

Plotting Spatial Data and Models#
Michael J. Pyrcz, Professor, The University of Texas at Austin
Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Chapter of e-book “Applied Geostatistics in Python: a Hands-on Guide with GeostatsPy”.
Cite this e-Book as:
Pyrcz, M.J., 2024, Applied Geostatistics in Python: a Hands-on Guide with GeostatsPy [e-book]. Zenodo. doi:10.5281/zenodo.15169133 ![]()
The workflows in this book and more are available here:
Cite the GeostatsPyDemos GitHub Repository as:
Pyrcz, M.J., 2024, GeostatsPyDemos: GeostatsPy Python Package for Spatial Data Analytics and Geostatistics Demonstration Workflows Repository (0.0.1) [Software]. Zenodo. doi:10.5281/zenodo.12667036. GitHub Repository: GeostatsGuy/GeostatsPyDemos ![]()
By Michael J. Pyrcz
© Copyright 2024.
This is a tutorial for / demonstration of Visualizing Spatial Data with GeostatsPy, including,
location maps for plotting tabular spatial data, data points in space with one or more features
pixel plots for plotting gridded, exhaustive spatial data and models with one or more features
YouTube Lecture: check out my lecture on Displaying Data, see the first part of this larger lecture on univariate distributions.
Load the Required Libraries#
The following code loads the required libraries.
import geostatspy.GSLIB as GSLIB # GSLIB utilities, visualization and wrapper
import geostatspy.geostats as geostats # GSLIB methods convert to Python
import geostatspy
print('GeostatsPy version: ' + str(geostatspy.__version__))
GeostatsPy version: 0.0.71
We will also need some standard packages. These should have been installed with Anaconda 3.
import os # set working directory, run executables
from tqdm import tqdm # suppress the status bar
from functools import partialmethod
tqdm.__init__ = partialmethod(tqdm.__init__, disable=True)
ignore_warnings = True # ignore warnings?
import numpy as np # ndarrays for gridded data
import pandas as pd # DataFrames for tabular data
import matplotlib.pyplot as plt # for plotting
import matplotlib as mpl # custom colorbar
from matplotlib.ticker import (MultipleLocator, AutoMinorLocator) # control of axes ticks
plt.rc('axes', axisbelow=True) # plot all grids below the plot elements
if ignore_warnings == True:
import warnings
warnings.filterwarnings('ignore')
cmap = plt.cm.inferno # color map
Define Functions#
This is a convenience function to add major and minor gridlines to improve plot interpretability.
def add_grid():
plt.gca().grid(True, which='major',linewidth = 1.0); plt.gca().grid(True, which='minor',linewidth = 0.2) # add y grids
plt.gca().tick_params(which='major',length=7); plt.gca().tick_params(which='minor', length=4)
plt.gca().xaxis.set_minor_locator(AutoMinorLocator()); plt.gca().yaxis.set_minor_locator(AutoMinorLocator()) # turn on minor ticks
Make Custom Colorbar#
We make this colorbar to display our categorical, sand and shale facies.
cmap_facies = mpl.colors.ListedColormap(['grey','gold'])
cmap_facies.set_over('white'); cmap_facies.set_under('white')
Set the Working Directory#
I always like to do this so I don’t lose files and to simplify subsequent read and writes (avoid including the full address each time).
#os.chdir("c:/PGE383") # set the working directory
Loading Tabular Data#
Here’s the command to load our comma delimited data file in to a Pandas’ DataFrame object.
note the “fraction_data” variable is an option to random take part of the data (i.e., 1.0 is all data).
this is not standard part of spatial estimation, but fewer data is easier to visualize given our grid size (we want multiple cells between the data to see the behavior away from data)
note, I often remove unnecessary data table columns. This clarifies workflows and reduces the chance of blunders, e.g., using the wrong column!
fraction_data = 1.0 # extract a fraction of data for demonstration / faster runs, set to 1.0 for homework
df = pd.read_csv(r"https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/spatial_nonlinear_MV_facies_v13.csv") # load the data from Dr. Pyrcz's GitHub repository
if fraction_data < 1.0:
df = df.sample(frac = fraction_data,replace = False,random_state = 73073) # random sample from the dataset
df = df.reset_index() # reorder the data index
df = df.iloc[:,2:8] # remove the unneeded features, columns
df.head() # preview the DataFrame
| X | Y | Por | Perm | AI | Facies | |
|---|---|---|---|---|---|---|
| 0 | 180.0 | 769.0 | 13.770949 | 446.436677 | 3445.418690 | 1.0 |
| 1 | 530.0 | 259.0 | 13.974270 | 216.593948 | 3159.935063 | 1.0 |
| 2 | 470.0 | 139.0 | 6.031127 | 0.000000 | 5799.299877 | 0.0 |
| 3 | 250.0 | 179.0 | 5.158305 | 129.285485 | 5656.422332 | 0.0 |
| 4 | 960.0 | 169.0 | 5.553232 | 370.191342 | 6354.235120 | 0.0 |
Summary Statistics#
Let’s look at summary statistics for all facies combined:
df.describe().transpose()
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| X | 720.0 | 479.395833 | 289.337554 | 0.000000 | 225.000000 | 460.000000 | 730.000000 | 990.000000 |
| Y | 720.0 | 525.572222 | 268.797902 | 9.000000 | 325.000000 | 525.000000 | 749.000000 | 999.000000 |
| Por | 720.0 | 13.154504 | 4.921139 | 3.113721 | 8.140312 | 14.192083 | 16.852002 | 22.801310 |
| Perm | 720.0 | 462.242089 | 325.040727 | 0.000000 | 195.268277 | 453.089288 | 704.256901 | 1525.989345 |
| AI | 720.0 | 3915.972800 | 1292.243819 | 2555.187875 | 2974.530389 | 3224.863572 | 5381.452060 | 7400.229415 |
| Facies | 720.0 | 0.691667 | 0.462126 | 0.000000 | 0.000000 | 1.000000 | 1.000000 | 1.000000 |
Specify the Area of Interest / Grid and Feature Limits#
Let’s specify a reasonable extents for our grid and features:
we do this so we have consistent plots for comparison.
we design a grid that balances detail and computation time. Note kriging computation complexity scales \(O(n_{cell})\)
so if we half the cell size we have 4 times more grid cells in 2D, 4 times the runtime
We could use commands like this one to find the minimum value of a feature:
df['Porosity'].min()
But, it is natural to set the ranges manually. e.g. do you want your color bar to go from 0.05887 to 0.24230 exactly?
Also, let’s pick a color map for display.
I heard that plasma is known to be friendly to the color blind as the color and intensity vary together (hope I got that right, it was an interesting Twitter conversation started by Matt Hall from Agile if I recall correctly).
xmin = 0.0; xmax = 1000.0 # range of x values
ymin = 0.0; ymax = 1000.0 # range of y values
pormin = 0.02; pormax = 23.0; # range of porosity values
cmap = plt.cm.inferno # color map
Visualizing Tabular Data#
Let’s try out locmap. This is a reimplementation of GSLIB’s locmap program that uses matplotlib. I hope you find it simpler than matplotlib, if you want to get more advanced and build custom plots lock at the source. If you improve it, send me the new code. Any help is appreciated. To see the parameters, just type the command name:
GSLIB.locmap # GeostatsPy's location map function
<function geostatspy.GSLIB.locmap(df, xcol, ycol, vcol, xmin, xmax, ymin, ymax, vmin, vmax, title, xlabel, ylabel, vlabel, cmap, fig_name)>
Let’s add the plotting parameters.
GSLIB.locmap_st(df,'X','Y','Por',xmin,xmax,ymin,ymax,0.0,30.0,'Well Data - Porosity','X(m)','Y(m)',
'Porosity (fraction)',cmap)
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.1, hspace=0.2); plt.show()
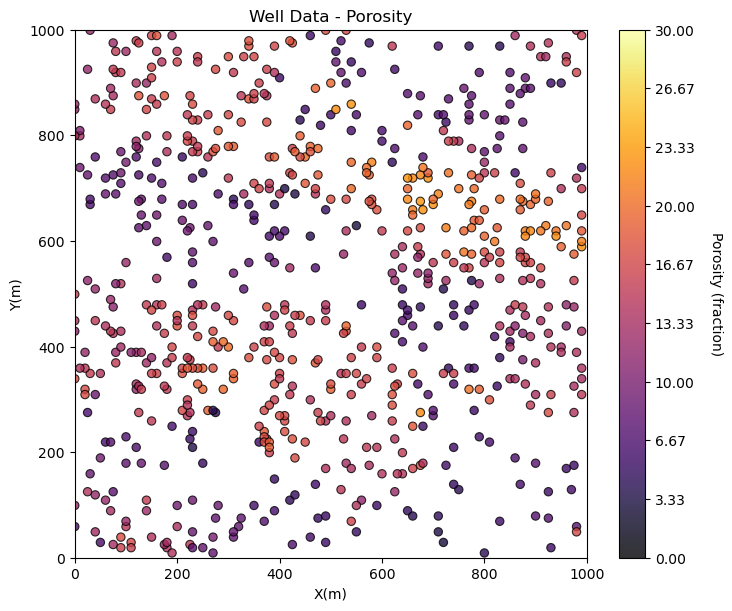
Maybe we can tighten up the color bar to see more details? and add some gridlines?
we craft our data and model plots to best communicate to our audience. It’s fun to make great data and model plots!
GSLIB.locmap_st(df,'X','Y','Por',xmin,xmax,ymin,ymax,pormin,pormax,'Well Data - Porosity','X(m)','Y(m)','Porosity (fraction)',cmap); add_grid()
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.1, hspace=0.2)
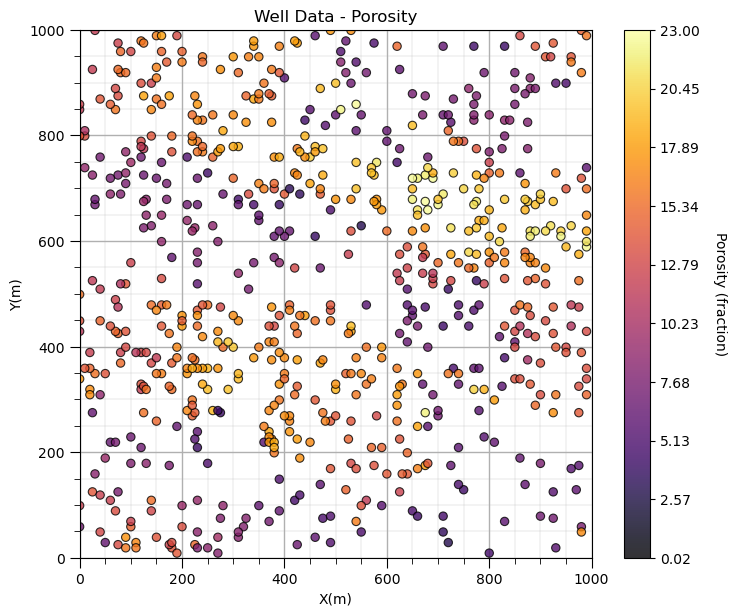
The new colorbar extents improves the resolution of spatial details for our property.
We will need ranges for the other variables. I’ll pick some:
xmin = 0.0; xmax = 1000.0 # range of x values
permmin = 0.01; permmax = 1000; # range for permeability
AImin = 1000.0; AImax = 8000 # range for facies
Fmin = 0; Fmax = 1 # range for acoustic impedance
Let’s add the other properties into a composite figure with all the plots as subplots.
To do this we use the subplot command, in matplotlib package to prior to the figure command to indicate that the following figure is part of a subplot and we use subplots_adjust at the end to get the scaling right.
We can save our fancy figure to an image file with the file format and resolution that we need.
This is great for writing reports, papers and making great looking update presentations.
Note, in GeostatsPy, I provide additional plotting methods with and without ‘_st’ in the name.
with ‘_st’ functions to ‘stack’ images in a composite figure.
without ‘_st’ functions to produce a single image and simultaneously make a file
We can also just make a file after we make our composite plot, see below.
save_to_file = False # save composite image to a file?
plt.subplot(221)
GSLIB.locmap_st(df,'X','Y','Facies',xmin,xmax,ymin,ymax,Fmin,Fmax,'Well Data - Facies','X(m)','Y(m)',
'Sand (1), Shale (0)',cmap_facies); add_grid()
plt.subplot(222)
GSLIB.locmap_st(df,'X','Y','Por',xmin,xmax,ymin,ymax,pormin,pormax,'Well Data - Porosity','X(m)','Y(m)',
'Porosity (fraction)',cmap); add_grid()
plt.subplot(223)
GSLIB.locmap_st(df,'X','Y','Perm',xmin,xmax,ymin,ymax,permmin,permmax,'Well Data - Permeability','X(m)','Y(m)',
'Permeability (mD)',cmap); add_grid()
plt.subplot(224)
GSLIB.locmap_st(df,'X','Y','AI',xmin,xmax,ymin,ymax,AImin,AImax,'Well Data - Acoustic Impedance','X(m)','Y(m)',
'Acoustic Impedance (kg/m2s*10^6)',cmap); add_grid()
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=2.1, wspace=0.2, hspace=0.2)
if save_to_file == True: # make a figure file
plt.savefig('All_location_maps.tif',dpi=600,bbox_inches="tight")
plt.show()
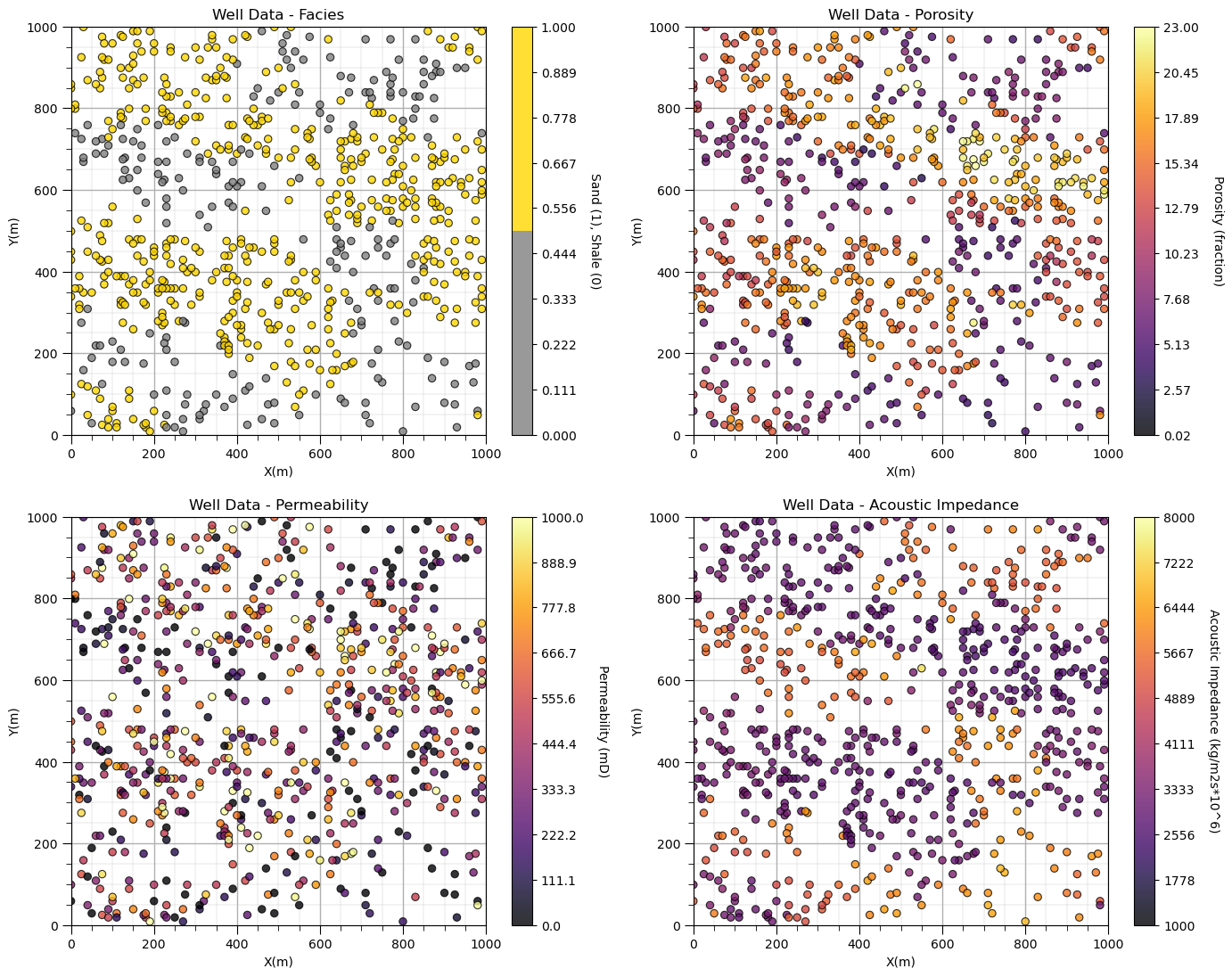
Looks pretty good, eh? (yes, I am Canadian).
Did you notice the custom color map for facies? We could actually update the tick marks on the colorbar, but for brevity let’s leave it as is for now.
Feature Engineering#
I want to demonstrate saving our data back to a file, i.e., close the loop since I already showed how to load the data from a file.
It would be boring to just save the same data that we loaded. So let’s quickly do a little feature engineering.
permeability divided by porosity is a common engineered feature that is applied to heterogeneity measures like coefficient of variation (dispersion-based measure) and to sort samples for calculating Lorence coefficients.
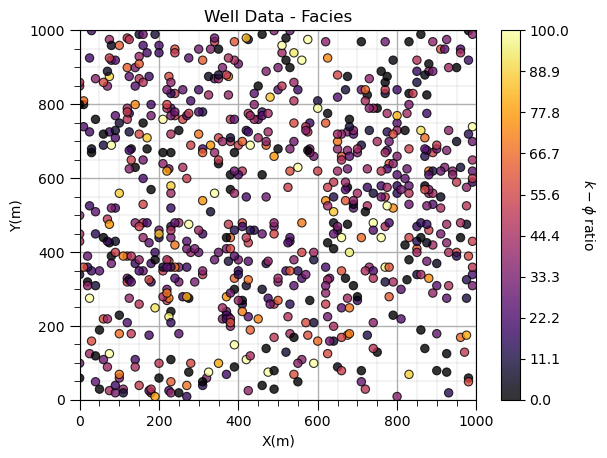
Let’s calculate and plot the permeability-porosity ratio.
df['PermPor'] = df['Perm']/df['Por']
plt.subplot(111)
GSLIB.locmap_st(df,'X','Y','PermPor',xmin,xmax,ymin,ymax,0.0,100.0,'Well Data - Facies','X(m)','Y(m)',
r'$k-\phi$ ratio',cmap); add_grid()
Saving Tabular Data#
Now we will save the updated DataFrame in multiple formats.
.csv file - comma delimited file, the original format loaded above so easy to load to a DataFrame and can be directly loaded into Excel. Note, the ‘to_csv’ function defaults to prepend the index column. This may be dangerous in your workflow as an unexpected column is added during the save.
.xlsx file - Excel spreadsheet file, Excel is everywhere and all can use it. Sometimes I use Excel to reach a broader audience!
.json file - JavaScript Object Notification file, readable text-based format for data interchange, commonly used for transmitting data, e.g., web APIs.
.html file - HyperText Markup Language, the standard for building websites.
.pkl file - pickle for serializing Python objects into a byte stream (pickling) and restoring the objects (unpickling), files are in binary for high efficiency.
output_type = 1 # select the output type for the DataFrame
if output_type == 1:
df.to_csv('spatial_nonlinear_MV_facies_v13_UPDATED.csv', index = False)
elif output_type == 2:
df.to_excel('spatial_nonlinear_MV_facies_v13_UPDATED.xlsx', sheet_name='Sheet1', index=False)
elif output_type == 3:
df.to_json('spatial_nonlinear_MV_facies_v13_UPDATED.json', orient='index')
elif output_type == 4:
df.to_html('spatial_nonlinear_MV_facies_v13_UPDATED.html')
elif output_type == 5:
df.to_pickle('spatial_nonlinear_MV_facies_v13_UPDATED.pkl')
Loading Gridded Data#
Let’s load and visualize the gridded, exhaustive seismic data set.
seismic = np.loadtxt("https://raw.githubusercontent.com/GeostatsGuy/GeoDataSets/master/spatial_nonlinear_MV_facies_v13_truth_AI.csv",
delimiter=",") # load the 2D csv file
Once again, no errors, a good sign. Let’s see what we loaded.
type(seismic) # check the type of the load object
numpy.ndarray
It is an NumPy ndarray - an array of values. Good!
Let’s get more specific. We can use the ‘type’ command to find out what any object is and we can use the shape member of ndarray to get the size of the array (ny, nx).
print('The object type is ' + str(type(seismic)))
print(' with size, ny = ' + str(seismic.shape[0]) + ' and nx = ' + str(seismic.shape[1])) # check the grid size
The object type is <class 'numpy.ndarray'>
with size, ny = 100 and nx = 100
Visualizing Gridded Data#
We have a 100 cells in y and 100 cells in x grid but we need more information.
What is the origin, units, orientation and the cell size?
This file format does not include that information so I’ll give it to you.
cell size is 10m isotropic (same in x and y)
grid goes from 0 to 1000m in x and y (origin is at 0,0)
grid orientation is aligned with x and y (Eastings and Northings, without any rotation).
We need to add the grid cell size, because we already have the grid extents (xmin, xmax, ymin and ymax) above.
csize = 10.0 # grid cell size
We will use the pixelplt command reimplemented form GSLIB. To see the parameters type the name and run.
GSLIB.pixelplt # GeostatsPy's pixel plot function
<function geostatspy.GSLIB.pixelplt(array, xmin, xmax, ymin, ymax, step, vmin, vmax, title, xlabel, ylabel, vlabel, cmap, fig_name)>
GSLIB.pixelplt_st(seismic,xmin,xmax,ymin,ymax,csize,AImin,AImax,'Acoustic Impedance','X(m)','Y(m)',
'Acoustic Impedance (kg/m2s*10^6)',cmap); plt.show() # plot the seismic data
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.2, hspace=0.2); plt.show()
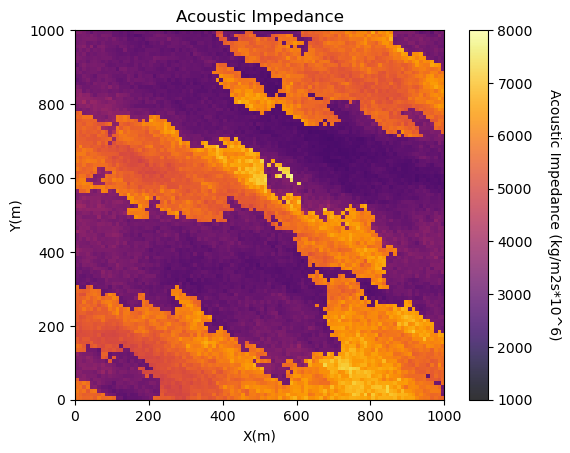
<Figure size 640x480 with 0 Axes>
Interesting, there are a lot of local variations in our subsurface unit in acoustic impedance. If acoustic impedance is well correlated to petrophysical properties then there is a lot of good information here.
Visualizing Tabular and Gridded Data Together#
You may be concerned about the consistency between the tabular acoustic impedance samples and the gridded acoustic impedance.
It is a good check to plot them together.
GeostatsPy’s locpix is a function to plot tabular and gridded data together.
GSLIB.locpix_st # GeostatsPy's combined tabular and gridded data plot
<function geostatspy.GSLIB.locpix_st(array, xmin, xmax, ymin, ymax, step, vmin, vmax, df, xcol, ycol, vcol, title, xlabel, ylabel, vlabel, cmap)>
GSLIB.locpix_st(seismic,xmin,xmax,ymin,ymax,csize,AImin,AImax,df,'X','Y','AI','Acoustic Impedance','X(m)','Y(m)',
'Acoustic Impedance (kg/m2s*10^6)',cmap); plt.show()
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.2, hspace=0.2); plt.show()

<Figure size 640x480 with 0 Axes>
Saving Gridded Data#
Now we will save the updated DataFrame in multiple formats.
.csv file - comma delimited file, the original format loaded above so easy to load to a DataFrame and can be directly loaded into Excel.
.npy file - NumPy format, binary for efficient storage while retaining array parameters, i.e., shape and data type
output_type = 1 # select the output type for the DataFrame
if output_type == 1:
np.savetxt('spatial_nonlinear_MV_facies_v13_truth_AI.csv',seismic,delimiter=',',fmt='%f')
if output_type == 2:
np.save('spatial_nonlinear_MV_facies_v13_truth_AI.npy',seismic)
Other Ideas for Interrogating Spatial Data#
Looks good. There is so much more that we can do to display our spatial data to learn form it. For example, what if we want to separate low and high porosity?
Try this, make a new property in the DataFrame with 0 for low porosity and 1 for high porosity and plot it. This is a continuous indicator transformation.
por_thresh = 12.0
df['cat_por'] = np.where(df['Por']>=por_thresh,1.0,0.0) # binary category assignment, 1 if > 12%, 0 otherwise
plt.subplot(111)
GSLIB.locmap_st(df,'X','Y','cat_por',xmin,xmax,ymin,ymax,0.0,1.0,
'Well Data - Indicator {Porosity < 12%}','X(m)','Y(m)','Porosity (indicator)',cmap=plt.cm.Greys)
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.2, hspace=0.2); plt.show()
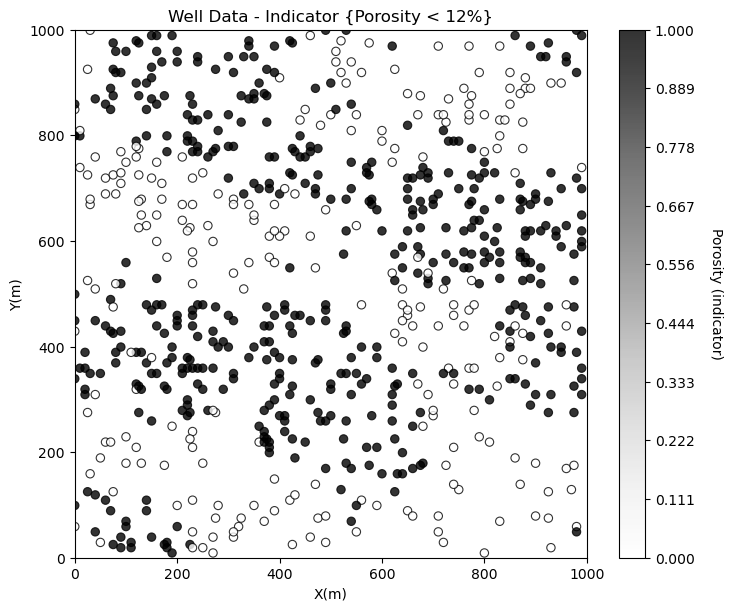
Now let’s build an improved custom plot.
import matplotlib.patches as patches
plt.subplot(121)
GSLIB.locmap_st(df,'X','Y','Por',xmin,xmax,ymin,ymax,pormin,pormax,'Well Data - Porosity','X(m)','Y(m)',
'Porosity (fraction)',cmap); add_grid()
plt.subplot(122)
plt.scatter(df['X'],df['Y'],c=df['cat_por'],s=30,edgecolor='black',cmap=plt.cm.Greys,vmin=0.0,vmax=1.8)
plt.xlim([0,1000]); plt.ylim([0,1000]); add_grid(); plt.xlabel('X (m)'); plt.ylabel('Y (m)'); plt.title('Indicator Transform of Porosity')
rect = patches.Rectangle((740, 10), 255, 100, linewidth=1, edgecolor='black', facecolor='white', alpha=0.8,zorder=10)
plt.gca().add_patch(rect)
plt.annotate(r'Porosity > ' + str(por_thresh) + '%',[780,70],zorder=20)
plt.annotate(r'Porosity ≤ ' + str(por_thresh) + '%',[780,20],zorder=20)
plt.scatter([760,760],[80,30],color=['darkgrey','white'],edgecolor='black',zorder=20)
plt.subplots_adjust(left=0.0, bottom=0.0, right=2.0, top=1.1, wspace=0.2, hspace=0.2); plt.show()
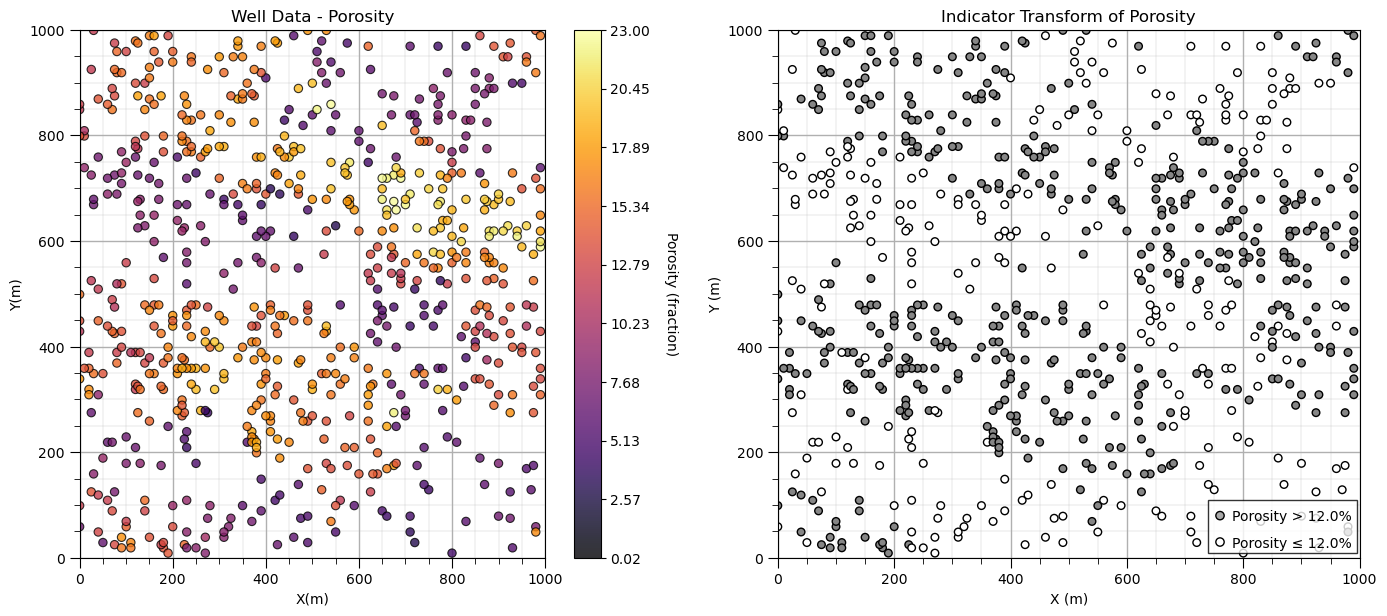
Now let’s show both porosity and permeability on the same plot!
plt.subplot(111)
im = plt.scatter(df['X'],df['Y'],c=df['Por'],s=90,edgecolor='black',zorder=1,vmin=pormin,vmax=pormax,cmap=cmap)
plt.scatter(df['X'],df['Y'],c=df['Perm'],s=30,edgecolor='black',zorder=10,vmin=permmin,vmax=permmax,cmap=cmap)
cbar = plt.colorbar(im, orientation="vertical", ticks=np.linspace(pormin, pormax, 10))
cbar.set_label('Porosity (%) (outside)/ Permeability (mD) (inside)', rotation=270, labelpad=20)
cbar.set_ticklabels(np.char.add(np.char.add(np.round(np.linspace(pormin, pormax, 10)).astype(int).astype(str), ' / '),
np.round(np.linspace(permmin, permmax, 10)).astype(int).astype(str)))
plt.xlim([0, 1000]); plt.ylim([0, 1000]); add_grid()
plt.xlabel('X (m)'); plt.ylabel('Y (m)'); plt.title('Porosity and Permeability Combined Location Map')
# Display the plot
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.1, wspace=0.2, hspace=0.2); plt.show()
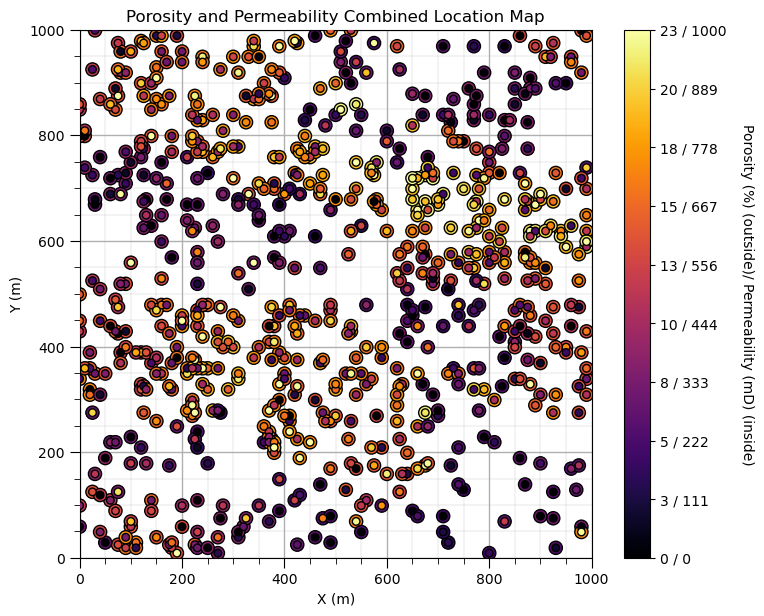
This plot shows the spatial variations in porosity and permeability together.
with data plotting we are working to communicate data patterns limited only by our imagination
About the Author#

Michael Pyrcz is a professor in the Cockrell School of Engineering, and the Jackson School of Geosciences, at The University of Texas at Austin, where he researches and teaches subsurface, spatial data analytics, geostatistics, and machine learning. Michael is also,
the principal investigator of the Energy Analytics freshmen research initiative and a core faculty in the Machine Learn Laboratory in the College of Natural Sciences, The University of Texas at Austin
an associate editor for Computers and Geosciences, and a board member for Mathematical Geosciences, the International Association for Mathematical Geosciences.
Michael has written over 70 peer-reviewed publications, a Python package for spatial data analytics, co-authored a textbook on spatial data analytics, Geostatistical Reservoir Modeling and author of two recently released e-books, Applied Geostatistics in Python: a Hands-on Guide with GeostatsPy and Applied Machine Learning in Python: a Hands-on Guide with Code.
All of Michael’s university lectures are available on his YouTube Channel with links to 100s of Python interactive dashboards and well-documented workflows in over 40 repositories on his GitHub account, to support any interested students and working professionals with evergreen content. To find out more about Michael’s work and shared educational resources visit his Website.
Want to Work Together?#
I hope this content is helpful to those that want to learn more about subsurface modeling, data analytics and machine learning. Students and working professionals are welcome to participate.
Want to invite me to visit your company for training, mentoring, project review, workflow design and / or consulting? I’d be happy to drop by and work with you!
Interested in partnering, supporting my graduate student research or my Subsurface Data Analytics and Machine Learning consortium (co-PI is Professor John Foster)? My research combines data analytics, stochastic modeling and machine learning theory with practice to develop novel methods and workflows to add value. We are solving challenging subsurface problems!
I can be reached at mpyrcz@austin.utexas.edu.
I’m always happy to discuss,
Michael
Michael Pyrcz, Ph.D., P.Eng. Professor, Cockrell School of Engineering and The Jackson School of Geosciences, The University of Texas at Austin
More Resources Available at: Twitter | GitHub | Website | GoogleScholar | Geostatistics Book | YouTube | Applied Geostats in Python e-book | Applied Machine Learning in Python e-book | LinkedIn
Comments#
This was a basic demonstration of plotting spatial data with GeostatsPy. Much more can be done, I have other demonstrations for modeling workflows with GeostatsPy in the GitHub repository GeostatsPy_Demos.
I hope this is helpful,
Michael