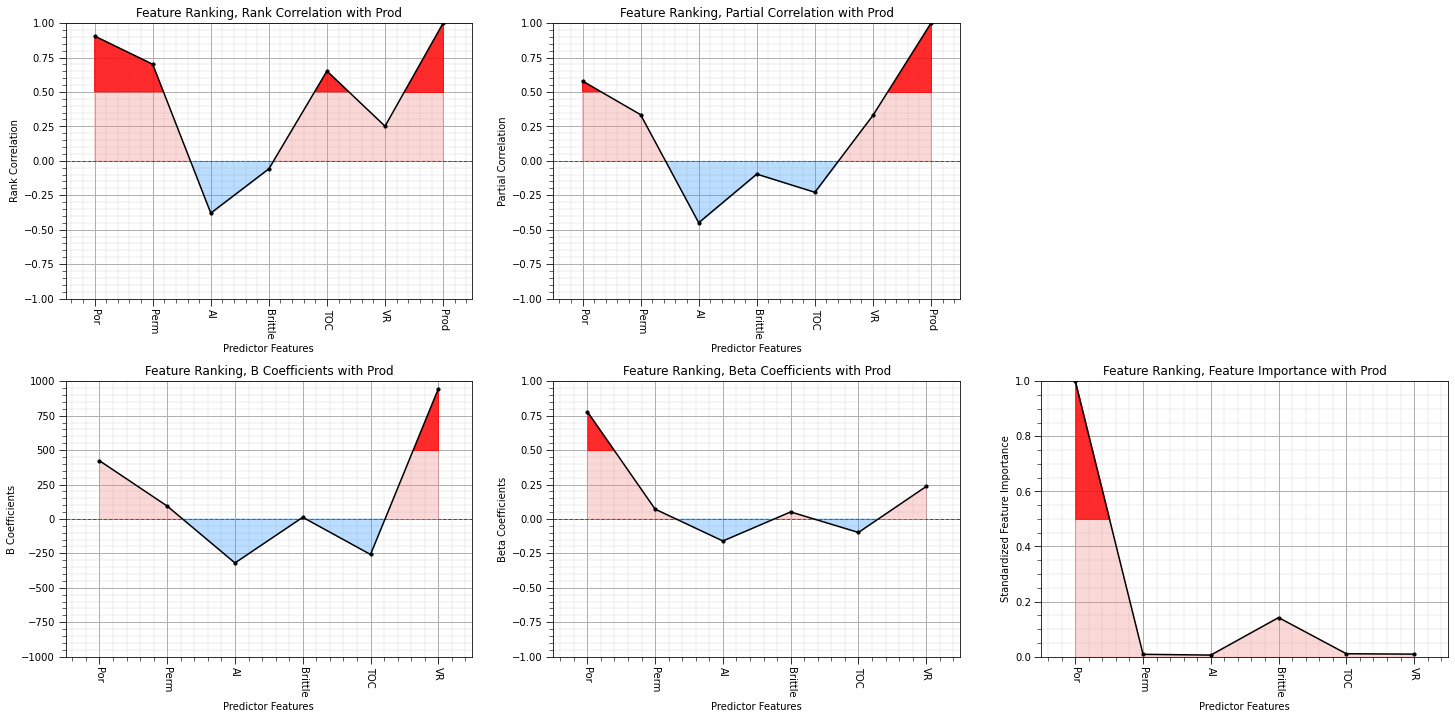
Mutual Information#
Mutual information is a generalized approach that quantifies the mutual dependence between two features.
quantifies the amount of information gained from observing one feature about the other
avoids any assumption about the form of the relationship (e.g. no assumption of linear relationship)
compares the joint probabilities to the product of the marginal probabilities
For discrete or binned continuous features \(X\) and \(Y\), mutual information is calculated as:
recall, given independence between \(X\) and \(Y\):
therefore if the two features are independent then the \(log \left( \frac{P_{X,Y}(x,y)}{P_X(x) \cdot P_Y(y)} \right) = 0\)
The joint probability \(P_{X,Y}(x,y)\) is a weighting term on the sum and enforces closure.
parts of the joint distribution with greater density have greater impact on the mutual information metric
For continuous (and nonbinned) features we can applied the integral form.
We get a sorted list of the indices in decreasing order of importance with the command
indices = np.argsort(importances)[::-1]
the slice reverses the order, for descending order of feature importance.
x_df = df.loc[:,pred] # separate DataFrames for predictor and response features
y_df = df.loc[:,resp]
mi = mutual_info_regression(x_df,np.ravel(y_df)) # calculate mutual information
mi /= np.max(mi) # calculate relative mutual information
indices = np.argsort(mi)[::-1] # find indices for descending order
print("Feature ranking:") # write out the feature importances
for f in range(x.shape[1]):
print("%d. feature %s = %f" % (f + 1, x.columns[indices][f], mi[indices[f]]))
plt.subplot(111) # plot the relative mutual information
plt.title("Mutual Information")
plt.bar(range(x.shape[1]), mi[indices],edgecolor = 'black',
color="darkorange",alpha=0.6,align="center")
plt.xticks(range(x.shape[1]), x.columns[indices],rotation=90)
plt.xlim([-0.5, x.shape[1]-0.5]); plt.ylim([0,1.3])
plt.gca().yaxis.grid(True, which='major',linewidth = 1.0); plt.gca().yaxis.grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
plt.xlabel('Predictor Feature'); plt.ylabel('Mutual Information')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2., top=1., wspace=0.2, hspace=0.5)
plt.show()
Feature ranking:
1. feature Por = 1.000000
2. feature Perm = 0.345842
3. feature TOC = 0.272418
4. feature Brittle = 0.073310
5. feature AI = 0.059024
6. feature VR = 0.000000
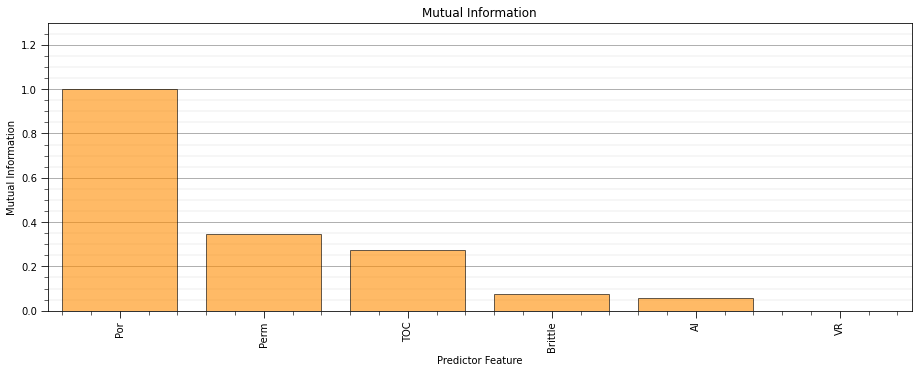
Mutual Information Accounting For Relevance and Redundancy#
The standard Maximum Relevance - Minumum Redundancy (MRMR) objective function considers a subset of predictor features, i.e., to score predictor feature subsets as metric to identify the most informative subset of predictor features.
the approach calculates the average mutual information between the subset of predictor features and the response feature minus the average mutual information between the subset of predictor features.
\begin{equation} MID = \frac{1}{|S|}{\sum_{\alpha \in S} I(X_{\alpha},Y) } - \frac{1}{|S|^2} {\sum_{\alpha \in S}^m \sum_{\beta \in S}^m I(X_{\alpha},X_{\beta})} \end{equation}
as a measure of \(relevance - redundancy\) or
\begin{equation} MIQ = \frac{ \frac{1}{|S|}{\sum_{\alpha \in S}^m I(X_{\alpha},Y) } }{ \frac{1}{|S|^2} {\sum_{\alpha \in S}^m \sum_{\beta \in S}^m I(X_{\alpha},X_{\beta})} } \end{equation}
as a measure of \(\frac{relevance}{redundancy}\).
Mutual Information Accounting For Relevance and Redundancy OFAT Variants#
I propose that for one-feature-at-a-time (OFAT) predictor feature ranking (predictor feature subset, \(S = [X_i]\) and \(|S| = 1\)) we modify this to the following calculation:
relevance - the mutual information between the selected predictor feature, \(X_i\), and the response feature, \(Y\)
redundancy - the average mutual information between the selected predictor feature, \(X_i\), and the remaining predictor features, \(X_{\alpha}, \alpha \ne i\).
we use the quotient form of the calculation from Gulgezen, Cataltepe and Yu (2009).
Our modified version of the Maximum Relevance - Minumum Redundancy (MRMR) objective function for OFAT ranking scores the selected predictor feature \(X_i\)’s relevance as its mutual information with the response feature:
\begin{equation} I(X_i,Y) \end{equation}
and redundancy between the selected predictor feature, \(X_i\), and the remaining predictor features:
\begin{equation} \frac{1}{|S|-1} \sum_{\alpha=1, \alpha \ne i}^m I(X_i,X_{\alpha}) \end{equation}
were \(X\) are predictor features, \(Y\) is the response feature, \(X_i\) is the specific predictor feature being scored and \(|S|\) is the number of predictor features and \(I()\) is mutual information between the indicated features. One formulation is a simple difference, relevance minus redundancy,
an alternative is a ratio,
Here the feature ranks for the mutual information relevance minus redundancy, \(\Phi_{\Delta}(X_i,Y)\), approach.
obj_mutual = mutual_information_objective(x_df,y_df)
indices_obj = np.argsort(obj_mutual)[::-1] # find indices for descending order
plt.subplot(111) # plot the relative mutual information
plt.title("One-at-a-Time MRMR Objective Function for Mutual Information-based Feature Selection")
plt.bar(range(x.shape[1]), obj_mutual[indices_obj],
color="darkorange",alpha = 0.6, align="center",edgecolor="black")
plt.xticks(range(x.shape[1]), x.columns[indices_obj],rotation=90)
plt.gca().yaxis.grid(True, which='major',linewidth = 1.0); plt.gca().yaxis.grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
plt.xlim([-0.5, x.shape[1]-0.5]); plt.xlabel('Predictor Feature'); plt.ylabel('Feature Importance')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2., top=1., wspace=0.2, hspace=0.5)
plt.show()
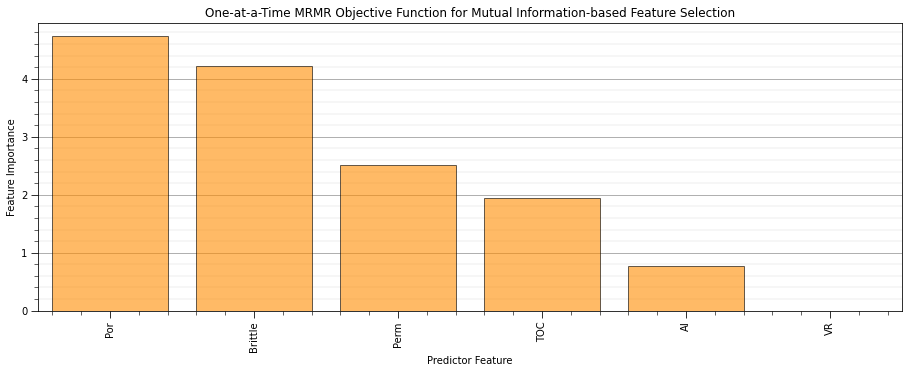
Delta Mutual Information Quotient Accounting for Relevance and Redundancy#
We use adapt the mutual information quotient from Gulgezen, Cataltepe and Yu (2009) to develop an OFAT ranking metric.
The standard MRMR objective function that scores the subset of features’ relevance between the subset of predictor features and the response feature:
\begin{equation} \frac{1}{|S|}{\sum_{\alpha=1}^m I(X_{\alpha},Y) } \end{equation}
and redundancy between the subset of predictor features:
\begin{equation} \frac{1}{|S|^2} {\sum_{\alpha=1}^m \sum_{\beta=1}^m I(X_{\alpha},X_{\beta})} \end{equation}
To find the most informative subset of predictor features we must find the subset of features that maximize relevance while minimizing redundancy. We can accomplish this by maximizing either of these two formulations,
\begin{equation} MID = \frac{1}{|S|}{\sum_{\alpha=1}^m I(X_{\alpha},Y) } - \frac{1}{|S|^2} {\sum_{\alpha=1}^m \sum_{\beta=1}^m I(X_{\alpha},X_{\beta})} \end{equation}
or
\begin{equation} MIQ = \frac{ \frac{1}{|S|}{\sum_{\alpha=1}^m I(X_{\alpha},Y) } }{ \frac{1}{|S|^2} {\sum_{\alpha=1}^m \sum_{\beta=1}^m I(X_{\alpha},X_{\beta})} } \end{equation}
I suggest feature ranking through the calculation of the change in \(MIQ\) via inclusion and removal of a specific predictor feature (\(X_i\)).
\begin{equation} \Delta MIQ_i = \frac{ \frac{1}{|S|}{\sum_{\alpha=1}^m I(X_{\alpha},Y) } }{ \frac{1}{|S|^2} {\sum_{\alpha=1}^m \sum_{\beta=1}^m I(X_{\alpha},X_{\beta})} } - \frac{ \frac{1}{|S|}{\sum_{\alpha=1,\alpha \ne i}^m I(X_{\alpha},Y) } }{ \frac{1}{|S|^2} {\sum_{\alpha=1,\alpha \ne i}^m \sum_{\beta=1,\beta \ne i}^m I(X_{\alpha},X_{\beta})} } \end{equation}
delta_mutual_information = delta_mutual_information_quotient(x_df,y_df)
indices_delta_mutual_information = np.argsort(delta_mutual_information)[::-1] # find indices for descending order
plt.subplot(111) # plot the relative mutual information
plt.title("Delta Mutual Information Quotient")
plt.bar(range(x.shape[1]), delta_mutual_information[indices_delta_mutual_information],
color="darkorange",alpha = 0.6,align="center",edgecolor = 'black')
plt.xticks(range(x.shape[1]), x.columns[indices_delta_mutual_information],rotation=90)
plt.xlim([-0.5, x.shape[1]-0.5])
plt.gca().yaxis.grid(True, which='major',linewidth = 1.0); plt.gca().yaxis.grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
plt.plot([-0.5,x.shape[1]-0.5],[0,0],color='black',lw=3); plt.xlabel('Predictor Feature'); plt.ylabel('Feature Importance')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2., top=1., wspace=0.2, hspace=0.5)
plt.show()
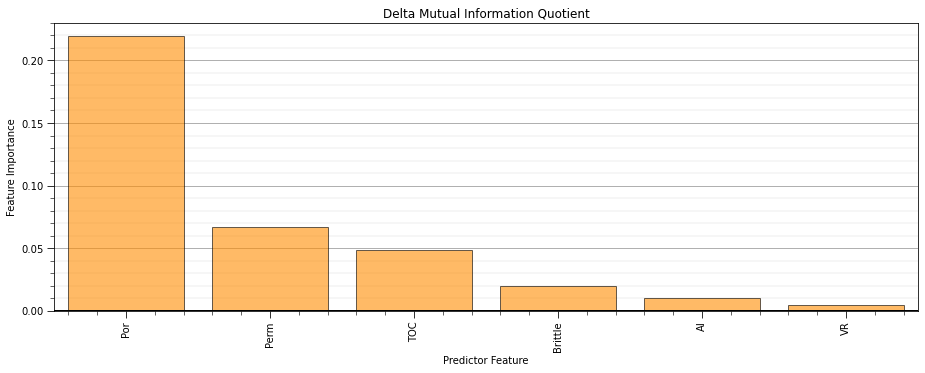
It is intructive to compare delta mutual information and variance inflation factor ranking. Both of these methods account for predictor feature redundancy.
but VIF assumes linearity and does not account for relevance
plt.scatter(stats.rankdata(delta_mutual_information),stats.rankdata(-vif_values),c='black',edgecolor='black')
for i, feature in enumerate(x.columns):
plt.annotate(feature, (stats.rankdata(delta_mutual_information)[i]-0.2,stats.rankdata(-vif_values)[i]+0.1))
plt.xlabel('Delta Mutual Information Rank'); plt.ylabel('Variance Inflation Factor Rank'); plt.title('Variance Inflation Factor vs. Delta Mutual Information Ranking')
plt.xlim(0,len(pred)+0.1); plt.ylim(0,len(pred)+0.1)
plt.plot([2,len(pred)],[0,len(pred)-2],color='black',alpha=0.5,ls='--');
plt.plot([0,len(pred)-2],[2,len(pred)],color='black',alpha=0.5,ls='--')
plt.fill_between([0,len(pred)-2], [2,len(pred)], [len(pred),len(pred)], color='coral',alpha=0.2,zorder=1)
plt.fill_between([2,len(pred)], [0,len(pred)-2], [0,0], color='dodgerblue',alpha=0.2,zorder=1)
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.5, top=1.5, wspace=0.2, hspace=0.2); plt.show()
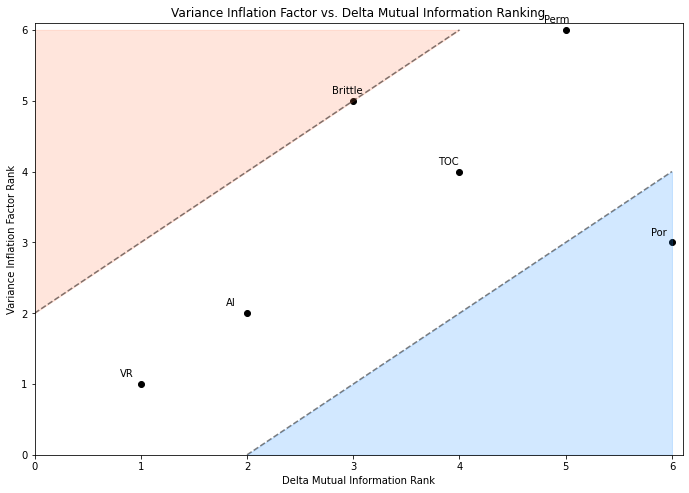
From mutual information we can observe that porosity, permeability then total organic carbon and brittleness have the greatest departure from general independence.
Summary of All Bivariate Metrics#
We have a wide array of criteria to rank our features.
the \(B\) coefficient have the same issue as covariance, sensitivity to the univariate variance
the \(\beta\) coefficients remove this sensitivity and are consistent with previous results.
Given all of these methods, I would rank the variables as:
Porosity
Vitrinite Reflectance
Acoustic Impedance
Permeability
Total Organic Carbon
Brittleness
I have assigned these ranks by observing the general trend in these metrics. Of course, we could make a more quantitative score and rank by weighting each method.
As mentioned before, we should not neglect expert knowledge. If additional information is known about physical processes, causation, and reliability and availability of variables this should be integrated into assigning ranks.
We include a bonus method here, recursive feature elimination, but only provide a simple linear regression model example. More could be done with more complicated models.
Recursive Feature Elimination#
Recursive Feature Elimination (RFE) method works by recursively removing features and building a model with the remaining features.
for the first step, all features are used to build a model and the features are ranked by feature importance or the \(\beta\) coefficient
the least important feature is pruned and the model is rebuilt
this is repeated until there is only one feature remaining
In this code we make a prediction model based on multilinear regression and indicate that we want to find the best feature based on recursive feature elimination. The algorithm assigns rank \(1,\ldots,m\) for all features.
rfe_linear = RFE(LinearRegression(),n_features_to_select=1,verbose=0) # set up RFE linear regression model
df['const'] = np.ones(len(df)) # let's add one's for the constant term
rfe_linear = rfe_linear.fit(df[pred].values,np.ravel(df[resp])) # recursive elimination
dfS = df.drop('const',axis = 1) # remove the ones
print('Recursive Feature Elimination: Multilinear Regression')
for i in range(0,len(pred)):
print('Rank #' + str(i+1) + ' ' + pred[rfe_linear.ranking_[i]-1])
Recursive Feature Elimination: Multilinear Regression
Rank #1 Brittle
Rank #2 TOC
Rank #3 AI
Rank #4 VR
Rank #5 Por
Rank #6 Perm
The advantages with the recursive elimination method:
the actual model can be used in assessing feature ranks
the ranking is based on accuracy of the estimate
but this method is sensitive to:
choice of model
training dataset
The feature ranks are quite different from our previous methods. Many have moved from the previous assessment. Perhaps we should use a more flexible modeling method.
Let’s repeat this method with a more flexible machine learning method, a decision tree regression model.
from sklearn.ensemble import RandomForestRegressor
import warnings
warnings.filterwarnings('ignore')
import geostatspy.GSLIB as GSLIB # GSLIB utilities, visualization and wrapper
rfe_rf = RFE(RandomForestRegressor(max_depth=3),n_features_to_select=1,verbose=0) # set up RFE linear regression model
df['const'] = np.ones(len(df)) # let's add one's for the constant term
lab_enc = preprocessing.LabelEncoder(); Y_encoded = lab_enc.fit_transform(Y)
rfe_rf = rfe_rf.fit(x,np.ravel(Y_encoded)) # recursive elimination
dfS = df.drop('const',axis = 1) # remove the ones
print('Recursive Feature Elimination: Random Forest Regression')
for i in range(0,len(pred)):
print('Rank #' + str(i+1) + ' ' + pred[rfe_rf.ranking_[i]-1])
Recursive Feature Elimination: Random Forest Regression
Rank #1 Por
Rank #2 VR
Rank #3 Brittle
Rank #4 Perm
Rank #5 TOC
Rank #6 AI
Once again, recursive feature elimination for feature ranking is sensitive to the accuracy of the model.
the actual prediction model must have its associated hyperparameters tuned and the model accuracy checked.
for example, in this case the multilinear regression feature ranks are unreliable due to the poor accuracy of the linear model.
Shapley Values for Feature Ranking#
Let’s take a random subset of the data, as background values to evaluate our model.
we subset for faster calculation
we should evaluate / enforce efficient coverage of the predictor feature space
Since Shapley values are model based, we must start with building a model
Build a Random Forest Model#
Since Shapley is model based we need to build a model
Let’s start with a good random forest model, observe Shapley and then return here and modify the model
seed = 73093 # set the random forest hyperparameters
# #Underfit random forest
max_leaf_nodes = 2
num_tree = 10
max_features = 2
#Overfit random forest
max_leaf_nodes = 50
num_tree = 1
max_features = 6
# #Good random forest
max_leaf_nodes = 5
num_tree = 300
max_features = 2
rfr = RandomForestRegressor(max_leaf_nodes=max_leaf_nodes, random_state=seed,n_estimators=num_tree, max_features=max_features)
rfr.fit(X = x, y = Y)
Y_hat = predict_train = rfr.predict(x)
MSE = metrics.mean_squared_error(Y,Y_hat)
Var_Explained = metrics.explained_variance_score(Y,Y_hat)
print('Mean Squared Error on Training = ', round(MSE,2),', Variance Explained =', round(Var_Explained,2))
importances = rfr.feature_importances_ # expected (global) importance over the forest fore each predictor feature
std = np.std([rfr.feature_importances_ for tree in rfr.estimators_],axis=0)
indices = np.argsort(importances)[::-1].tolist()
plt.subplot(121)
plt.scatter(Y,Y_hat,s=None, c='darkorange',marker=None, cmap=None, norm=None, vmin=None, vmax=None, alpha=0.8, linewidths=0.3, edgecolors="black")
plt.title('Random Forest Model'); plt.xlabel('Actual Production (MCFPD)'); plt.ylabel('Estimated Production (MCFPD)')
plt.xlim(0,7000); plt.ylim(0,7000)
plt.arrow(0,0,7000,7000,width=0.02,color='black',head_length=0.0,head_width=0.0)
plt.subplot(122)
plt.title("Feature Importances")
plt.bar([pred[i] for i in indices],rfr.feature_importances_[indices],color="darkorange", alpha = 0.8, edgecolor = 'black', yerr=std[indices], align="center")
#plt.xticks(range(X.shape[1]), indices)
plt.ylim(0,1), plt.xlabel('Predictor Features'); plt.ylabel('Feature Importance')
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.2, top=0.8, wspace=0.2, hspace=0.2); plt.show()
Mean Squared Error on Training = 428100.87 , Variance Explained = 0.82
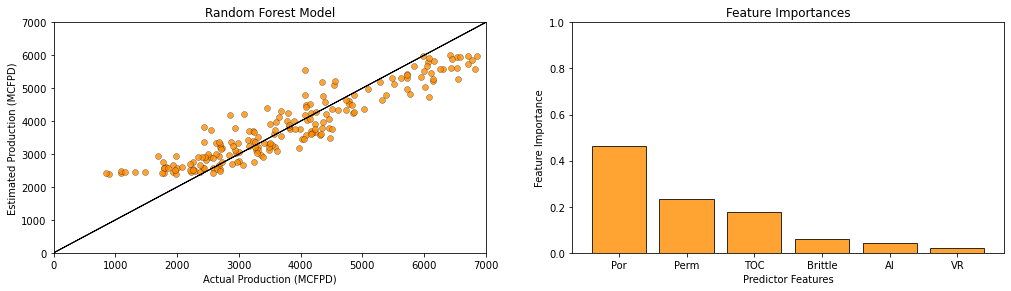
Calculate Shapley Values#
Let’s select some background data at random to calculate local Shapley values and then summarize with global Shapley measures.
Background Samples are selected as a random subset from all the data. Why not just use all the data as background?
Shapley values can be computationally expensive to calculate, we need all the combinations of models to get all the predictions for marginal contributions that are summarized as Shapley values
The original data may be sampled in a biased manner, then we would want to ensure that the background data are representative, i.e., sampled from the original data to reduce bias to avoid bias in our feature importance assessment
Generalization vs. specific prediction cases, if all the data are used as background we get an overall data assessment of feature importance, but we may want to carefully select data to explore specific prediction cases
For simplicity here, we just select randomly selection \(n\) data.
background = shap.sample(x,nsamples=50,random_state=73073)
model_explainer = shap.TreeExplainer(rfr)
shap_values = model_explainer.shap_values(background) # global Shapley Measures
Local Shapley Values#
Let’s start by looking at the local Shapley values to demonstrate the concept of efficiency.
first let’s confirm that the output from the shap function is a \(\left[n_{background}, m\right]\) nd array.
shap_values.shape
(50, 6)
We have the local Shapley values for each prediction for the background cases. Let’s visualize one to demonstrate this.
I coded this custom visualization to clearly communicate local Shapley values and the concept of efficiency.
We start at the average of the training response feature and add the local Shapely values for each predictor feature to reach the prediction.
nback = 7
resp_avg = np.average(Y_hat)
yhat = rfr.predict(background.iloc[[nback]])
current = resp_avg
plt.subplot(111)
plt.plot([current,current],[0,0.3],color='black',lw=2,zorder=1)
plt.plot([current-2,current],[0.2,0.3],color='black',lw=2,zorder=1)
plt.plot([current,current+2],[0.3,0.2],color='black',lw=2,zorder=1)
for i in range(len(pred)+1):
plt.scatter(current,i+0.5,color='grey',edgecolor='black',zorder=10)
if i < len(pred):
if shap_values[nback,i] > 0.0:
color = 'red'
else:
color = 'blue'
plt.plot([current,current + shap_values[nback,i]],[i+1,i+1],color=color,lw=2,zorder=1)
plt.plot([current,current],[i+0.6,i+1],color=color,lw=2,zorder=1)
plt.plot([current + shap_values[nback,i],current + shap_values[nback,i]],[i+1,i+1.3],color=color,lw=2,zorder=1)
plt.plot([current + shap_values[nback,i]-2,current + shap_values[nback,i]],[i+1.2,i+1.3],color=color,lw=2,zorder=1)
plt.plot([current + shap_values[nback,i],current + shap_values[nback,i]+2],[i+1.3,i+1.2],color=color,lw=2,zorder=1)
if shap_values[nback,i] > 0.0:
plt.annotate('+ ' + str(np.round(shap_values[nback,i],0)),[current + shap_values[nback,i]*0.5,i+1.1],ha='center')
else:
plt.annotate('- ' + str(np.round(abs(shap_values[nback,i]),0)),[current + shap_values[nback,i]*0.5,i+1.1],ha='center')
current = current + shap_values[nback,i]
plt.plot([current,current],[i+0.7,i+1],color='black',lw=2,zorder=1)
plt.plot([current-2,current],[i+0.9,i+1],color='black',lw=2,zorder=1)
plt.plot([current,current+2],[i+1,i+0.9],color='black',lw=2,zorder=1)
plt.plot([resp_avg,resp_avg],[-0.5,len(pred)+1.5],color='black',ls='--',zorder=1)
plt.plot([yhat,yhat],[-0.5,len(pred)+1.5],color='black',ls='--',zorder=1)
plt.annotate('Response Feature, Training Average',[resp_avg-8,1.0],rotation=90.0)
plt.annotate('Model Prediction',[yhat-8,1.0],rotation=90.0)
plt.yticks(ticks=np.arange(len(pred)+2), labels=[r'None / $\overline{y}$'] + pred + [r'$\hat{y}=f(X)$'])
add_grid(); plt.ylim([-0.5,len(pred)+1.5])
plt.xlabel('Production (MCFPD)'); plt.ylabel('Feature'); plt.title('Local Shapley Values, Background Index: ' + str(nback))
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.2, top=0.8, wspace=0.2, hspace=0.2); plt.show()
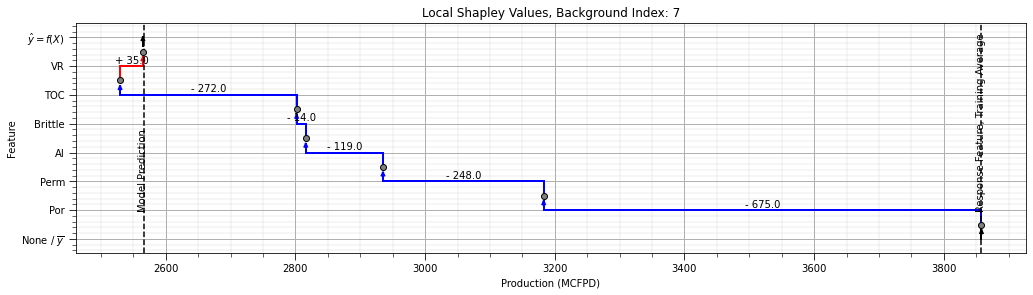
Now I show you the built in plotting methods to communicate the same thing with the shap Python Package.
Shapley Force Plot#
We can simulaneously visualize all of the Shapley values for all of the sample data in the order of the background data set.
blue indicates reduction in the predicted production and red indicates increase in predicted production
We are visualizing over all background sample data at once. Reorder by original sample ordering and select the nback index to compare to the above plot.
shap.force_plot(model_explainer.expected_value,shap_values,background,out_names = ['Production'],feature_names=pred,)
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
Local Force Plot#
We pick a specific sample from the background and visualize the force plot.
We can see the genesis of the plot above, Shapley values for all features given a local set of values in sample \(i\), (\(x_i\)).
Compare this result to the above custom plot that I made and you will see that it communicates the same information.
shap.force_plot(model_explainer.expected_value,shap_values[nback],background.iloc[[nback]],show=False,feature_names = pred)
Have you run `initjs()` in this notebook? If this notebook was from another user you must also trust this notebook (File -> Trust notebook). If you are viewing this notebook on github the Javascript has been stripped for security. If you are using JupyterLab this error is because a JupyterLab extension has not yet been written.
Appreciation to Xuesong Ma for the suggestion to improve the above local Shapley value content and visualizations.
Global Shapley Values#
Let’s review the global Shapley measures.
sorted bar chart of the arithmetic average of the absolute SHAP value over the background data
sorted plot of the SHAP value over the background data
plot of the SHAP value over the background data as a violin plot
Note: all of these methods are applying the global average (\(E[X_i]\)) for each feature to impute for those cases not including feature \(i\).
plt.subplot(131)
shap.summary_plot(show=False,feature_names = pred, shap_values = shap_values, features = background, plot_type="bar",color = "darkorange",cmap = plt.cm.inferno)
plt.ylabel('Predictor Features')
plt.subplot(132)
shap.summary_plot(show=False,feature_names = pred, shap_values = shap_values, features = background,cmap = plt.cm.inferno)
plt.subplot(133)
shap.summary_plot(show=False,feature_names = pred, shap_values = shap_values, features = background,plot_type = "violin")
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.2, top=1.2, wspace=0.2, hspace=0.2)
plt.show()
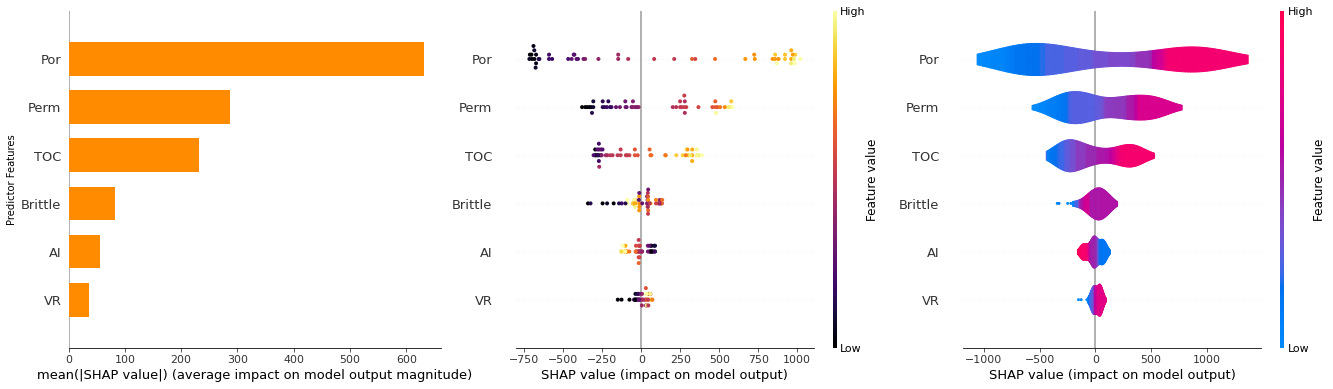
The the center and right plots show the Shapley values for each feature over all the randomly selected background samples, while the plot on the left is the bar chart of the mean absolute Shapley values.
Porosity, Permeability and TOC are the top features
About the Author#

Michael Pyrcz is a professor in the Cockrell School of Engineering, and the Jackson School of Geosciences, at The University of Texas at Austin, where he researches and teaches subsurface, spatial data analytics, geostatistics, and machine learning. Michael is also,
the principal investigator of the Energy Analytics freshmen research initiative and a core faculty in the Machine Learn Laboratory in the College of Natural Sciences, The University of Texas at Austin
an associate editor for Computers and Geosciences, and a board member for Mathematical Geosciences, the International Association for Mathematical Geosciences.
Michael has written over 70 peer-reviewed publications, a Python package for spatial data analytics, co-authored a textbook on spatial data analytics, Geostatistical Reservoir Modeling and author of two recently released e-books, Applied Geostatistics in Python: a Hands-on Guide with GeostatsPy and Applied Machine Learning in Python: a Hands-on Guide with Code.
All of Michael’s university lectures are available on his YouTube Channel with links to 100s of Python interactive dashboards and well-documented workflows in over 40 repositories on his GitHub account, to support any interested students and working professionals with evergreen content. To find out more about Michael’s work and shared educational resources visit his Website.
Want to Work Together?#
I hope this content is helpful to those that want to learn more about subsurface modeling, data analytics and machine learning. Students and working professionals are welcome to participate.
Want to invite me to visit your company for training, mentoring, project review, workflow design and / or consulting? I’d be happy to drop by and work with you!
Interested in partnering, supporting my graduate student research or my Subsurface Data Analytics and Machine Learning consortium (co-PI is Professor John Foster)? My research combines data analytics, stochastic modeling and machine learning theory with practice to develop novel methods and workflows to add value. We are solving challenging subsurface problems!
I can be reached at mpyrcz@austin.utexas.edu.
I’m always happy to discuss,
Michael
Michael Pyrcz, Ph.D., P.Eng. Professor, Cockrell School of Engineering and The Jackson School of Geosciences, The University of Texas at Austin
More Resources Available at: Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Comments#
This was a basic treatment of feature ranking. Much more could be done and discussed, I have many more resources. Check out my shared resource inventory and the YouTube lecture links at the start of this chapter with resource links in the videos’ descriptions.
I hope this is helpful,
Michael