

Bayesian Linear Regression#
Michael J. Pyrcz, Professor, The University of Texas at Austin
Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Chapter of e-book “Applied Machine Learning in Python: a Hands-on Guide with Code”.
Cite this e-Book as:
Pyrcz, M.J., 2024, Applied Machine Learning in Python: A Hands-on Guide with Code [e-book]. Zenodo. doi:10.5281/zenodo.15169138 ![]()
The workflows in this book and more are available here:
Cite the MachineLearningDemos GitHub Repository as:
Pyrcz, M.J., 2024, MachineLearningDemos: Python Machine Learning Demonstration Workflows Repository (0.0.3) [Software]. Zenodo. DOI: 10.5281/zenodo.13835312. GitHub repository: GeostatsGuy/MachineLearningDemos ![]()
By Michael J. Pyrcz
© Copyright 2024.
This chapter is a tutorial for / demonstration of Bayesian Linear Regression.
YouTube Lecture: check out my lectures on:
These lectures are all part of my Machine Learning Course on YouTube with linked well-documented Python workflows and interactive dashboards. My goal is to share accessible, actionable, and repeatable educational content. If you want to know about my motivation, check out Michael’s Story.
Motivations for Bayesian Linear Regression#
Bayesian machine learning methods apply probability to make predictions with an intrinsic uncertainty model. In addition, the Bayesian methods integrate the concept of Bayesian updating, a prior model updated with a likelihood model from data to calculate a posterior model.
There are additional complexities with model training due to working with these probabilities, represented by continuous probability density functions. Due to the resulting high complexity, we can’t solve for the model parameters directly, instead we must apply a sampling method such as Markov Chain Monte Carlo (MCMC) simulation.
This is a simple, very accessible demonstration of Bayesian linear regression with McMC Metropolis-Hastings sampling. My students struggled with these concepts so I challenged myself to built a workflow from scratch with all details explained clearly. Let’s explain the critical prerequisites, starting with Bayesian updating.
Linear Regression#
Let’s start by recalling the salient points for linear regression for prediction, let’s start by looking at a linear model fit to a set of data.
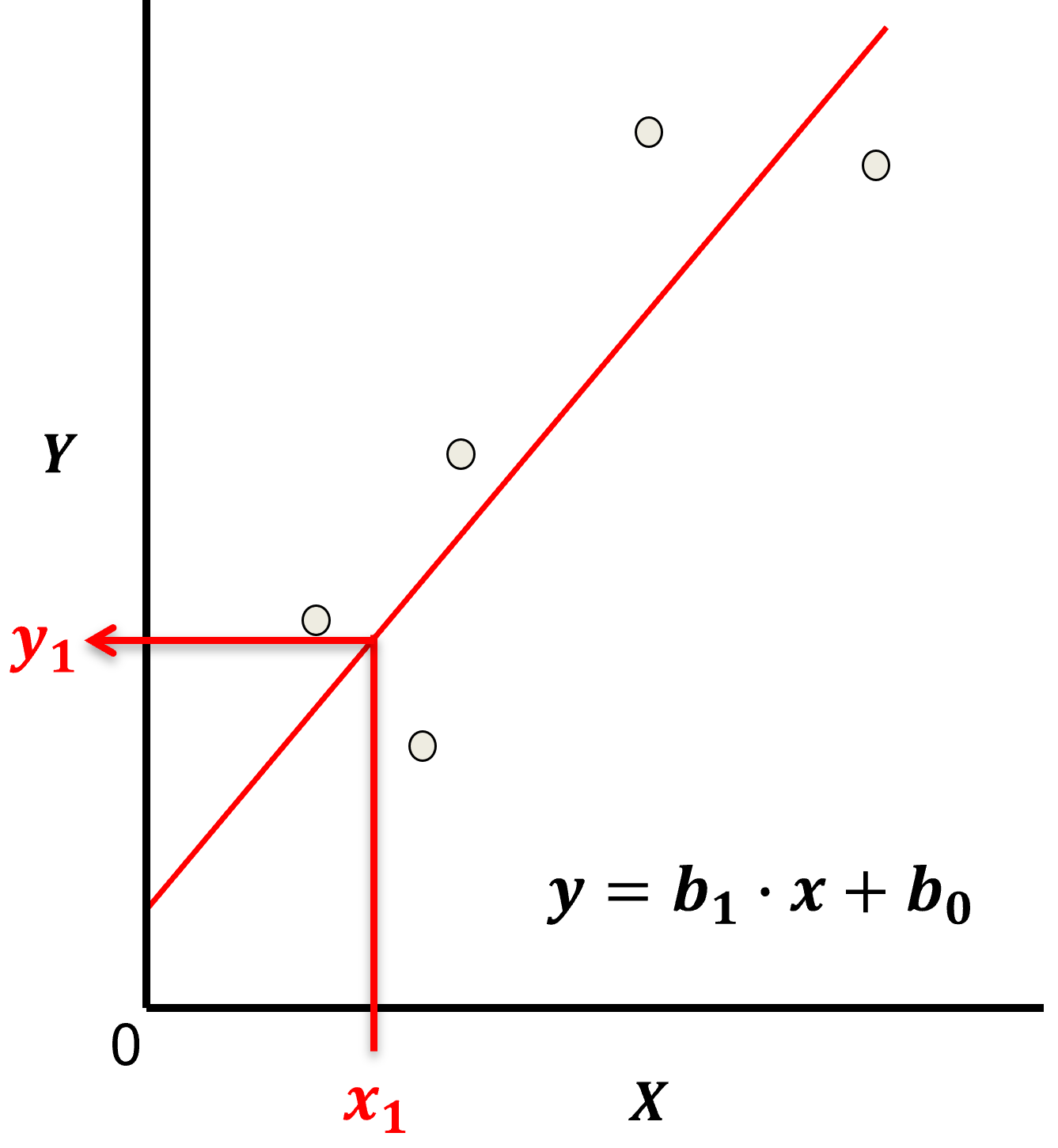
Parametric Model
This is a parametric predictive machine learning model, we accept an a prior assumption of linearity and then gain a very low parametric representation that is easy to train without a onerous amount of data.
the fit model is a simple weighted linear additive model based on all the available features, \(x_1,\ldots,x_m\).
the parametric model takes the form of:
Here’s the visualization of the linear model parameters,
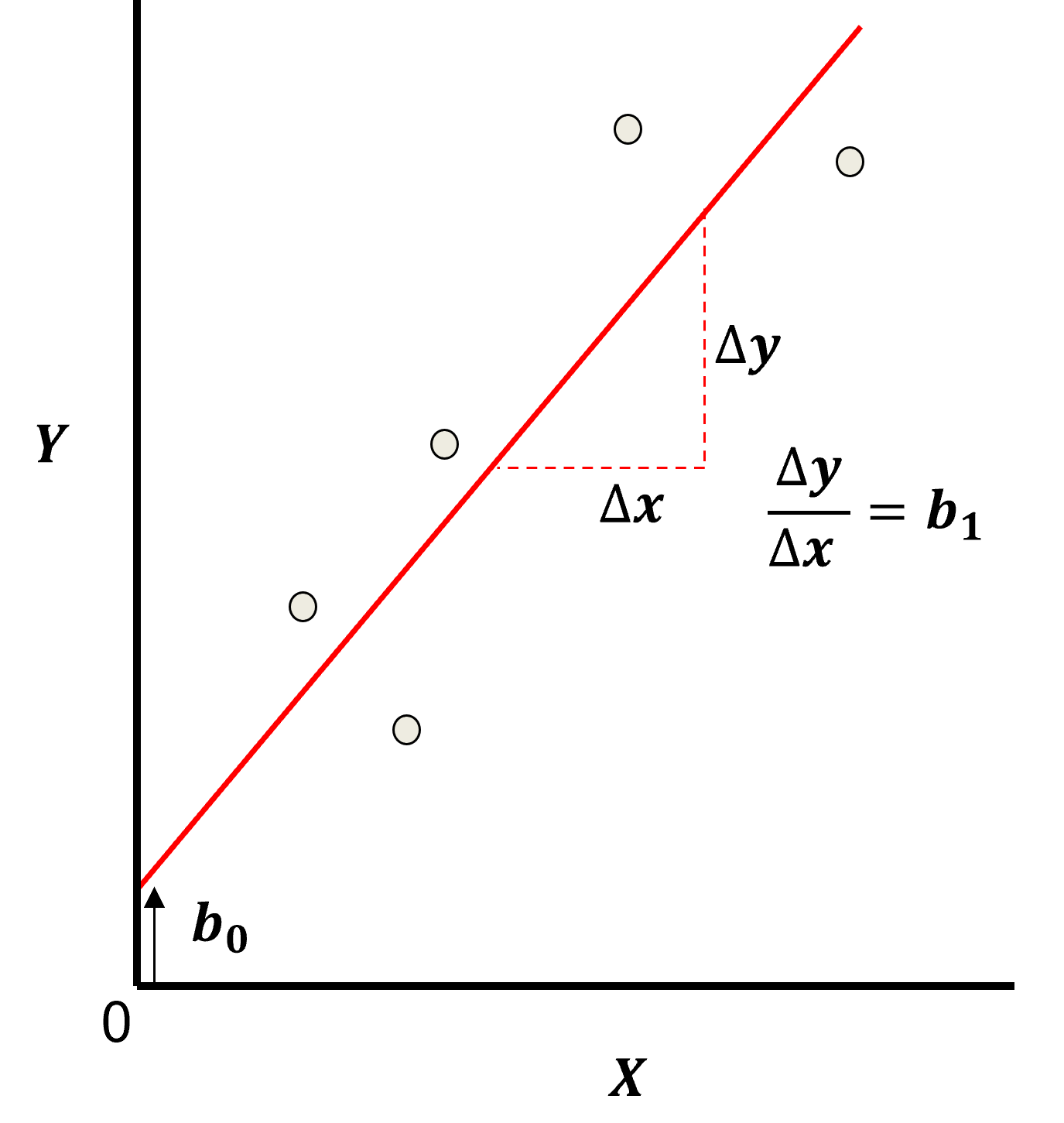
Least Squares
The analytical solution for the model parameters, \(b_1,\ldots,b_m,b_0\), is available for the L2 norm loss function, the errors are summed and squared known a least squares.
we minimize the error, residual sum of squares (RSS) over the training data:
where \(y_i\) is the actual response feature values and \(\sum_{\alpha = 1}^m b_{\alpha} x_{\alpha} + b_0\) are the model predictions, over the \(\alpha = 1,\ldots,n\) training data.
Here’s a visualization of the L2 norm loss function, MSE,
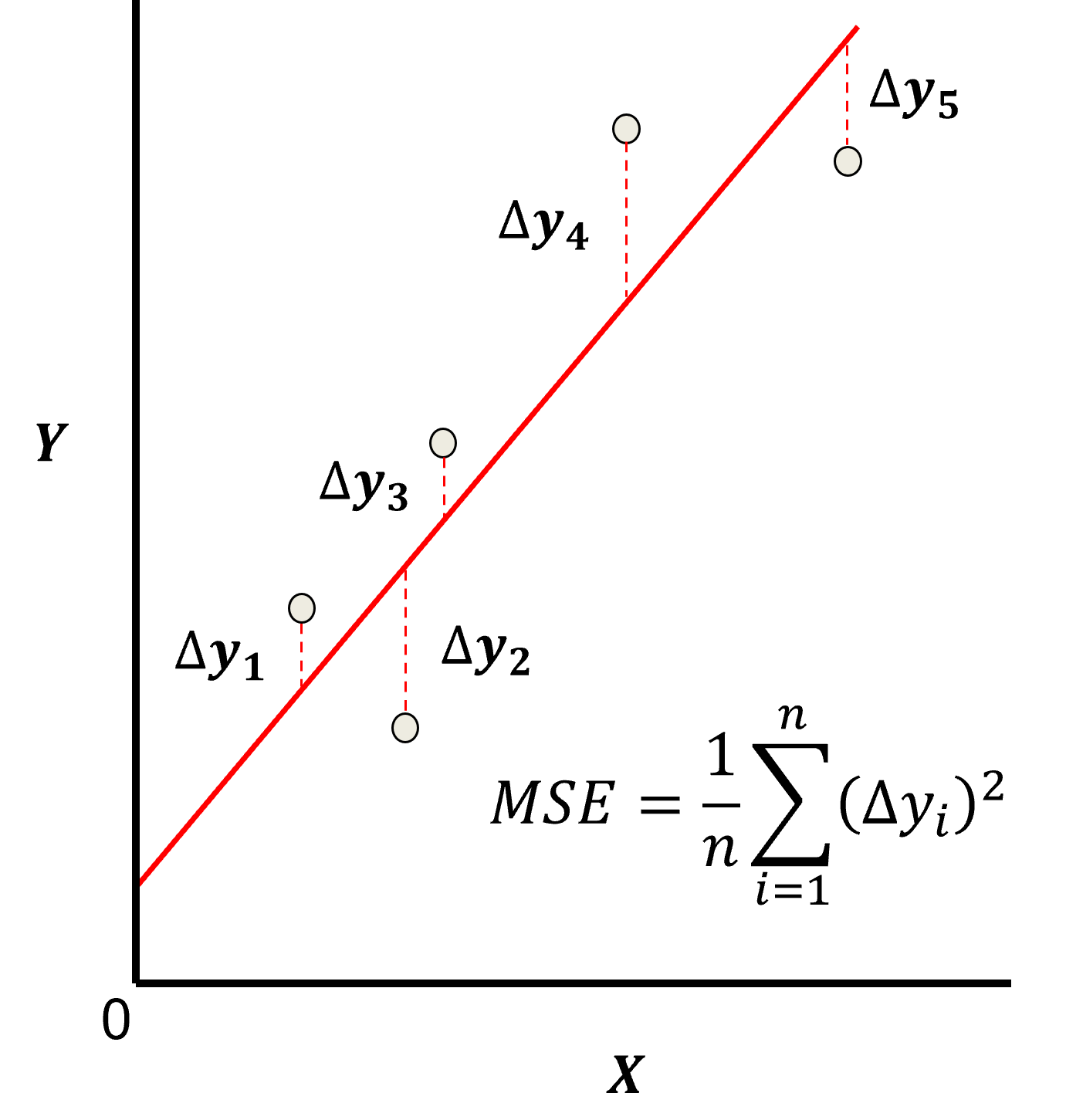
this may be simplified as the sum of square error over the training data,
\begin{equation} \sum_{i=1}^n (\Delta y_i)^2 \end{equation}
where \(\Delta y_i\) is actual response feature observation \(y_i\) minus the model prediction \(\sum_{\alpha = 1}^m b_{\alpha} x_{\alpha} + b_0\), over the \(i = 1,\ldots,n\) training data.
Assumptions
There are important assumption with our linear regression model,
Error-free - predictor variables are error free, not random variables
Linearity - response is linear combination of feature(s)
Constant Variance - error in response is constant over predictor(s) value
Independence of Error - error in response are uncorrelated with each other
No multicollinearity - none of the features are redundant with other features
Now’s let’s recall Bayesian updating and then update our linear regression model to Bayesian linear regression.
Bayesian Updating#
The Bayesian approach for probabilities is based on a degree of belief (expert experience) in an event updated as new information is available
this approach to probability is powerful and can be applied to solve problems that we cannot be solved with the frequentist approach to probability
Bayesian updating is represented by Bayes’ Theorem,
where \(P(A)\) is the prior, \(P(B|A)\) is the likelihood, \(P(B)\) is the evidence term that is responsible for probability closure, and \(P(A|B)\) is the posterior.
Bayesian Linear Regression#
The frequentist formulation of the linear regression model is,
where \(x\) is the predictor feature, \(b_1\) is the slope parameter, \(b_0\) is the intercept parameter and \(\sigma\) is the error or noise. There is an analytical form for the ordinary least squares solution to fit the available data while minimizing the L2 norm of the data error vector.
We can represent the multilinear regression model with matrix notation as,
where \(\beta\) is a vector of model parameters, \(\beta_1,\ldots,\beta_m\). We can add another term \(\beta_0\) to the vector for the model intercept.
when \(\beta_0\) is added, we also add a column of \(1\)s to the data \(X\) matrix
For the Bayesian formulation of linear regression is we pose the model as a prediction of the distribution of the response, \(Y\), now a random variable:
We estimate the model parameter distributions through Bayesian updating for inferring the model parameters from a prior and likelihood from training data.
Let’s talk about each term,
Prior, \(𝑃(\beta)\) - initial, prior to new data, inference of the model parameters over the predictor features based on,
expert knowledge
naïve prior, in the case of non-informative priors the likelihood will dominate
informative prior, in the case of a low uncertainty prior the prior will dominate the likelihood
cannot include the new training data, prior to integration of the training data
Likelihood, \(𝑃(𝑦,𝑋│\beta)\) - conditional distribution of the training data given assumed model parameters based on,
the new data, data-driven
as the number of sample data increases the likelihood overwhelms the prior distribution
Evidence, \(P(y,X)\) - normalization constant to ensure probability closure, i.e., a valid posterior probability density function
independent of the model parameters
solved by marginalization of the numerator, collapses by integrating over all possible model parameters
for some solution methods, e.g., MCMC Metropolis-Hastings the evidence term cancels out
Posterior, \(P(\beta│y,X)\) - conditional distribution of the model parameters given the data-driven likelihood and prior based on expert knowledge and belief
as the number of data, \(𝑛 \rightarrow \infty\), the model parameters, \(\beta\), converge to ordinary least squares linear regression, the prior is overwhelmed by the data.
In general for continuous features we are not able to directly calculate the posterior and we must use a sampling method, such as Markov chain Monte Carlo (McMC) to sample the posterior.
Here’s a McMC Metropolis Hastings workflow and more details.
Markov Chain Monte Carlo (MCMC)#
Is a set of algorithms to sample from a probability distribution such that the samples match the distribution statistics.
Markov - screening assumption, the next sample is only dependent on the previous sample
Chain - the samples form a sequence often demonstrating a transition from burn-in chain with inaccurate statistics and equilibrium chain with accurate statistics
Monte Carlo - use of Monte Carlo simulation, random sampling from a statistical distribution
Why is this useful?
we often don’t have the target distribution, it is unknown
but we can sample with the correct frequencies with other form of information such as conditional probability density functions
Bayesian Linear Regression with the Metropolis-Hastings Sampler#
Here’s the basic steps of the Metropolis-Hastings MCMC Sampler:
For \(\ell = 1, \ldots, L\):
Assign random values for the initial sample of model parameters, \(\beta(\ell = 1) = b_1(\ell = 1)\), \(b_0(\ell = 1)\) and \(\sigma^2(\ell = 1)\).
Propose new model parameters based on a proposal function, \(\beta^{\prime} = b_1\), \(b_0\) and \(\sigma^2\).
Calculate probability of acceptance of the new proposal, as the ratio of the posterior probability of the new model parameters given the data to the previous model parameters given the data multiplied by the probability of the old step given the new step divided by the probability of the new step given the old.
Apply Monte Carlo simulation to conditionally accept the proposal, if accepted, \(\ell = \ell + 1\), and sample \(\beta(\ell) = \beta^{\prime}\)
Go to step 2.
Let’s talk about this system. First the left hand side:
We are calculating the ratio of the posterior probability (likelihood times prior) of the model parameters given the data and prior model for proposed sample over the current sample.
As you will see below it is quite practical to calculate this ratio.
If the proposed sampled is more likely than the current sample, we will have a value greater than 1.0, it will truncate to 1.0 and we accept the proposed sample.
If the proposed sample is less likely than the current sample, we will have a value less than 1.0, then we will use Monte Carlo sampling to randomly choice the proposed sample with this probability of acceptance.
This procedure allows us to walk through the model parameter space and sample the parameters with the current rates, after the burn-in chain.
Now, what about this part of the equation?
There is a problem with this procedure if we use asymmetric probability distributions for the model parameters!
E.g. for example, if we use a positively skewed distribution (e.g., log normal) then we are more likely to step to larger values due to this distribution, and not due to the prior nor the likelihood.
This term removes this bias, so that we have fair samples!
You will see below that we remove this issue by assuming symmetric model parameter distributions, even though many use an asymmetric gamma distribution for sigma, given it cannot have negative values.
My goal is the simplest possible demonstration.
Our Simplified Demonstration Metropolis Sampling#
Let’s further specify this workflow for our simple demonstration.
I have assumed a Gaussian, symmetric distribution for all model parameters as a result this relationship holds for all possible model parameter, current and proposed.
So we now have this simplified probability of proposal acceptance, note this is know as Metropolis Sampling.
Now, let’s substitute our Bayesian formulation for our Bayesian linear regression model.
If we substitute these into our probability of acceptance above we get this.
Note that the evidence terms cancel out.
Since we are working with a likelihood ratio, we can work with densities instead of probabilities.
Finally for improved solution stability we can calculate the natural log ratio:
We calculate probability of proposal acceptance, as exponentiation of the above.
How do we calculate the likelihood density? If we assume independence between all of the data we can take the product sum of the probabilities (densities) of all the response values given the predictor and model parameter sample! Given, the Gaussian assumption for the response feature, we can calculate the densities for each data from the Gaussian PDF.
and under the assumption of independence we can take the produce sum over all training data.
Note, this workflow was developed with assistance from Fortunato Nucera’s Medium Article Mastering Bayesian Linear Regression from Scratch: A Metropolis-Hastings Implementation in Python. I highly recommend this accessible description and demonstration. Thank you, Fortunato.
Load the Required Libraries#
We will also need some standard packages. These should have been installed with Anaconda 3.
%matplotlib inline
suppress_warnings = True
import os # to set current working directory
import math # square root operator
import numpy as np # arrays and matrix math
import scipy.stats as stats # statistical methods
import pandas as pd # DataFrames
import pandas.plotting as pd_plot
import matplotlib.pyplot as plt # for plotting
from matplotlib.patches import Rectangle # build a custom legend
from matplotlib.ticker import (MultipleLocator,AutoMinorLocator,FuncFormatter) # control of axes ticks
from matplotlib.colors import ListedColormap # custom color maps
import seaborn as sns # for matrix scatter plots
from sklearn.linear_model import LinearRegression # frequentist model for comparison
from IPython.display import display, HTML # custom displays
cmap = plt.cm.inferno # default color bar, no bias and friendly for color vision defeciency
plt.rc('axes', axisbelow=True) # grid behind plotting elements
if suppress_warnings == True:
import warnings # suppress any warnings for this demonstration
warnings.filterwarnings('ignore')
seed = 13 # random number seed for workflow repeatability
If you get a package import error, you may have to first install some of these packages. This can usually be accomplished by opening up a command window on Windows and then typing ‘python -m pip install [package-name]’. More assistance is available with the respective package docs.
Declare Functions#
The following functions include:
next_proposal - propose a next model parameters from previous model parameters, this is the proposal method, parameterized by step standard deviation and Gaussian distribution.
likelihood_density - calculate the product of all the densities for all the data given the model parameters. Since we are working with the log densities, we sum over all the data.
prior_density - calculate the product of the densities for all the model parameters given the prior model. Since we are working with the log densities, we sum over all the model parameters. This is an assumption of independence.
add_grid - improved grid for the plotting.
def next_proposal(prev_theta, step_stdev = 0.5): # assuming a Gaussian distribution centered on previous theta and step stdev
out_theta = stats.multivariate_normal(mean=prev_theta,cov=np.eye(3)*step_stdev**2).rvs(1)
return out_theta
def likelihood_density(x,y,theta): # likelihood - probability (density) of the data given the model
density = np.sum(stats.norm.logpdf(y, loc=theta[0]*x+theta[1],scale=theta[2])) # assume independence, sum is product in log space
return density
def prior_density(theta,prior): # prior - probability (density) of the model parameters given the prior
mean = np.array([prior[0,0],prior[1,0],prior[2,0]]); cov = np.zeros([3,3]); cov[0,0] = prior[0,1]; cov[1,1] = prior[1,1]; cov[2,2] = prior[2,1]
prior_out = stats.multivariate_normal.logpdf(theta,mean=mean,cov=cov,allow_singular=True)
return prior_out
def add_grid():
plt.gca().grid(True, which='major',linewidth = 1.0); plt.gca().grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
Set the Working Directory#
I always like to do this so I don’t lose files and to simplify subsequent read and writes (avoid including the full address each time).
#os.chdir("c:/PGE383") # set the working directory
Build a Synthetic Dataset with Known Truth Linear Regression Model Parameters#
Let’s build a simple dataset with known linear regression model parameters, \(b_1\) is the slope parameter, \(b_0\) is the intercept parameter and \(\sigma\) is the error or noise.
we build the data based on these parameters, and then we train a linear regression model and show that we get the correct slope and intercept model parameters.
np.random.seed(seed = seed) # set random number seed
data_b1 = 3; data_b0 = 20; data_sigma = 5; n = 100 # set data model parameters
X = np.random.rand(n)*30 # random x values
y = data_b1*X+data_b0 + np.random.normal(loc=0.0,scale=data_sigma,size=n) # y as a linear function of x + random noise
Xname = [r'$X_1$']; yname = [r'$y$'] # specify the predictor features (x2) and response feature (x1)
Xmin = 0.0; Xmax = 30; ymin = 0.0; ymax = 120 # set minimums and maximums for visualization
Xunit = ['none']; yunit = ['none']
Xlabelunit = Xname[0] + ' (' + Xunit[0] + ')'
ylabelunit = yname[0] + ' (' + yunit[0] + ')'
xhat = np.linspace(Xmin,Xmax,100) # set of x values to predict and visualize the model
linear_model = LinearRegression().fit(X.reshape(-1, 1),y) # instantiate and train the frequentist linear regression model
yhat = linear_model.predict(xhat.reshape(-1, 1)) # make predictions for model plotting
slope = linear_model.coef_[0]
intercept = linear_model.intercept_
plt.subplot(111) # plot the data and model
plt.scatter(X, y,c='red',s=10,edgecolor='black')
plt.plot(xhat,yhat,c='red'); add_grid()
plt.title('Linear Regression Model, Regression of ' + yname[0] + ' on ' + Xname[0])
plt.xlabel(Xlabelunit); plt.ylabel(ylabelunit)
add_grid(); plt.xlim([Xmin,Xmax]); plt.ylim([ymin,ymax])
plt.annotate('Linear Regression Model',[18.0,38])
plt.annotate(r' $\beta_1$ :' + str(round(slope,2)),[16.0,30])
plt.annotate(r' $\beta_0$ :' + str(round(intercept,2)),[16.0,20])
plt.annotate(r'$N[\phi] = \beta_1 \times z + \beta_0$',[21.0,30])
plt.annotate(r'$N[\phi] = $' + str(round(slope,2)) + r' $\times$ $z$ + (' + str(round(intercept,2)) + ')',[21.0,20])
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.0, wspace=0.2, hspace=0.2); plt.show()
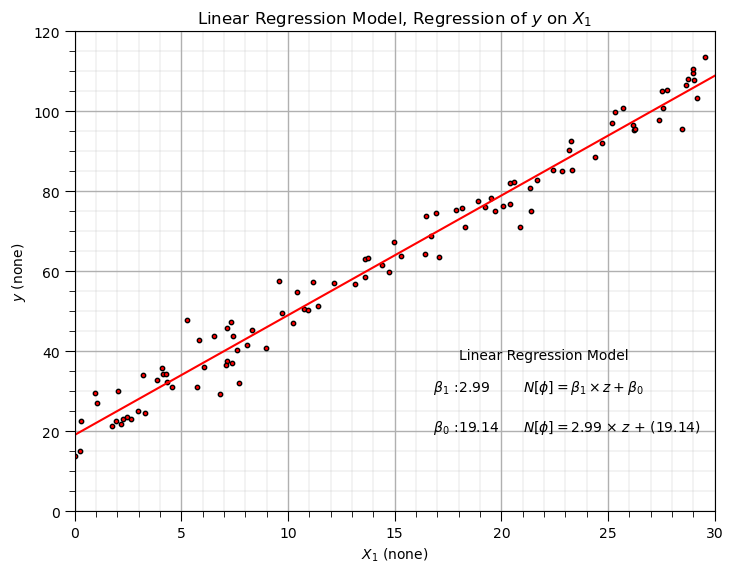
The linear regression model parameters are quite close to the coefficients used to make the synthetic data. Now let’s train an Bayesian linear regression model with MCMC.
Bayesian Linear Regression#
It all begins with a prior model, for that we assume a reasonable prior model.
Assume the Prior Model#
We assume a multivariate Gaussian distribution for the slope and intercept parameters, \(f_{b_1,b_0,\sigma}(b_1,b_0,\sigma)\) with independence between \(b_1\), \(b_0\), and \(\sigma\).
For a naive prior assume a very large standard deviation. We will work in log probability and log density to improve stability of the system.
We want to avoid product sums of a many values near zero as the probabilities will disappear due to computer floating point precision.
In log space, we can add calculate probabilities of independent events by summing (instead of multiplication) these negative values
prior = np.zeros([3,2]) # prior distributions
prior[0,:] = [5.0,1.0] # Gaussian prior model for slope, mean and standard deviation
prior[1,:] = [18.0,2.0] # Gaussian prior model for intercept, mean and standard deviation
prior[2,:] = [7.0,1.0] # Gaussian prior model for sigma, k (shape) and phi (scale), recall mean = k x phi, var = k x phi^2
plt.subplot(131) # slope prior distribution
plt.plot(np.arange(0,10,0.01),stats.norm.logpdf(np.arange(0,10,0.01),loc=prior[0,0],scale=prior[0,1]),c='red'); ylim = plt.gca().get_ylim()
plt.fill_between(np.arange(0,10,0.01),np.full(1000,-1.0e20),stats.norm.logpdf(np.arange(0,10,0.01),loc=prior[0,0],scale=prior[0,1]),color='black',alpha=0.05,zorder=1)
plt.xlabel(r'$b_1$'); plt.ylabel('Natural Log Density'); plt.title("Gaussian Prior Distribution, $b_1$"); add_grid(); plt.xlim([0,10]); plt.ylim(ylim)
plt.subplot(132) # intercept prior distribution
plt.plot(np.arange(0,100,0.01),stats.norm.logpdf(np.arange(0,100,0.01),loc=prior[1,0],scale=prior[1,1]),c='red'); ylim = plt.gca().get_ylim()
plt.fill_between(np.arange(0,100,0.01),np.full(10000,-1.0e20),stats.norm.logpdf(np.arange(0,100,0.01),loc=prior[1,0],scale=prior[1,1]),color='black',alpha=0.05,zorder=1)
plt.xlabel(r'$b_0$'); plt.ylabel('Natural Log Density'); plt.title("Gaussian Prior Distribution, $b_1$"); add_grid(); plt.xlim([0,100]); plt.ylim(ylim)
plt.subplot(133) # noise prior distribution
plt.plot(np.arange(0,10,0.01),stats.norm.logpdf(np.arange(0,10,0.01),loc=prior[2,0],scale=prior[2,1]),c='red'); ylim = plt.gca().get_ylim()
plt.fill_between(np.arange(0,10,0.01),np.full(1000,-1.0e20),stats.norm.logpdf(np.arange(0,10,0.01),loc=prior[2,0],scale=prior[2,1]),color='black',alpha=0.05,zorder=1)
plt.xlabel(r'$\sigma$'); plt.ylabel('Natural Log Density'); plt.title("Gamma Prior Distribution, $\sigma$"); add_grid(); plt.xlim([0,10]); plt.ylim(ylim)
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.5, top=0.8, wspace=0.35, hspace=0.5); plt.show()
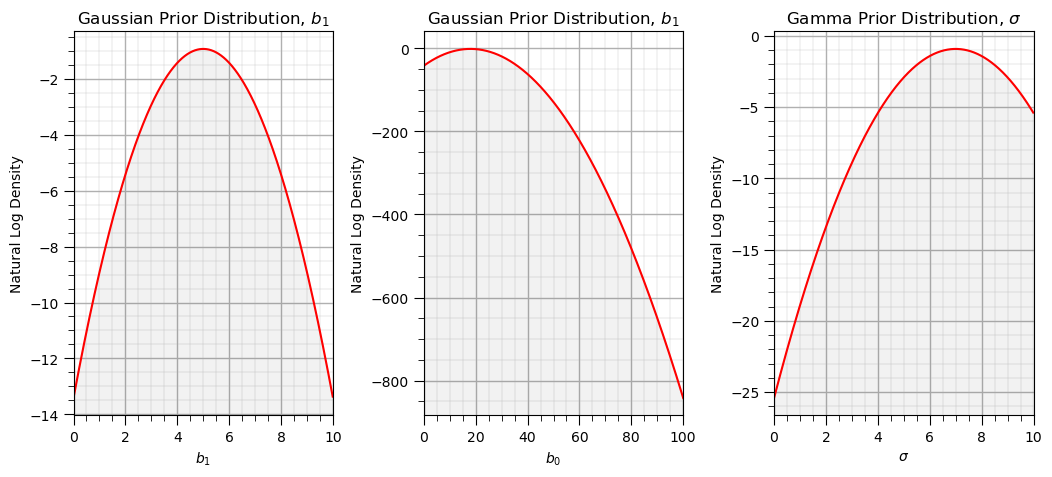
Bayesian Linear Regression with MCMC Metropolis-Hastings#
The Bayesian linear regression with MCMC Metropolis-Hastings workflow.
assign an random initial set of model parameters
apply a proposal rule to assign a new set of model parameters given the previous set of model parameters
calculate the ratio of the likelihood of the new model parameters over the previous model parameters given the data
conditionally accept the proposal based on this ratio, i.e., if proposal is more like accept it, if less likely with a probability based on the ratio.
return to step 2.
np.random.seed(seed = seed)
step_stdev = 0.2
thetas = np.random.rand(3).reshape(1,-1) # seed a random first step
accepted = 0
n = 10000 # number of attempts, include accepted and rejected
for i in range(n):
theta_new = next_proposal(thetas[-1,:],step_stdev=step_stdev) # next proposal
log_like_new = likelihood_density(X,y,theta_new) # new and prior likelihoods, log of density
log_like = likelihood_density(X,y,thetas[-1,:])
log_prior_new = prior_density(theta_new,prior) # new and prior, log of density
log_prior = prior_density(thetas[-1,:],prior)
likelihood_prior_proposal_ratio = np.exp((log_like_new + log_prior_new) - (log_like + log_prior)) # calculate log ratio
if likelihood_prior_proposal_ratio > np.random.rand(1): # conditionally accept by likelihood ratio
thetas = np.vstack((thetas,theta_new)); accepted += 1
print('Accepted ' + str(accepted) + ' samples of ' + str(n) + ' attempts')
df = pd.DataFrame(np.vstack([thetas[:,0],thetas[:,1],thetas[:,2]]).T, columns= ['Slope','Intercept','Sigma'])
Accepted 1603 samples of 10000 attempts
Visualize the Results#
Let’s visualize the McMC Metropolis sample chain for each of the model parameters.
Note the burn-in and equilibrium chains.
Compare the slope and intercept model parameters to the frequentist, linear regression solution, based only on the ordinary least squares solution, minimizing the L2 norm of the error vector over all sample data.
Compare the noise parameter to the noise added to the synthetic data.
alpha = 0.1 # alpha level for displayed confidence intervals
plt.subplot(131) # plot slope, b_1, samples
plt.plot(np.arange(0,accepted+1,1),thetas[:,0],c='red',zorder=100)
plt.xlabel('McMC Metropolis Sample'); plt.ylabel(r'$b_1$'); plt.title("McMC Bayesian Linear Regression Slope"); add_grid()
plt.plot([0,accepted],[linear_model.coef_[0],linear_model.coef_[0]],c='blue',zorder=200)
plt.annotate('Linear Regression',[30,linear_model.coef_[0]+0.05],color='blue',zorder=200)
plt.plot([0,accepted],[prior[0,0],prior[0,0]],c='black',zorder=10)
plt.annotate('Prior Model [P' + str((int(alpha/2*100))) + ',P' + str((int((1.0-alpha/2)*100))) + ']',[30,prior[0,0]+0.07])
lower = stats.norm.ppf(alpha/2.0,loc=prior[0,0],scale=prior[0,1])
plt.plot([0,accepted],[lower,lower],c='black',ls='--',zorder=10)
upper = stats.norm.ppf(1-alpha/2.0,loc=prior[0,0],scale=prior[0,1])
plt.plot([0,accepted],[upper,upper],c='black',ls='--',zorder=10)
plt.fill_between([0,accepted],[lower,lower],[upper,upper],color='black',alpha=0.05,zorder=1)
plt.xlim([0,accepted]); plt.ylim([0,10])
plt.subplot(132) # plot intercept, b_0, samples
plt.plot(np.arange(0,accepted+1,1),thetas[:,1],c='red',zorder=100)
plt.xlabel('McMC Metropolis Sample'); plt.ylabel(r'$b_0$'); plt.title("McMC Bayesian Linear Regression Intercept"); add_grid()
plt.plot([0,accepted],[linear_model.intercept_,linear_model.intercept_],c='blue',zorder=200)
plt.annotate('Linear Regression',[30,linear_model.intercept_+0.25],color='blue',zorder=200)
plt.plot([0,accepted],[prior[1,0],prior[1,0]],c='black',zorder=10)
plt.annotate('Prior Model [P' + str((int(alpha/2*100))) + ',P' + str((int((1.0-alpha/2)*100))) + ']',[30,prior[1,0]+0.07])
lower = stats.norm.ppf(alpha/2.0,loc=prior[1,0],scale=prior[1,1])
plt.plot([0,accepted],[lower,lower],c='black',ls='--',zorder=10)
upper = stats.norm.ppf(1-alpha/2.0,loc=prior[1,0],scale=prior[1,1])
plt.plot([0,accepted],[upper,upper],c='black',ls='--',zorder=10)
plt.fill_between([0,accepted],[lower,lower],[upper,upper],color='black',alpha=0.05,zorder=1)
plt.xlim([0,accepted]); plt.ylim([0,30])
plt.subplot(133) # plot noise, sigma, samples
plt.plot(np.arange(0,accepted+1,1),thetas[:,2],c='red',zorder=100)
plt.xlabel('McMC Metropolis Sample'); plt.ylabel(r'$\sigma$'); plt.title("McMC Bayesian Linear Regression Sigma"); add_grid()
plt.plot([0,accepted],[data_sigma,data_sigma],color='blue',zorder=200)
plt.annotate('Synthetic Data Noise',[30,data_sigma+0.06],color='blue',zorder=200)
plt.plot([0,accepted],[prior[2,0],prior[2,0]],c='black',zorder=10)
plt.annotate('Prior Model [P' + str((int(alpha/2*100))) + ',P' + str((int((1.0-alpha/2)*100))) + ']',[30,prior[2,0]+0.07])
lower = stats.norm.ppf(alpha/2.0,loc=prior[2,0],scale=prior[2,1])
plt.plot([0,accepted],[lower,lower],c='black',ls='--',zorder=10)
upper = stats.norm.ppf(1-alpha/2.0,loc=prior[2,0],scale=prior[2,1])
plt.plot([0,accepted],[upper,upper],c='black',ls='--',zorder=10)
plt.fill_between([0,accepted],[lower,lower],[upper,upper],color='black',alpha=0.05,zorder=1)
plt.xlim([0,accepted]); plt.ylim([0,10])
plt.subplots_adjust(left=0.0, bottom=0.0, right=3.0, top=1.2, wspace=0.2, hspace=0.5); plt.show()
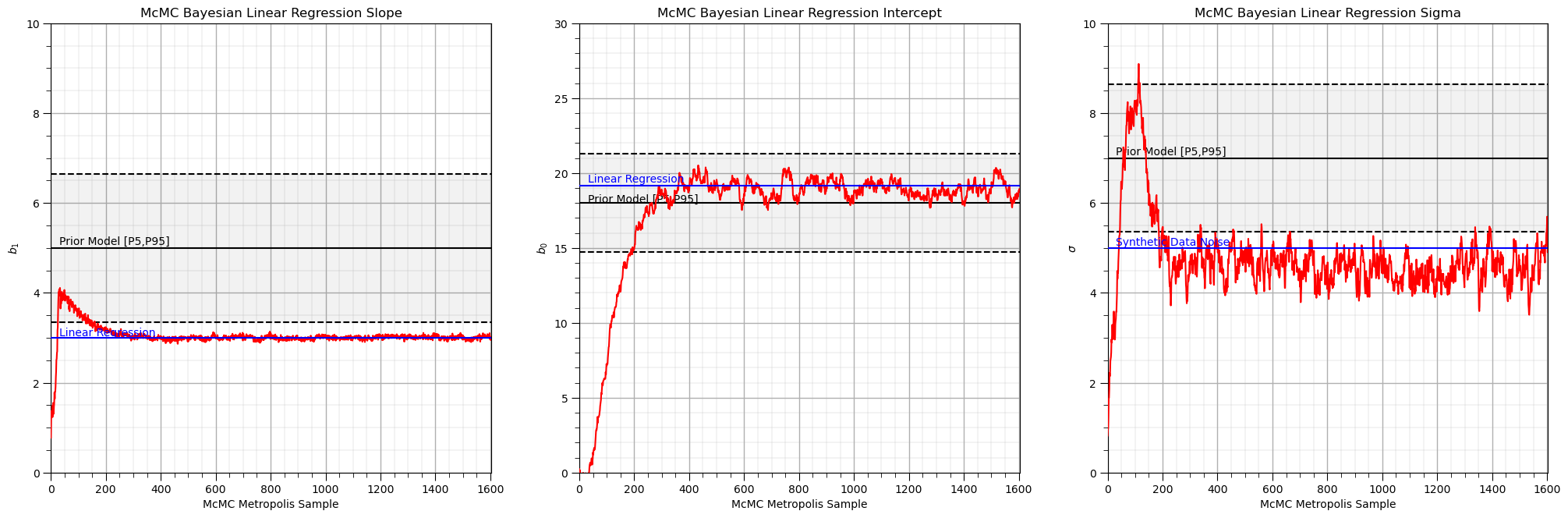
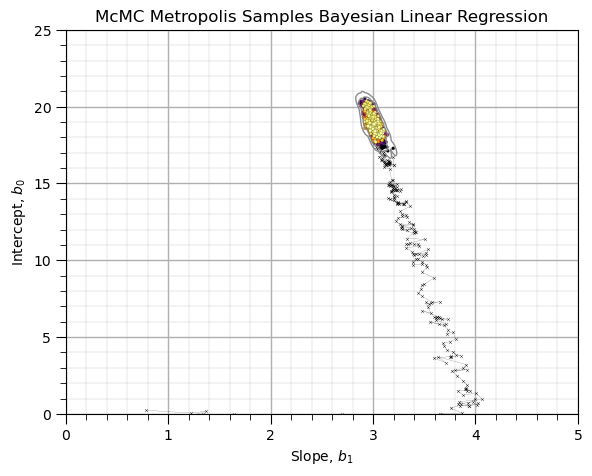
Visualize the Chain in the Model Parameter Space#
Set the burn-in chain as the accepted sample at the end of the burn in chain and observed the McMC sampling.
burn_chain = 250
plt.scatter(thetas[:burn_chain,0],thetas[:burn_chain,1],s=5,marker = 'x',c='black',alpha=0.8,linewidth=0.3,cmap=plt.cm.inferno,zorder=10)
plt.scatter(thetas[burn_chain:,0],thetas[burn_chain:,1],s=5,c=np.arange(burn_chain,accepted+1,1),alpha=1.0,edgecolor='black',linewidth=0.1,cmap=plt.cm.inferno,zorder=10)
sns.kdeplot(data=df[burn_chain:],x='Slope',y='Intercept',color='grey',linewidths=1.00,alpha=0.9,levels=np.logspace(-4,-0,3),zorder=100)
plt.plot(thetas[:burn_chain,0],thetas[:burn_chain,1],color='black',linewidth=0.1,zorder=1)
add_grid(); plt.xlabel('Slope, $b_1$'); plt.ylabel('Intercept, $b_0$'); plt.title('McMC Metropolis Samples Bayesian Linear Regression')
plt.xlim([0,5]); plt.ylim([0,25])
plt.subplots_adjust(left=0.0, bottom=0.0, right=0.8, top=0.8, wspace=0.2, hspace=0.5); plt.show()
About the Author#

Michael Pyrcz is a professor in the Cockrell School of Engineering, and the Jackson School of Geosciences, at The University of Texas at Austin, where he researches and teaches subsurface, spatial data analytics, geostatistics, and machine learning. Michael is also,
the principal investigator of the Energy Analytics freshmen research initiative and a core faculty in the Machine Learn Laboratory in the College of Natural Sciences, The University of Texas at Austin
an associate editor for Computers and Geosciences, and a board member for Mathematical Geosciences, the International Association for Mathematical Geosciences.
Michael has written over 70 peer-reviewed publications, a Python package for spatial data analytics, co-authored a textbook on spatial data analytics, Geostatistical Reservoir Modeling and author of two recently released e-books, Applied Geostatistics in Python: a Hands-on Guide with GeostatsPy and Applied Machine Learning in Python: a Hands-on Guide with Code.
All of Michael’s university lectures are available on his YouTube Channel with links to 100s of Python interactive dashboards and well-documented workflows in over 40 repositories on his GitHub account, to support any interested students and working professionals with evergreen content. To find out more about Michael’s work and shared educational resources visit his Website.
Want to Work Together?#
I hope this content is helpful to those that want to learn more about subsurface modeling, data analytics and machine learning. Students and working professionals are welcome to participate.
Want to invite me to visit your company for training, mentoring, project review, workflow design and / or consulting? I’d be happy to drop by and work with you!
Interested in partnering, supporting my graduate student research or my Subsurface Data Analytics and Machine Learning consortium (co-PI is Professor John Foster)? My research combines data analytics, stochastic modeling and machine learning theory with practice to develop novel methods and workflows to add value. We are solving challenging subsurface problems!
I can be reached at mpyrcz@austin.utexas.edu.
I’m always happy to discuss,
Michael
Michael Pyrcz, Ph.D., P.Eng. Professor, Cockrell School of Engineering and The Jackson School of Geosciences, The University of Texas at Austin
More Resources Available at: Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Comments#
This was a basic treatment of Bayesian linear regression. Much more could be done and discussed, I have many more resources. Check out my shared resource inventory and the YouTube lecture links at the start of this chapter with resource links in the videos’ descriptions.
I hope this is helpful,
Michael