

Declustering to Correct Sampling Bias#
Michael J. Pyrcz, Professor, The University of Texas at Austin
Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Chapter of e-book “Applied Geostatistics in Python: a Hands-on Guide with GeostatsPy”.
Cite this e-Book as:
Pyrcz, M.J., 2024, Applied Geostatistics in Python: a Hands-on Guide with GeostatsPy [e-book]. Zenodo. doi:10.5281/zenodo.15169133 ![]()
The workflows in this book and more are available here:
Cite the GeostatsPyDemos GitHub Repository as:
Pyrcz, M.J., 2024, GeostatsPyDemos: GeostatsPy Python Package for Spatial Data Analytics and Geostatistics Demonstration Workflows Repository (0.0.1) [Software]. Zenodo. doi:10.5281/zenodo.12667036. GitHub Repository: GeostatsGuy/GeostatsPyDemos ![]()
By Michael J. Pyrcz
© Copyright 2024.
This chapter is a tutorial for / demonstration of Spatial Data Declustering.
YouTube Lecture: check out my lecture on Sources of Spatial Bias and Spatial Data Declustering. For your convenience here’s a summary of the salient points.
Geostatistical Sampling Representativity#
Here’s a dataset,
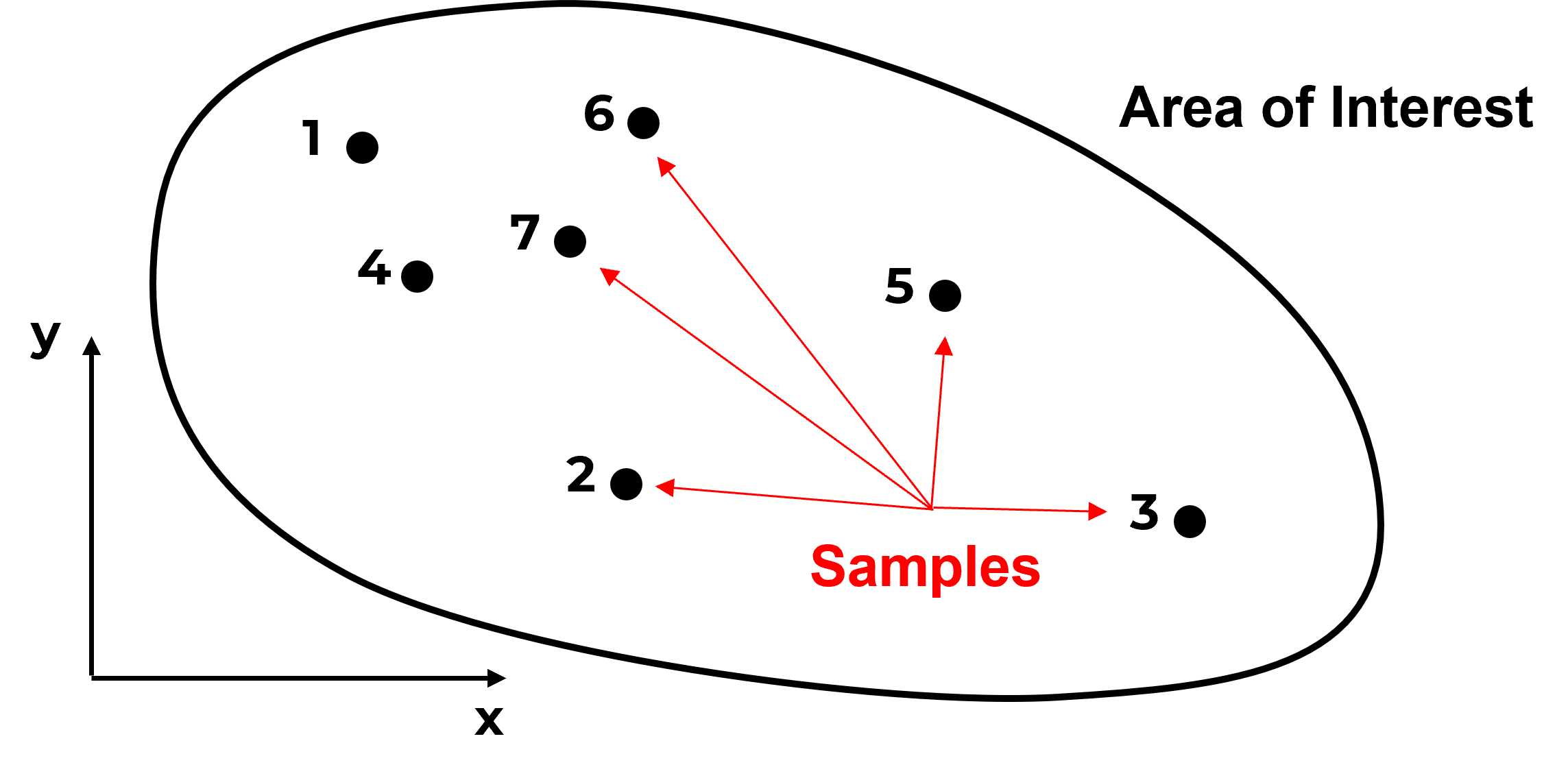
Do you have any concerns with this data? What if I add this information?
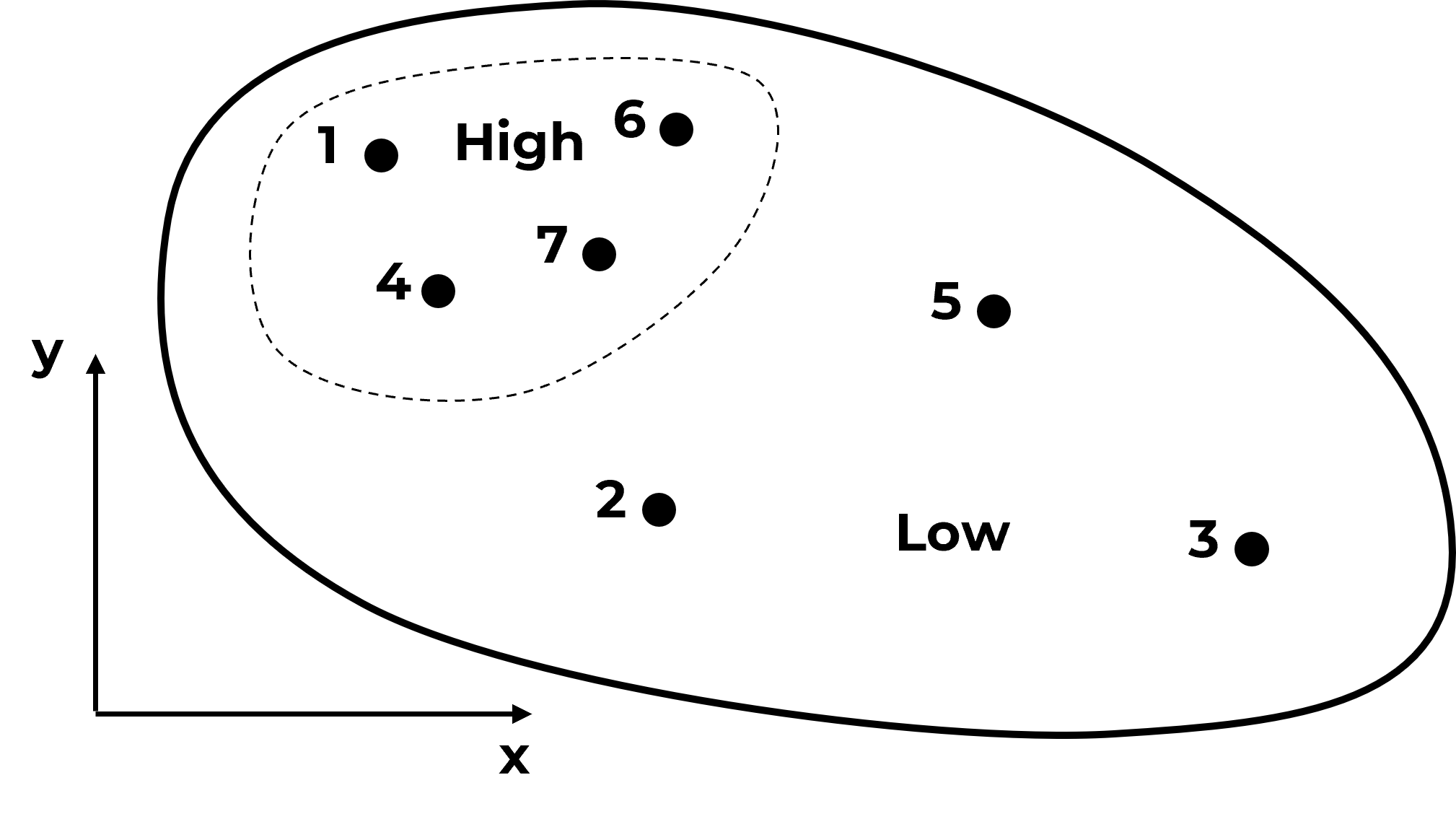
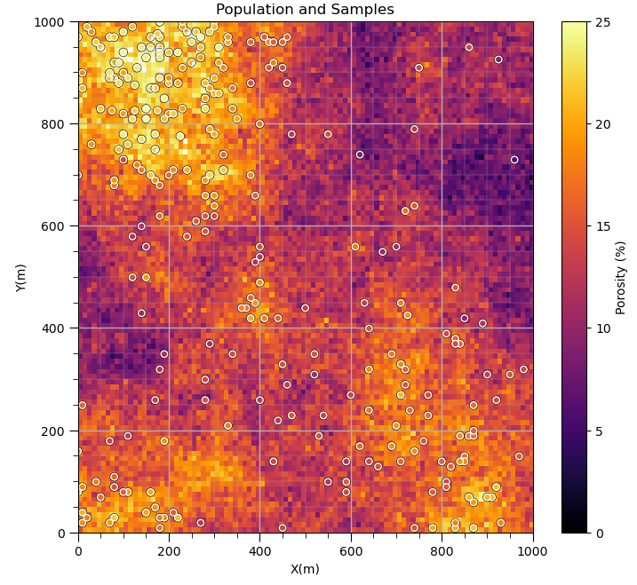
Do you see what is going on? The samples are actually clustered in the high area. It can get much worse,
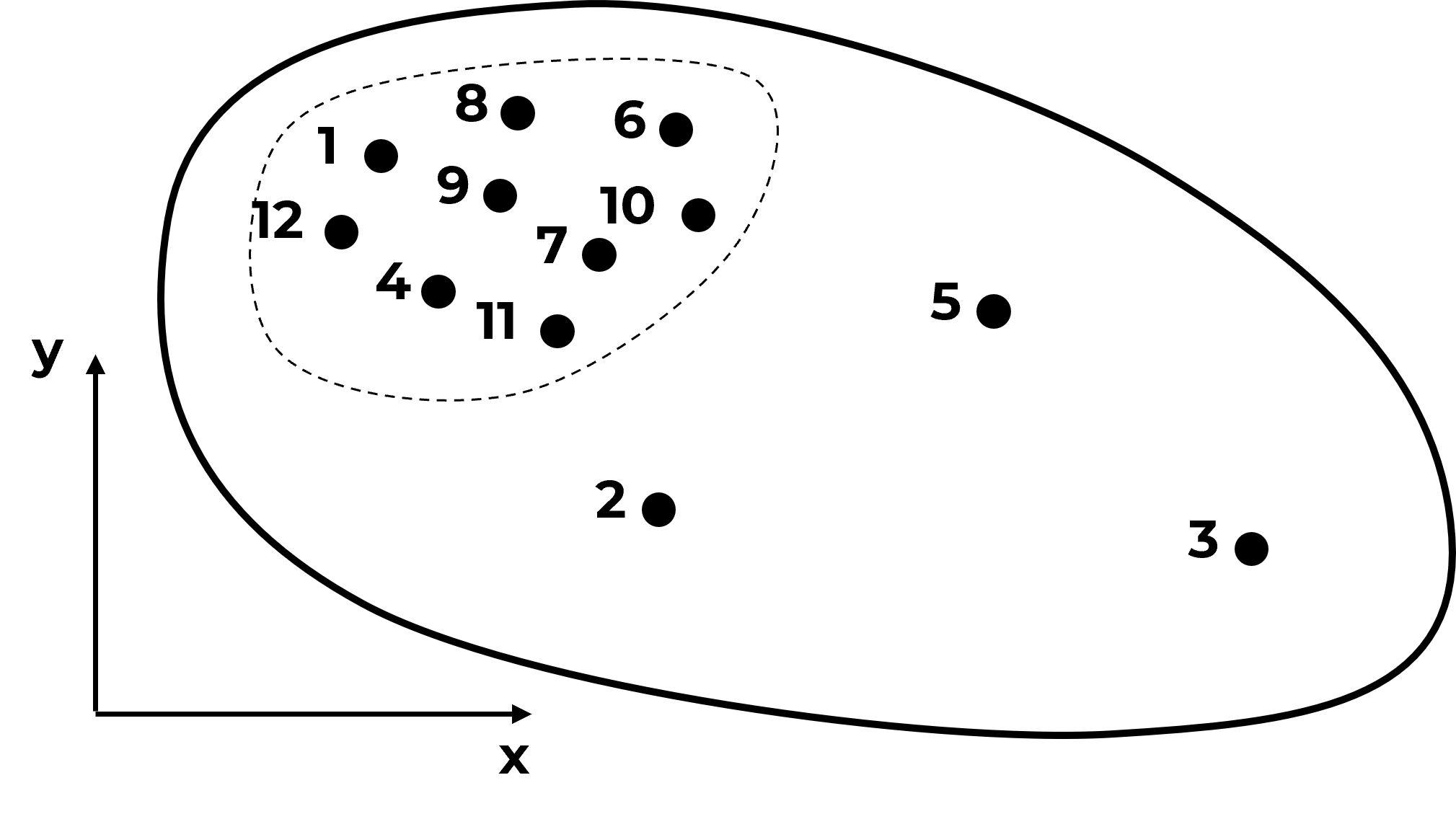
and as we continue to sample in the high region we will increase the bias in the sample statistics,
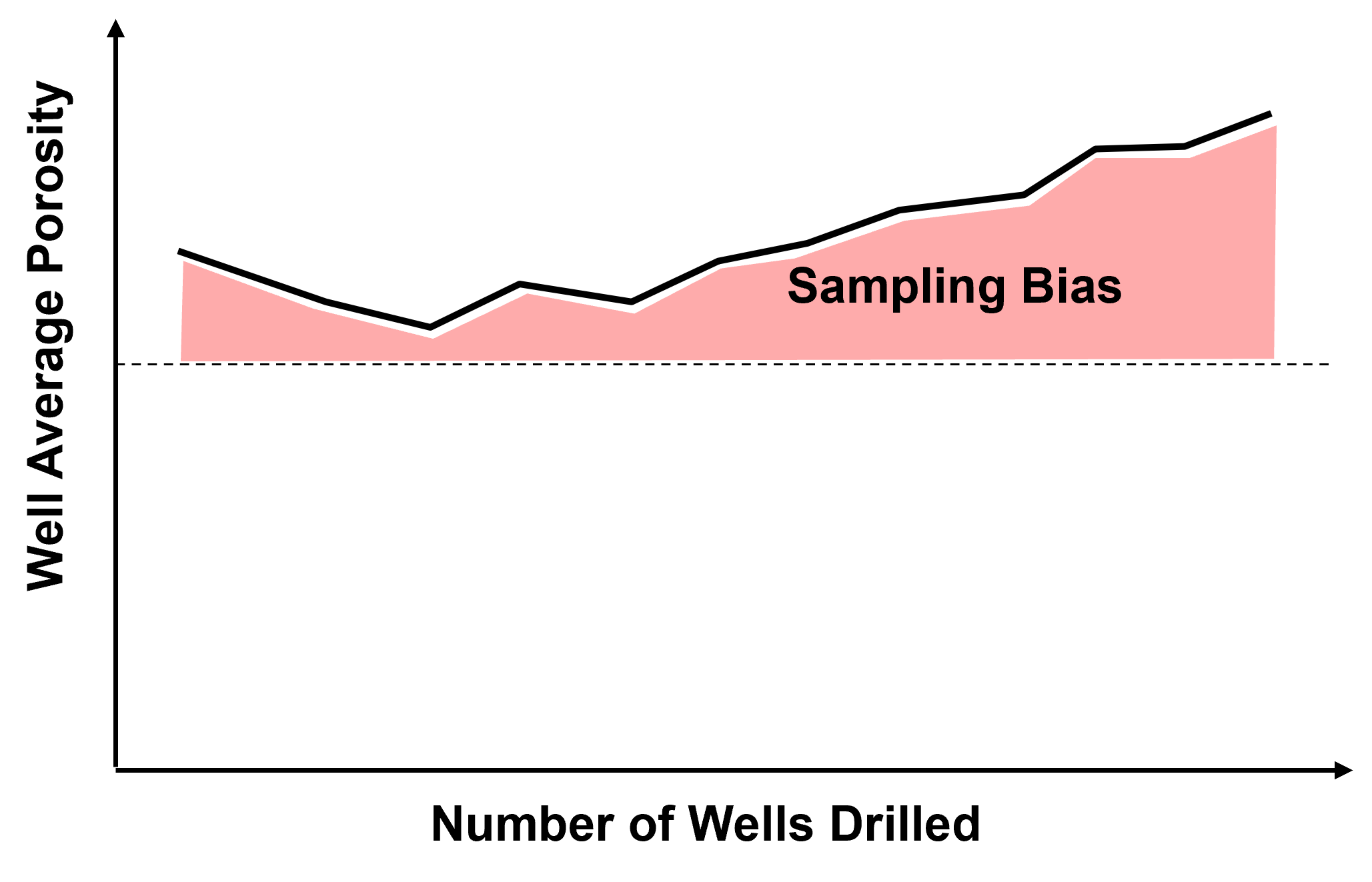
Source of Spatial Sampling Bias - in general, we should assume that all spatial data that we work with is biased.
Data is collected to answer questions:
how far does the contaminant plume extend? – sample peripheries
where is the fault? – drill based on seismic interpretation
what is the highest mineral grade? – sample the best part
who far does the reservoir extend? – offset drilling and to maximize NPV directly:
maximize production rates
Here’s an example sample set with the inaccessible population shown for demonstration,
Random Sampling: when every item in the population has a equal chance of being chosen. Selection of every item is independent of every other selection. Is random sampling sufficient for subsurface? Is it available?
it is not usually available, would not be economic
data is collected answer questions
how large is the reservoir, what is the thickest part of the reservoir
and wells are located to maximize future production
dual purpose appraisal and injection / production wells!
Regular Sampling: when samples are taken at regular intervals (equally spaced).
less reliable than random sampling.
Warning: may resonate with some unsuspected environmental variable.
What do we have?
we usually have biased, opportunity sampling
we must account for bias (debiasing will be discussed later)
So if we were designing sampling for representativity of the sample set and resulting sample statistics, by theory we have 2 options, random sampling and regular sampling.
What would happen if you proposed random sampling in the Gulf of Mexico at $150M per well?
We should not change current sampling methods as they result in best economics, we should address sampling bias in the data.
Never use raw spatial data without access sampling bias / correcting.
Cell-based Declustering Summary#
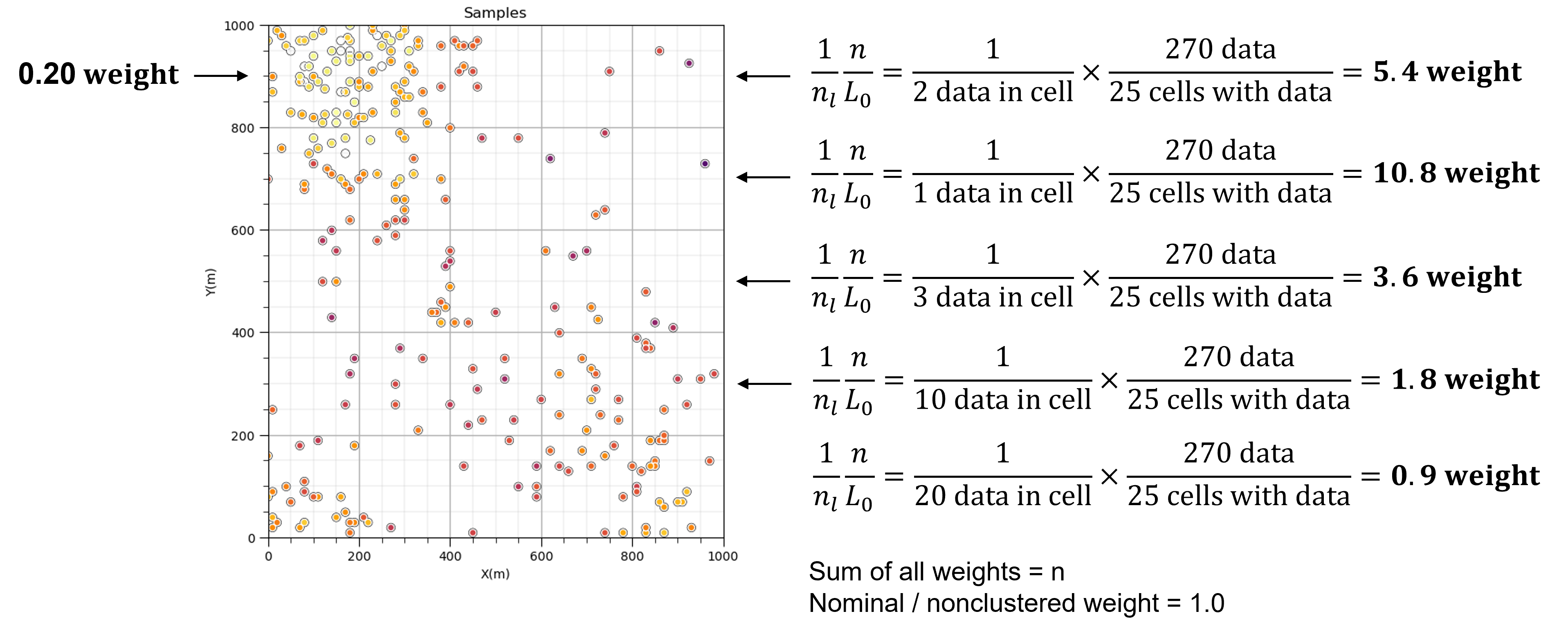
Sample data debiasing with cell-based declustering proceeds by placing a cell mesh over the data and share the weight over each cell.
data in densely sampled areas or volumes will get less weight while data in sparsely sampled areas or volumes will get more weight.
Cell-based declustering weights are calculated by first identifying the cell that the data occupies, \(\ell\), then applying this equation,
where \(n_{\ell}\) is the number of data in the \(\ell\) cell standardized by the ratio of \(n\) is the total number of data divided by \(L_o\) number of cells with data. As a result the sum of all weights is \(n\) and nominal weight is 1.0.
Additional considerations:
influence of cell mesh origin is removed by averaging the data weights over multiple random cell mesh origins
the optimum cell size is selected by minimizing or maximizing the declustered mean, based on whether the means is biased high or low respectively
In this demonstration we will take a biased spatial sample data set and apply declustering using GeostatsPy functionality.
Load the Required Libraries#
The following code loads the required libraries.
import geostatspy.GSLIB as GSLIB # GSLIB utilities, visualization and wrapper
import geostatspy.geostats as geostats # GSLIB methods convert to Python
import geostatspy
print('GeostatsPy version: ' + str(geostatspy.__version__))
GeostatsPy version: 0.0.71
We will also need some standard packages. These should have been installed with Anaconda 3.
import os # set working directory, run executables
from tqdm import tqdm # suppress the status bar
from functools import partialmethod
tqdm.__init__ = partialmethod(tqdm.__init__, disable=True)
ignore_warnings = True # ignore warnings?
import numpy as np # ndarrays for gridded data
import pandas as pd # DataFrames for tabular data
import matplotlib.pyplot as plt # for plotting
from matplotlib.ticker import (MultipleLocator, AutoMinorLocator) # control of axes ticks
import matplotlib.ticker as ticker # custom axes
from scipy import stats # summary statistics
from statsmodels.stats.weightstats import DescrStatsW # any weighted statistics
plt.rc('axes', axisbelow=True) # plot all grids below the plot elements
if ignore_warnings == True:
import warnings
warnings.filterwarnings('ignore')
Define Functions#
This is a convenience function to add major and minor gridlines to improve plot interpretability.
def add_grid():
plt.gca().grid(True, which='major',linewidth = 1.0); plt.gca().grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
Set the Working Directory#
I always like to do this so I don’t lose files and to simplify subsequent read and writes (avoid including the full address each time).
#os.chdir("d:/PGE383") # set the working directory
Loading Tabular Data#
Here’s the command to load our comma delimited data file in to a Pandas’ DataFrame object.
df = pd.read_csv('https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/spatial_nonlinear_MV_facies_v5_sand_only.csv')
What if we needed to make some minor changes to the loaded DataFrame? For example:
change the name of a feature?
df = df.rename(columns={'Porosity':'Por'})
scale fractional porosity to percentage porosity (multiple by 100)?
df['Por'] = df['Por']*100
Previewing the DataFrame#
Let’s use Panda’s built in .head() function.
df.head(n=5) # we could also use this command for a table preview
| Unnamed: 0 | X | Y | Por | Perm | AI | Facies | |
|---|---|---|---|---|---|---|---|
| 0 | 2902 | 2900 | 8690 | 19.918960 | 230.034307 | 3872.084994 | 0 |
| 1 | 1853 | 1400 | 7790 | 23.181930 | 436.280432 | 3635.918413 | 0 |
| 2 | 4407 | 1800 | 6190 | 16.879564 | 76.425825 | 4044.697940 | 0 |
| 3 | 3200 | 4800 | 190 | 14.563102 | 106.760754 | 4449.654955 | 0 |
| 4 | 3534 | 1300 | 8090 | 21.566379 | 618.936205 | 3734.979848 | 0 |
Summary Statistics for Tabular Data#
The table includes X and Y coordinates (meters), Facies 1 and 2 (1 is sandstone and 0 interbedded sand and mudstone), Porosity (fraction), and permeability as Perm (mDarcy).
There are a lot of efficient methods to calculate summary statistics from tabular data in DataFrames. The describe command provides count, mean, minimum, maximum, and quartiles all in a nice data table. We use transpose just to flip the table so that features are on the rows and the statistics are on the columns.
df.describe() # summary statistics
| Unnamed: 0 | X | Y | Por | Perm | AI | Facies | |
|---|---|---|---|---|---|---|---|
| count | 270.000000 | 270.000000 | 270.000000 | 270.000000 | 270.000000 | 270.000000 | 270.0 |
| mean | 2461.325926 | 3484.814815 | 5711.111111 | 18.381488 | 513.340334 | 3952.045158 | 0.0 |
| std | 1507.826244 | 2740.053144 | 3379.110146 | 4.262747 | 310.213322 | 260.243630 | 0.0 |
| min | 18.000000 | 0.000000 | 90.000000 | 9.224354 | 0.000000 | 3549.859605 | 0.0 |
| 25% | 1139.000000 | 1250.000000 | 2340.000000 | 14.866536 | 287.343802 | 3736.619686 | 0.0 |
| 50% | 2393.500000 | 2700.000000 | 6690.000000 | 18.629858 | 494.810838 | 3935.496559 | 0.0 |
| 75% | 3745.000000 | 5500.000000 | 8865.000000 | 21.723391 | 728.374673 | 4128.857755 | 0.0 |
| max | 4955.000000 | 9800.000000 | 9990.000000 | 27.594892 | 1458.288193 | 4708.782401 | 0.0 |
Specify the Area of Interest#
It is natural to set the x and y coordinate and feature ranges manually. e.g. do you want your color bar to go from 0.05887 to 0.24230 exactly? Also, let’s pick a color map for display. I heard that plasma is known to be friendly to the color blind as the color and intensity vary together (hope I got that right, it was an interesting Twitter conversation started by Matt Hall from Agile if I recall correctly). We will assume a study area of 0 to 1,000m in x and y and omit any data outside this area.
xmin = 0.0; xmax = 10000.0 # range of x values
ymin = 0.0; ymax = 10000.0 # range of y values
pormin = 5; pormax = 25; # range of porosity values
cmap = plt.cm.inferno # color map
formatter = ticker.FuncFormatter(lambda x, _: f'{x:,.0f}') # commas on axes
Visualizing Tabular Data with Location Maps#
Let’s try out locmap. This is a reimplementation of GSLIB’s locmap program that uses matplotlib. I hope you find it simpler than matplotlib, if you want to get more advanced and build custom plots lock at the source. If you improve it, send me the new code. Any help is appreciated. To see the parameters, just type the command name:
GSLIB.locmap # GeostatsPy's 2D point plot function
<function geostatspy.GSLIB.locmap(df, xcol, ycol, vcol, xmin, xmax, ymin, ymax, vmin, vmax, title, xlabel, ylabel, vlabel, cmap, fig_name)>
Now we can populate the plotting parameters and visualize the porosity data.
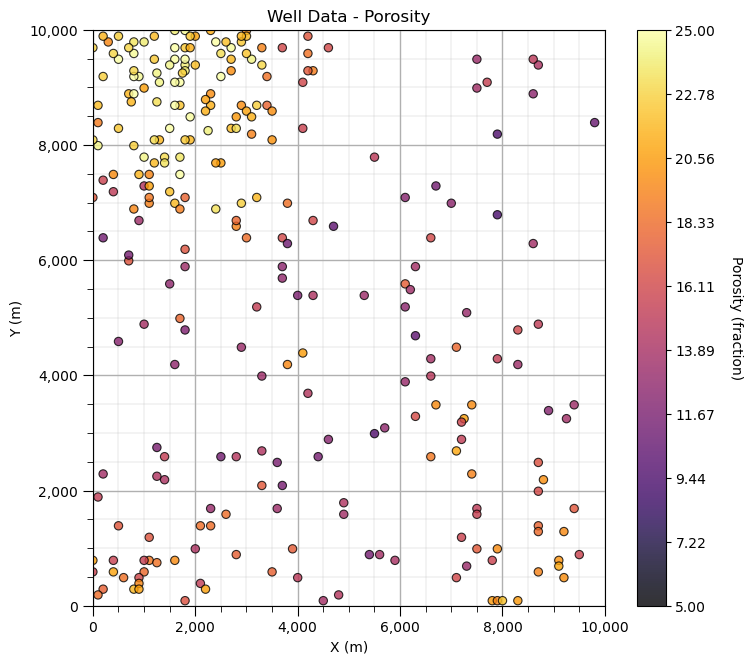
GSLIB.locmap_st(df,'X','Y','Por',xmin,xmax,ymin,ymax,pormin,pormax,'Well Data - Porosity','X (m)','Y (m)','Porosity (fraction)',cmap)
add_grid(); plt.gca().xaxis.set_major_formatter(formatter); plt.gca().yaxis.set_major_formatter(formatter)
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.2, wspace=0.2, hspace=0.2); plt.show()
Cell-based Declustering#
Look carefully, and you’ll notice that the spatial samples are more dense in the high porosity regions and lower in the low porosity regions. There is preferential sampling. We cannot use the naive statistics to represent this region. We have to correct for the clustering of the samples in the high porosity regions.
Let’s try cell declustering. We can interpret that we will want to minimize the declustering mean and that a cell size of between 100 - 200m is likely a good cell size, this is ‘an ocular’ estimate of the largest average spacing in the sparsely sampled regions.
Let’s check out the declus program reimplemented in GeostatsPy from GSLIB.
geostats.declus # GeostatsPy's declustering function
<function geostatspy.geostats.declus(df, xcol, ycol, vcol, iminmax, noff, ncell, cmin, cmax)>
We can now populate the parameters. The parameters are:
df - DataFrame with the spatial dataset
xcol - column with the x coordinate
ycol - column with the y coordinate
vcol - column with the feature value
iminmax - if 1 use the cell size that minimizes the declustered mean, if 0 the cell size that maximizes the declustered mean
noff - number of cell mesh offsets to average the declustered weights over
ncell - number of cell sizes to consider (between the cmin and cmax)
cmin - minimum cell size
cmax - maximum cell size
We will run a very wide range of cell sizes, from 10m to 2,000m (‘cmin’ and ‘cmax’) and take the cell size that minimizes the declustered mean (‘iminmax’ = 1 minimize, and = 0 maximize). Multiple offsets (number of these is ‘noff’) uses multiple grid origins and averages the results to remove sensitivity to grid position. The ncell is the number of cell sizes.
The output from this program is:
wts - an array with the weights for each data (they sum to the number of data, 1 indicates nominal weight)
cell_sizes - an array with the considered cell sizes
dmeans - an array with the declustered mean for each of the cell_sizes
The wts are the declustering weights for the selected (minimizing or maximizing cell size) and the cell_sizes and dmeans are plotted to build the diagnostic declustered mean vs. cell size plot (see below).
ncell = 100; cmin = 10; cmax = 20000; noff = 10; iminmax = 1
wts, cell_sizes, dmeans = geostats.declus(df,'X','Y','Por',iminmax = iminmax,noff = noff,
ncell = ncell,cmin = cmin,cmax = cmax) # GeostatsPy's declustering function
df['Wts'] = wts # add weights to the sample data DataFrame
df.head() # preview to check the sample data DataFrame
There are 270 data with:
mean of 18.381488145500636
min and max 9.224354317579358 and 27.594891730048342
standard dev 4.2548458306479775
| Unnamed: 0 | X | Y | Por | Perm | AI | Facies | Wts | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2902 | 2900 | 8690 | 19.918960 | 230.034307 | 3872.084994 | 0 | 0.292987 |
| 1 | 1853 | 1400 | 7790 | 23.181930 | 436.280432 | 3635.918413 | 0 | 0.304374 |
| 2 | 4407 | 1800 | 6190 | 16.879564 | 76.425825 | 4044.697940 | 0 | 1.054949 |
| 3 | 3200 | 4800 | 190 | 14.563102 | 106.760754 | 4449.654955 | 0 | 2.641005 |
| 4 | 3534 | 1300 | 8090 | 21.566379 | 618.936205 | 3734.979848 | 0 | 0.294390 |
Checking Cell-based Declustering#
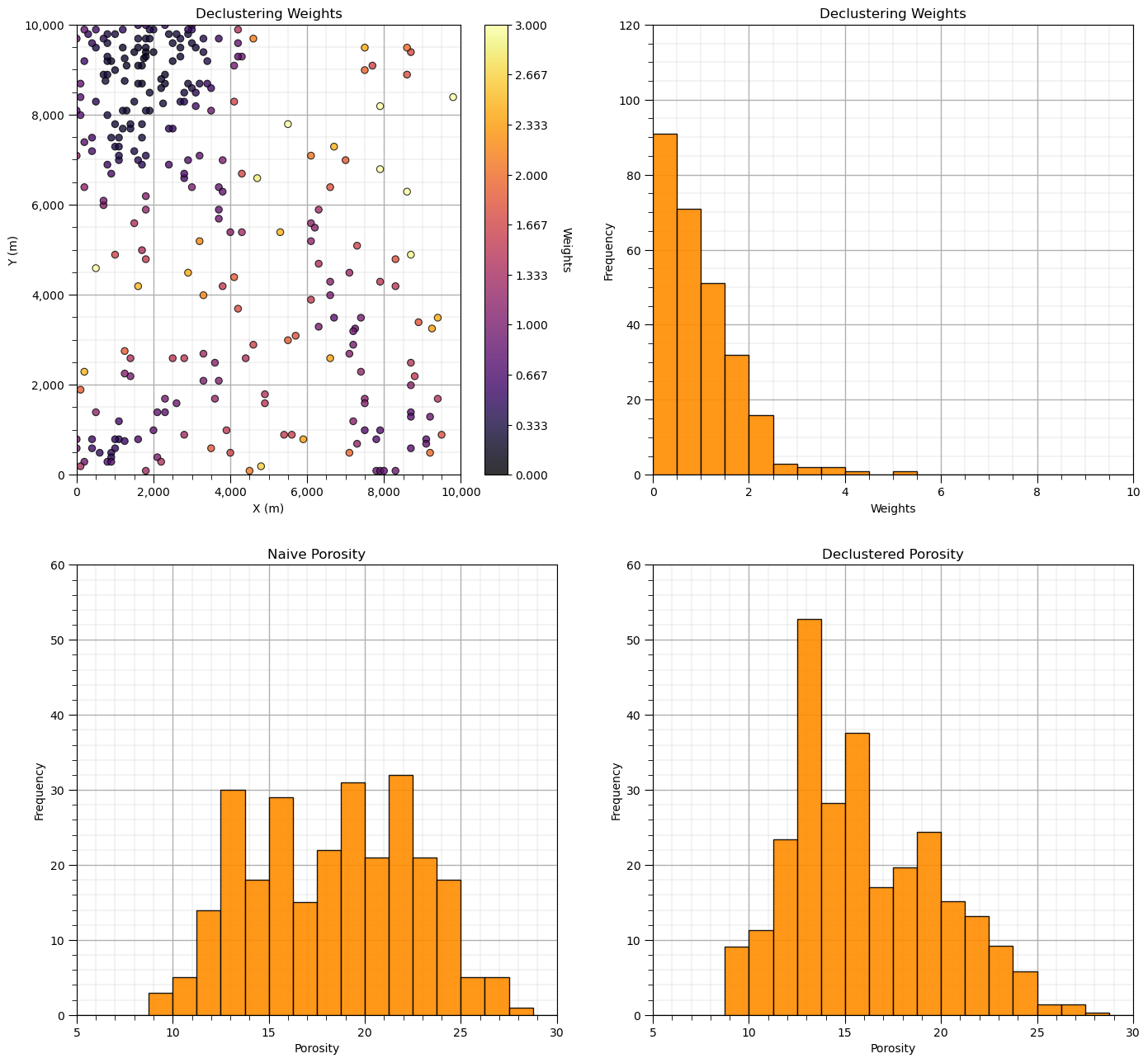
First, let’s look at the location map of the declustering weights.
GSLIB.locmap_st(df,'X','Y','Wts',xmin,xmax,ymin,ymax,0.0,2.5,'Well Data Weights','X (m)','Y (m)','Weights',cmap) # check
add_grid(); plt.gca().xaxis.set_major_formatter(formatter); plt.gca().yaxis.set_major_formatter(formatter)
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.2, wspace=0.2, hspace=0.2); plt.show()
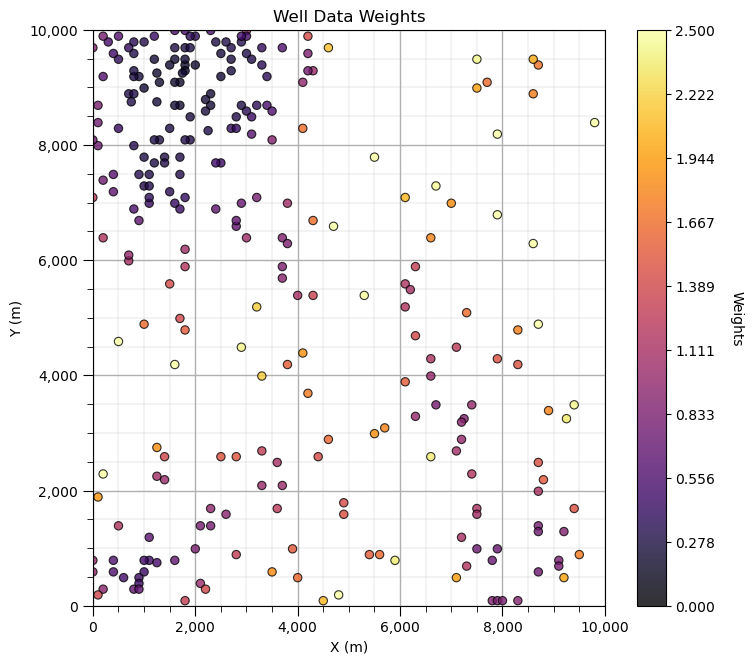
Does it look correct? See the weight varies with local sampling density?
Now let’s add the distribution of the weights and the naive and declustered porosity distributions. You should see the histogram bars adjusted by the weights. Also note the change in the mean due to the weights. There is a significant change.
plt.subplot(221)
GSLIB.locmap_st(df,'X','Y','Wts',xmin,xmax,ymin,ymax,0.0,3.0,'Declustering Weights','X (m)','Y (m)','Weights',cmap)
add_grid(); plt.gca().xaxis.set_major_formatter(formatter); plt.gca().yaxis.set_major_formatter(formatter)
plt.subplot(222)
GSLIB.hist_st(df['Wts'],0,10,log=False,cumul=False,bins=20,weights=None,xlabel="Weights",title="Declustering Weights")
plt.ylim(0.0,120); add_grid()
plt.subplot(223)
GSLIB.hist_st(df['Por'],5,30,log=False,cumul=False,bins=20,weights=None,xlabel="Porosity",title="Naive Porosity")
plt.ylim(0.0,60); add_grid()
plt.subplot(224)
GSLIB.hist_st(df['Por'],5,30,log=False,cumul=False,bins=20,weights=df['Wts'],xlabel="Porosity",title="Declustered Porosity")
plt.ylim(0.0,60); add_grid()
por_mean = np.average(df['Por'].values)
por_dmean = np.average(df['Por'].values,weights=df['Wts'].values)
print('Porosity naive mean is ' + str(round(por_mean,3))+'.')
print('Porosity declustered mean is ' + str(round(por_dmean,3))+'.')
cor = (por_mean-por_dmean)/por_mean
print('Correction of ' + str(round(cor,4)) +'.')
print('\nSummary statistics of the declustering weights:')
print(stats.describe(wts))
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=2.5, wspace=0.2, hspace=0.2)
plt.show()
Porosity naive mean is 18.381.
Porosity declustered mean is 16.059.
Correction of 0.1264.
Summary statistics of the declustering weights:
DescribeResult(nobs=270, minmax=(0.20904854434290107, 5.060379981544719), mean=1.0000000000000009, variance=0.5948104935709296, skewness=1.7216051448854657, kurtosis=4.291384441783515)
Now let’s look at the plot of the declustered porosity mean vs. the declustering cell size over the 100 runs. At very small and very large cell size the declustered mean is the naive mean.
csize_min = cell_sizes[np.argmin(dmeans)] # retrieve the minimizing cell size
smin = 10; smax = 20 # range of statistic on y axis, set to improve visualization
plt.subplot(111)
plt.scatter(cell_sizes,dmeans, s=30, alpha = 0.8, edgecolors = "black", facecolors = 'darkorange')
plt.xlabel('Cell Size (m)')
plt.ylabel('Declustered Porosity Mean (fraction)')
plt.title('Declustered Porosity Mean vs. Cell Size')
plt.plot([cmin,cmax],[por_mean,por_mean],color = 'black')
plt.plot([cmin,cmax],[por_dmean,por_dmean],color = 'black',ls='--')
plt.plot([csize_min,csize_min],[ymin,por_dmean],color = 'black',linestyle='dashed')
plt.text(0.1*(cmax - cmin) + cmin, por_mean+0.1, r'Naive Porosity Mean')
plt.text(0.2*(cmax - cmin) + cmin, por_dmean+0.1, r'Declustered Porosity Mean')
plt.text(csize_min+30,0.70 * (por_dmean - smin) + smin, r'Minimizing')
plt.text(csize_min+30,0.63 * (por_dmean - smin) + smin, r'Cell Size = ' + str(np.round(csize_min,1)))
plt.ylim([smin,smax]); plt.xlim(cmin,cmax)
add_grid(); plt.gca().xaxis.set_major_formatter(formatter)
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.2, top=1.2, wspace=0.2, hspace=0.2)
plt.show()
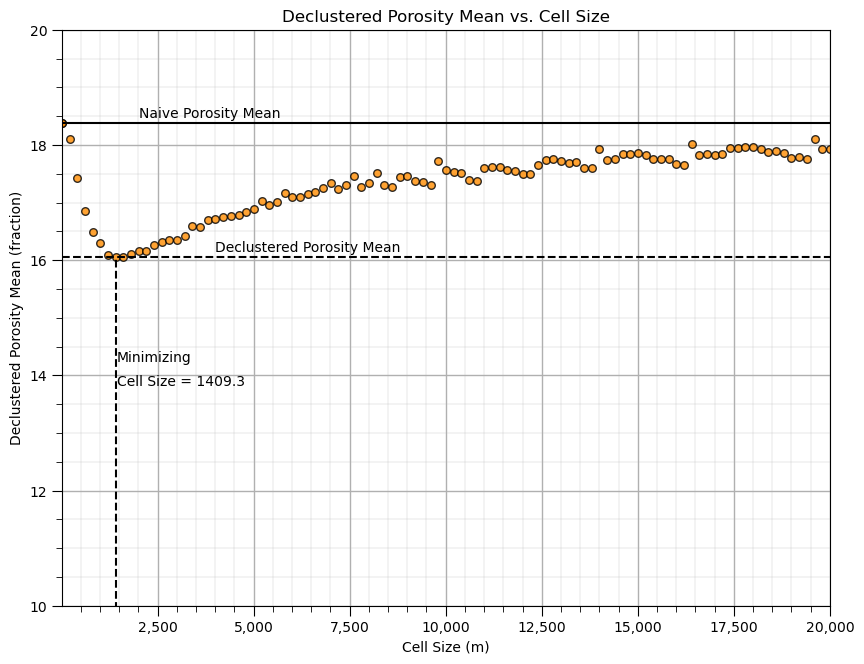
The cell size that minimizes the declustered mean is about 200m (estimated from the figure). This makes sense given our previous observation of the data spacing.
Calculating Declustered Statistics#
There are methods available to calculate weighted means, histograms and CDFs. We can always calculate weighted statistics manually.
Weighted Variance
Weighted Variance
Weighted Standard Deviation
A convenient way to do this is with the StatsModels’ DescrStatsW object that adds the weights to the data (1D or 2D) and then provides member functions for weighted statistics.
weighted_data = DescrStatsW(df['Por'].values, weights=df['Wts'], ddof=0)
print('Declustered, Weighted Statistics:')
print(' Mean: ' + str(round(weighted_data.mean,3)))
print(' Standard Deviation: ' + str(round(weighted_data.std,3)))
print(' Variance: ' + str(round(weighted_data.var,5)))
Declustered, Weighted Statistics:
Mean: 16.059
Standard Deviation: 3.862
Variance: 14.91566
About the Author#

Michael Pyrcz is a professor in the Cockrell School of Engineering, and the Jackson School of Geosciences, at The University of Texas at Austin, where he researches and teaches subsurface, spatial data analytics, geostatistics, and machine learning. Michael is also,
the principal investigator of the Energy Analytics freshmen research initiative and a core faculty in the Machine Learn Laboratory in the College of Natural Sciences, The University of Texas at Austin
an associate editor for Computers and Geosciences, and a board member for Mathematical Geosciences, the International Association for Mathematical Geosciences.
Michael has written over 70 peer-reviewed publications, a Python package for spatial data analytics, co-authored a textbook on spatial data analytics, Geostatistical Reservoir Modeling and author of two recently released e-books, Applied Geostatistics in Python: a Hands-on Guide with GeostatsPy and Applied Machine Learning in Python: a Hands-on Guide with Code.
All of Michael’s university lectures are available on his YouTube Channel with links to 100s of Python interactive dashboards and well-documented workflows in over 40 repositories on his GitHub account, to support any interested students and working professionals with evergreen content. To find out more about Michael’s work and shared educational resources visit his Website.
Want to Work Together?#
I hope this content is helpful to those that want to learn more about subsurface modeling, data analytics and machine learning. Students and working professionals are welcome to participate.
Want to invite me to visit your company for training, mentoring, project review, workflow design and / or consulting? I’d be happy to drop by and work with you!
Interested in partnering, supporting my graduate student research or my Subsurface Data Analytics and Machine Learning consortium (co-PI is Professor John Foster)? My research combines data analytics, stochastic modeling and machine learning theory with practice to develop novel methods and workflows to add value. We are solving challenging subsurface problems!
I can be reached at mpyrcz@austin.utexas.edu.
I’m always happy to discuss,
Michael
Michael Pyrcz, Ph.D., P.Eng. Professor, Cockrell School of Engineering and The Jackson School of Geosciences, The University of Texas at Austin
More Resources Available at: Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Comments#
This was a basic demonstration of spatial data declustering for representative statistics. Much more can be done, I have other demonstrations for modeling workflows with GeostatsPy in the GitHub repository GeostatsPy_Demos.
I hope this is helpful,
Michael