
Machine Learning Workflow Construction and Coding#
Michael J. Pyrcz, Professor, The University of Texas at Austin
Twitter | GitHub | Website | GoogleScholar | Book | YouTube | Applied Geostats in Python e-book | LinkedIn
Chapter of e-book “Applied Machine Learning in Python: a Hands-on Guide with Code”.
Cite this e-Book as:
Pyrcz, M.J., 2024, Applied Machine Learning in Python: a Hands-on Guide with Code, https://geostatsguy.github.io/MachineLearningDemos_Book.
The workflows in this book and more are available here:
Cite the MachineLearningDemos GitHub Repository as:
Pyrcz, M.J., 2024, MachineLearningDemos: Python Machine Learning Demonstration Workflows Repository (0.0.1). Zenodo. ![]()
By Michael J. Pyrcz
© Copyright 2024.
This chapter is a summary of Machine Learning Workflow Construction and Coding including essential concepts:
Suggestions for Learning to Code
Basics of Workflow Design
Workflow Building Blocks
YouTube Lecture: check out my lectures on:
Motivation for Machine Learning Workflow Construction and Coding#
You could learn the theory of data science and machine learning. Completely understand probability, statistics, inference and prediction, cross validation for hyperparameter tuning and model checking, but to add value we must code practical, fit-for-purpose workflows that can be widely deployed and used by many others. I’ve done this for many years and my goal is to share some of my experience to help you get started, or hone your skills!
If you don’t already code then please review my reasons for all scientists and engineers to learn some coding. I often share this on social media and in my classes.
Reasons for All Scientists and Engineers to Learn Some Coding#
Here’s Professor Pyrcz’s reasons for all scientists and engineers to learn some coding.
Transparency – no compiler accepts hand waiving! Coding forces your logic to be uncovered for any other scientist or engineer to review.
Reproducibility – run it and get an answer, hand it over to a peer, they run it and they get the same answer. This is a principle of the scientific method.
Quantification – programs need numbers and drive us from qualitative to quantitative. Feed the program and discover new ways to look at the world.
Open-source – leverage a world of brilliance. Check out packages, snippets and be amazed with what great minds have freely shared.
Break Down Barriers – don’t throw it over the fence. Sit at the table with the developers and share more of your subject matter expertise for a better deployed product.
Deployment – share your code with others and multiply your impact. Performance metrics or altruism, your good work benefits many others.
Efficiency – minimize the boring parts of the job. Build a suite of scripts for automation of common tasks and spend more time doing science and engineering!
Always Time to Do it Again! – how many times did you only do it once? It probably takes 2-4 times as long to script and automate a workflow. Usually, worth it.
Be Like Us – it will change you. Users feel limited, programmers truly harness the power of their applications and hardware.
I have decades of Basic, Fortran, Visual Basic for Applications (VBA), C++, R, and Python. My first codes in middle school were written in Basic on a Texas Instruments TI-99/4A home computer and stored on cassette tape. I’ve done a lot of numerical prototypes, workflows, scripts, dashboards and even a few years of full-stack development. Let me put it this way, “canned software” makes me feel trapped, I’m immediately looking for an Application Programming Interface (API) so I can escape and write my own methods, dashboards and visualizations. Yet I remain very practical and humble about coding; therefore, my advice is learn what you need to get the job done. Here some alternatives:
learn to use the workflow automation functionality in canned software. The documentation is usually quite good and this approach not only provides an audit trail for your workflows, but it also is compliant with your organization’s workflow standard and IT department policies.
if the canned software accepts Python, Java, controls then learn some basics in those language to interactive with the objects in your workflows. This will often greatly improve your flexibility to make value adding workflows.
many organizations are starting to prototype and deploy workflows in Python with tools such as Jupyter Notebooks and Jupyter Lab. If this is the case, learn some Python basics, start working with basic Python packages like Numpy, Pandas, Matplotlib, and SciPy. Go online and Google and ask ChatGPT to help with your workflow development. There are so many resources to help, including this e-book and the basics in coding that I share in this chapter.
Don’t be intimidated, I don’t wish (or curse on) you a life of full stack development. Those were days of searching for memory leaks and hanging pointers in C++. This is what I say after all of these experiences,
With Python
I code much less, and get more done!
Modeling Purpose#
The first step in any data science project is to pose the question, what is the purpose of this work? To address this we have to step back and ask:
What is the problem?
What have others done to solve this problem?
What are we going to do to solve this problem?
What can we deploy to solve this problem?
Let’s start by reviewing some purposes for modeling. Now these will be focused on my experience in subsurface modeling, but they are transferable to any other type of data science project.
Build a Numerical Model / Common Earth Model#
You often hear that we don’t model for the sake of modeling. That is mostly true, but sometimes there is value in just building the model. In this case, we see the model as a numerical platform to integrate all available information, build a unified understanding of the problem setting. When we do this there is a lot value adding things that often happen:
Establish what is known, unknown and the critical risks
Find out that there are issues. Modeling up front is part of the fail fast approach that allows us to eliminate avenues of investigation before too much to and resources are invested.
Build a communication tool, that ensures that all the data is integrated and consistent and that everyone on the team has a shared understanding of the problem. Here’s an example of a subsurface model based on the integration of many diverse data types.
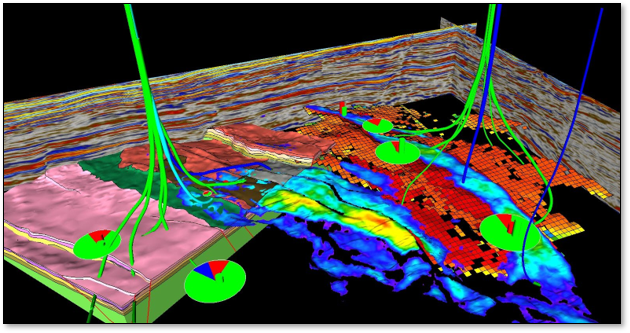
Assess Resources and Value#
Sometimes models support the assessment of value. For a resource company resources and reserves are a critical part of their valuation. These models compute the gross volume of the resources, the associated spatial distribution and schedule of resource recovery.
Of course, in this case we include much more than the data, including the engineering and geoscience associated with the extraction method and the forecasts of market conditions. Our models are often integrated over many scientific disciplines are may even be applied to report value outside our organization.
These types of assessments are common for subsurface resources, e.g., mining, hydrocarbon extraction, etc.

Quantify Resources Uncertainty#
Once again we must always integrate multiple sources and multiple scales of data, but often we must also include all significant sources of uncertainty to model uncertainty in recoverable resource.
These types of projects report uncertainty and risk, but also may be used to direct data collection to reduce uncertainty, support development decisions and / or public disclosures
Exporting Statistics#
Sometimes we model a thing to help model another thing! In this case we develop a robust set of statistics from a mature location with a lot of good data for the purpose of applying this model to support decision making in a less mature, less sampled early development location. In this case we are assuming that the two sites are similar, known as an assumption of stationarity in geostatistics.
Example of exported statistics include, distributions, correlations, training images, etc.
For example, outcrops from Laingsburg, South Africa have been studied as analogs for deepwater reservoirs all over the world.
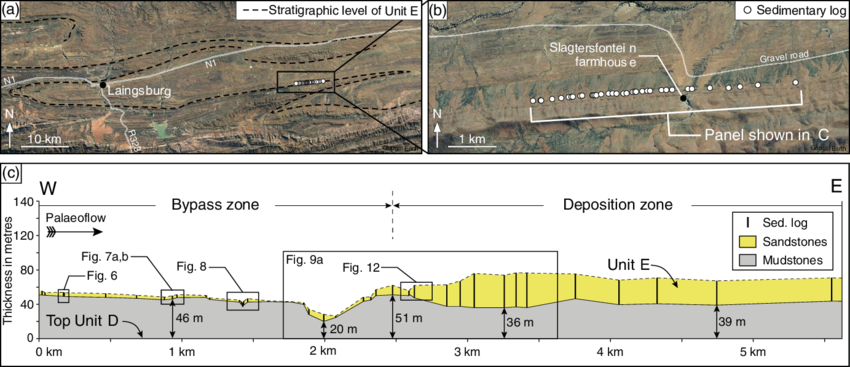
There are many other purposes for modeling.
The Common Machine Learning Workflow#
Once we know the purpose for our data science modeling work, then we can utilize common modeling workflows. For example, for many machine learning projects we follow these steps:
Data Cleaning - there are going to be data issues. Missing data, data with errors, biased data, etc. Often data cleaning is 80% - 90% of the effort on a data science project. This step requires a lot of domain expertise, so I can’t give you too much advice for your case besides,
be patient with this step, rushing data cleaning will usually impact model accuracy and require a lot of repeated work later.
engage with the entire project team, including all experts that know the various data types. Don’t assume that you know all the essential metadata.
Feature Engineering - is about taking the raw features and getting them into the optimum form to build the best possible models. This may include feature transformations, feature projection to new more useful features or even feature selection. My advice is,
don’t work in autopilot and just pass all the available features into your machine learning models and hope the models will sort it out. This typically results in low interpretability, and lower accuracy models.
Inferential Machine Learning - apply inferential machine learning to learn more from your limited sample data about the population. This may include cluster analysis to infer separate populations to model separately.
this is your chance to explore the data to learn new patterns and then update the plan for the next step, predictive modeling
Predictive Machine Learning - train and tune predictive machine learning models based on all the previous work, i.e., with clean data, engineered features, and inferential models about the population(s).
this step gets the most attention, but it is often only about 3% - 5% of the work. If you are spending most of your time on this step that should be a red flag.
Model Checking and Documentation - we always, always check every step in our workflows and after we build our models we check them. You might say, “Why? Didn’t we already train and tune our models?”. You are correct, we did take a lot of care, but we are not done yet. Some ideas:
use explainable AI tools like Shapley values to understand the behaviors of our model.
stress test your model with various interpolation and extrapolation cases to determine when your model breaks.
now, put together great documentation, diagnostics, and training content (you could also cite my e-books and my YouTube lectures). This step is critical for the widest deployment and biggest impact for your work.
Fit-for-Purpose Modeling#
Regardless what data science workflow you build, you need to have a “fit-for-purpose” mentality. What does that mean?
As we discussed, the data science workflow design considers the goals of the workflow
We should also consider the future possible needs for the workflow, i.e., is it extendable?, could it be rapidly updated?, and will you be able to keep up if it is a hit in your organization?
Also we must always account for the resources, time and people (expertise) available in our organization. For example, deploy a simple workflow if your organization does not have a lot of data science expertise and compute resources available
We can’t have it all! This image has been very helpful to me over my career, it is the good, fast, cheap diagram, that illustrates the project trade off that you can only pick two and cannot have all three!

Modeling Constraints#
Let’s talk a bit more about modeling constraints. Every organization has limitations, this is critical to capital stewardship and profitability. Here’s some of the common constraints,
Professional Time - work hours available limited by workforce, number of projects and project timelines schedules. Our time is valuable and within the organization there is an accounting of the cost to maintain each project team member, full time equivalent (FTE), for a period of time. From this we can think about what activities are value adding to offset this cost.
Organization Capability - some organizations call this operational capability, it is the skill sets of the professionals that are available for the project. Yes, you may have a world renowned deep learning expert in your project team, but their time is likely split over multiple projects along with mentorship and leadership responsibilities.
Computational Facilities - this includes the computational storage and processing of the hardware, along with the software available for the project. You may have access to a specific numerical simulation software, but with a limited number of seats shared over the organization, and it would be rare to be able to run our deep learning convolution models over massive 3D model spaces.
Data Collection - you will not get all the data that you want for your data science project. Number of samples will usually be limited, and you may not have all the features that you want. Sometimes there may even be controls on how data is moved, stored and used that may limit your work. May I offer some sagely advice? Be very careful about this! Always have permission for any use and release of data, including work derived from data.
Total Budget - if you put this all together you get the ultimate limitation, how much can be spent on the project. This is the ultimate limit on all the previous, professional time, computational resources and data collection
Modeling Strategies#
There are various overarching modeling strategies. I will only mention a couple here.
Top-down Modeling#
I like this approach, it is very conservative with elements of fail fast and fit-for-purpose modeling. It proceeds with these steps.
Start with the simplest model possible and forecast with the model
Incrementally add detail and complexity to the model, forecast and access the change in the forecast due to added complexity
Iterate until additional detail and complexity does not impact the forecast
For geomodelling this is applied as starting with a simple grid framework and some basic large scale heterogeneity, e.g., major geological discontinuities and barriers. Apply numerical simulation and evaluate the model performance. Then add in more medium scale heterogeneity within the large scale framework and repeat the numerical simulation and evaluation with a focus on the change. Repeat this process until the additional complexity does not impact the numerical simulation results.
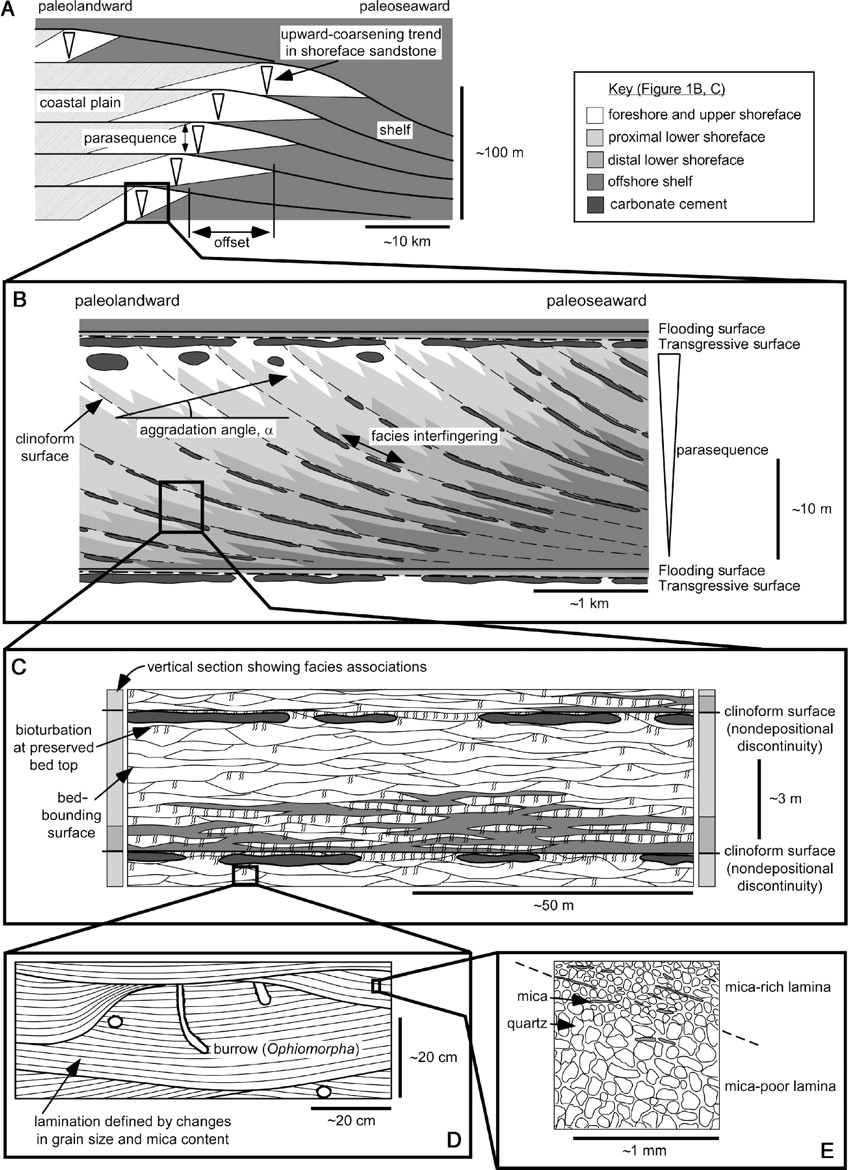
How does top-down modeling apply to machine learning? In a way we already do it, when we tune the hyperparameters by testing a simple machine learning model and then incrementing the complexity until the test error is minimized. We can go further and integrate top-down modeling into our general approach by asking, what is the simplest model that gets us an accurate enough model, because this model will likely be more interpretable and practical to deploy.
Modeling for Discomfort#
Mark Bentley proposed the concept of “modeling for comfort” [] with the suggestion that models may have become tools for verification of a decision already partially or fully made. To defend against this tendency, Bentley recommends that we model for discomfort!
Stress test our current concepts and sensitivity on decision-making
Bentley states that by doing this we can identify remaining up-side potential and while securing against worst case. Also this is a great approach to recognize and mitigate our biases.
I call this the Mythbusters approach after the science and engineering TV show with Jaime and Adam. My kids grew up watching Mythbusters and I loved the show also. They took something from a movie or history and tested it. For example,
will focusing many polished shields start a wooden ship on fire
will putting a car in reverse while driving cause the transmission to fall out
can a high pitch sound break a glass
How do we apply modeling for discomfort or the Mythbusters approach in our model construction. Simple, stress test your models. Consider the following,
your model predicts very well, but can you find cases for which your model is inaccurate
your model is robust to outliers, add more outliers and observe the limit in this robustness
your model preserves information while reducing the dimensionality of the problem, add more dimensions
your model runs fast enough in 2D, try it in 3D
This is the equivalent to Jaime and Adam failing to see a failure and deciding to add more pressure, more velocity, more… until it fails.

Learning to Code in Python#
I have taught data science to hundreds of engineers and geoscientists, many of them had no programming experience and are now doing data science in Python. This is awesome and I’m excited to help. To support these students I have developed a verity of resources that are helpful,
Data Science Basics in Python code walk-throughs with GeostatsGuy
I selected some of the building blocks of machine learning workflows and built out live code presentations (with the Rise Python package) and recorded my walk-through and included it as a playlist[Pyr24b] on my YouTube channel. Anyone can open up the workflows (links in the comments and follow along).

Machine Learning Course on YouTube
My entire machine learning course is available as a playlist[Pyr24b] on my YouTube channel[Pyr24e]. Note only does it include all the recorded lectures, but also links in the comments to all the codes, including well-documented workflows and interactive dashboards in Python. I provide many realistic examples of working with data, building machine learning models, visualizing and checking the data and models, etc.
Applied Machine Learning in Python, a Hands-on Guide with Code
Of course, this book is full of resources, including a lot of example code. In fact, in many cases I included additional comments and descriptions to help those new to coding.
You Got This
I’ve seen many quickly learn the basic coding skills to build machine learning workflows.
Want to Work Together?#
I hope this content is helpful to those that want to learn more about subsurface modeling, data analytics and machine learning. Students and working professionals are welcome to participate.
Want to invite me to visit your company for training, mentoring, project review, workflow design and / or consulting? I’d be happy to drop by and work with you!
Interested in partnering, supporting my graduate student research or my Subsurface Data Analytics and Machine Learning consortium (co-PIs including Profs. Foster, Torres-Verdin and van Oort)? My research combines data analytics, stochastic modeling and machine learning theory with practice to develop novel methods and workflows to add value. We are solving challenging subsurface problems!
I can be reached at mpyrcz@austin.utexas.edu.
I’m always happy to discuss,
Michael
Michael Pyrcz, Ph.D., P.Eng. Professor, Cockrell School of Engineering and The Jackson School of Geosciences, The University of Texas at Austin
Comments#
This was a basic description of machine learning workflow construction and coding. Much more could be done and discussed, I have many more resources. Check out my shared resource inventory.
I hope this was helpful,
Michael